Storage / Amazon CloudFront
Storage
- 클라우드 컴퓨팅 제공 업체를 통해 데이터와 파일을 인터넷에 저장할 수 있는 클라우드 컴퓨팅 모델
- 사용자가 퍼블릭 인터넷 또는 전용 프라이빗 네트워크 연결을 통해 엑세스할 수 있음
- 데이터 스토리지 인프라를 개인적으로 구매하고 관리할 필요 없이 언제 어디서나 데이터에 엑세스할 수 있음
클라우드 스토리지의 유형
- 객체 스토리지
: 사진, 동영상, 기계 학습(ML), 센서 데이터, 오디오 파일, 다른 유형의 웹 콘텐츠 등 갈수록 증가하는 비정형 데이터를 저장해야 함 -> 이러한 데이터를 저장할 확장 가능하고 효율적이며 경제적인 방법 / 비정형 데이터의 대규모 스토어를 구축하기 위한 데이터 스토리지- 전송된 형식 그대로를 객체 데이터로 저장
- 객체는 보안 버킷이라는 저장 공간에 저장
- 용량 데이터 볼륨을 저장하는 비용도 낮음
- Amazon S3
(전송된 형식 그대로를 객체로 저장. 다양한 데이터를 가지고 올 수 있기 때문에 정적 웹 컨텐츠에도 적절. 확장성이 좋고 비용이 저렴한 편.)
- 파일 스토리지
: 파일 기반 스토리지 또는 파일 스토리지는 애플리케이션에 널리 사용- 데이터를 계층형 폴더 및 파일 형식으로 저장
- 네트워크 환경에서의 파일 기반 스토리지는 NAS 기술 사용
- 네트워크 연결 스토리지(NAS): 직원들이 네트워크를 통해 효과적으로 협업할 수 있도록 데이터를 지속적으로 사용할 수 있게 하는 파일 전용 스토리지 디바이스
- 블록 스토리지
: 데이터베이스 또는 전사적 자원 관리(ERP) 시스템과 같은 엔터프라이즈 애플리케이션은 호스트별로 지연 시간이 짧은 전용 스토리지가 필요한 경우가 많음 -> 이를 위해 지연 시간이 짧고, 빠른 데이터 엑세스를 제공하는 스토리지- 데이터를 블록 형태로 저장하는 클라우드 스토리지 서비스
- 각 블록에는 빠른 저장 및 검색을 위한 고유한 식별자가 있음
- Amazon EBS
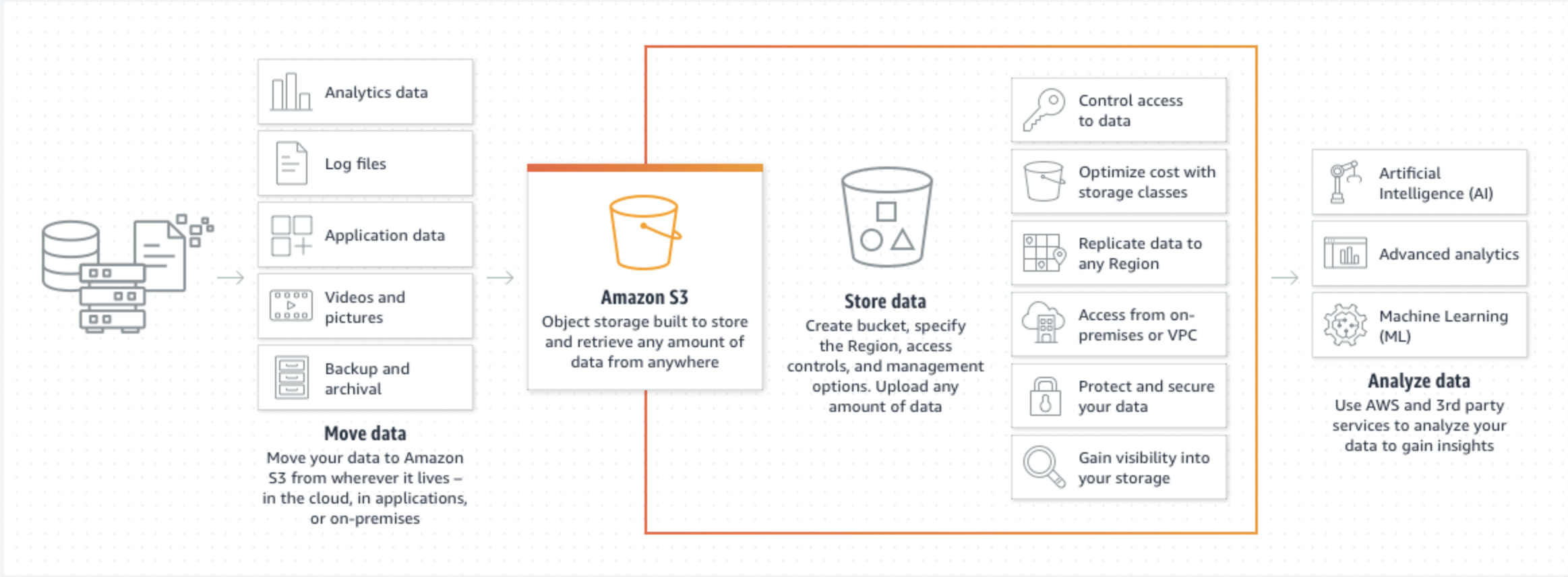
Amazon S3
: 데이터를 버킷 내 객체로 저장하는 객체 스토리지 서비스!
- 확장성, 데이터 보호, 비용 효율성
- 대량의 데이터를 안전하게 저장
- 비즈니스 요구에 맞게 데이터에 대한 접근 제어
- 버킷과 객체로 구성
버킷: 최상위 디렉토리
- 버킷에는 객체를 무제한으로 저장 가능
- 한 계정당 최대 100개의 버킷 생성 가능
- AWS 전역에서 단 하나만 존재 / 리전과 관계없이 전역적으로 유일한 이름 사용
객체: 디렉토리 내에 저장되는 파일
- 객체는 하나 이상의 버킷에 저장 / 각 객체의 크기는 최대 5TB
- 객체는 키와 버전 ID로 버킷 내에서 고유하게 식별
- 키: 객체에 할당한 이름 / 버킷 내 객체에 대한 고유한 식별자
- 버전 ID: 버킷에 객체를 추가할 때 Amazon S3가 생성하는 문자열
S3 내 모든 객체는 버킷+키+버전 조합으로 고유하게 식별 가능
- 메타데이터: 객체 관련 정보를 저장하기 위한 이름-값 페어 세트 / 사용자가 직접 지정 가능
- 값: 저장하는 콘텐츠
- 태그: 저장된 객체를 분류하기 위해 사용하는 정보
- 엑세스 제어 정보: 저장하는 객체에 대한 엑세스를 제어하기 위한 정보
보안 - 데이터 암호화
-- 서버측 암호화(SSE)
: 데이터를 받는 애플리케이션 혹은 서비스 서버가 해당 데이터를 암호화하는 것
- AWS 데이터 센터에서 객체 데이터 암호화
- 사용자 접근 시 자동으로 암호 해독하여 반환
-- 클라이언트측 암호화(SSE)
: 전송 및 저장 시 보안을 보장하기 위해 로컬에서 데이터를 암호화
- AWS를 포함한 제3자에게 객체가 노출되지 않음
- S3는 이미 암호화된 객체를 수신 / 객체를 암호화하거나 해독하는 역할을 하지 않음
- 높은 보안 보장하지만 관리 및 구현의 복잡성 증가
보안 - 엑세스 제어
-- 리소스 기반 정책
: S3 버킷과 같은 리소스에 연결하는 JSON 정책 문서
- 적절한 권한을 가진 사용자만 리소스에 대한 엑세스를 허용
- 리소스에 접근하기 위해 필요한 권한 정의
-- 자격 증명 기반 정책
: 자격 증명(사용자, 사용자 그룹, 역할)이 무슨 작업을 어느 리소스, 어느 조건에서 수행할 수 있는지를 제어하는 정책
- 다수의 사용자, 그룹, 역할에 정책을 연결하는 경우 '관리형 정책'
- 단일 사용자, 그룹, 역할에 1:1로 정책을 연결하는 경우 '인라인 정책'
- 사용자가 수행할 수 있는 작업 정의
-- CORS
: S3를 사용하여 정적 웹사이트를 호스팅하는 경우 CORS 구성을 통해 엑세스 제어
*CORS(Cross=Origin Resource Sharing): 웹 브라우저의 한 도메인이 다른 도메인의 리소스를 요청할 때 해당 리소스에 대한 엑세스를 선택적으로 허용
- 다른 도메인에서 S3 리소스에 대한 요청을 보내는 경우, 해당 요청 도메인에 대한 CORS 정책 구성 필요
-- Pre-Signed URLS
: 미리 서명된 URL을 사용하여 버킷 정책 업데이트 없이 객체 엑세스 허용 -> AWS 보안 자격 증명이나 권한이 없어도 작업 가능
- 미리 서명된 URL은 해당 URL을 생성하는 사용자의 권한에 따라 제한
스토리지 관리 - 버전 관리
: 한 버킷에 여러 버전의 객체를 보관 -> 실수로 삭제되거나 덮어써진 객체 복원 가능
- 버킷의 버전 관리를 활성화하면 저장되는 객체에 대해 고유한 버전 ID 자동 생성
- 한 번 활성화하면 비활성화 불가 (중단 상태로는 전환 가능)
스토리지 관리 - 객체 복제
: 객체 복제를 통해 하나 이상의 대상 버킷에 대한 객체를 동일하거나 다른 AWS 리전에 비동기적으로 자동 복제 가능
- S3 리전 간 복제(CRR): 서로 다른 리전 버킷에서 새 객체를 복제하는 경우
- S3 동일 리전 복제(SRR): 동일한 리전 버킷에서 새 객체를 복제하는 경우
- S3 배치 복제: 기존 객체를 온디맨드 옵션으로 다른 버킷에 복제하는 경우
스토리지 관리 - 클래스
: S3 버컷의 각 객체에는 그와 연결된 스토리지 클래스가 존재
-> 사용자는 사용 사례 및 요구 사항에 맞게 스토리지 클래스를 선택
- 자주 엑세스하고, 짧은 지연시간이 필요한 객체 스토리지 클래스
: S3 standard, S3 Express One Zone, Reduce Redundancy - 자주 엑세스하지 않는 객체 스토리지 클래스
: S3 standard-IA, S3 One Zone-IA - 객체 아카이빙을 위한 저비용 스토리지 클래스
: S3 Glacier
스토리지 관리 - 수명 주기
: 객체를 효율적으로 저장 및 관리하기 위해 S3 객체 그룹에 적용할 작업을 정의하는 수명 주기 구성
- 전환 작업: 객체가 다른 스토리지 클래스로 전환되는 시기 정의
- 만료 작업: 객체가 만료되는 시기 정의 / 객체가 만료되면 S3가 해당 객체 자동 삭제
Amazon CloudFront
: 짧은 대기 시간과 빠른 전송 속도로 최종 사용자에게 데이터, 동영상, 애플리케이션 및 API를 안전하게 전송하는 CDN(글로벌 콘텐츠 전송 네트워크) 서비스
- html, .css, .js 및 이미지 파일과 같은 정적 및 동적 웹 콘텐츠를 사용자에게 더 빨리 배포하도록 지원하는 웹 서비스
- CloudFront는 엣지 로케이션이라고 하는 데이터 센터의 전 세계 네트워크를 통해 콘텐츠를 제공
-CloudFront를 통해 서비스하는 콘텐츠를 사용자가 요청 -> 지연 시간이 가장 낮은 엣지 로케이션으로 요청이 라우팅되므로 가능한 최고의 성능으로 콘텐츠가 제공됨
*CDN(Content Delivery Network)
: 콘텐츠 전송 네트워크
- 지리적 제약 없이 전세계 사용자에게 빠르고 안전하게 콘텐츠를 전송할 수 있는 기능
- 웹사이트의 원래 서버와 달리 사용자에게 더 가까이에 있는 서버로부터 콘텐츠를 배포하는 방식
-
Edge Location
: 사용자에게 더 가까운 지리적 위치에 콘텐츠를 저장하는 데이터 센터 -
Regional Edge Caches(REC)
: 오리진과 엣지 로케이션 사이에 존재하는 캐시 계층
- 표준 엣지 로케이션에서 캐시하지 않는 콘텐츠를 저장
- 엣지 로케이션에서 캐시 미스가 발생했을 때(즉, 엣지 로케이션에 캐시가 없을 때), 오리진 서버 대신 리전 엣지 캐시로부터 콘텐츠를 검색하여 더 빠른 응답 시간을 제공
CloudFront 동작 방식
- 사용자 -> 어플리케이션에 요청
- DNS -> 사용자에게 적합한 Edge Location으로 라우팅
- Edge Location에서 캐시를 확인 (있다면 사용자에게 반환)
- Edge Location에 없으면 가장 가까운 REC로 캐시가 있는지 확인 요청
- REC에 없으면 CloudFront는 오리진 서버로 요청
- 오리진 > REC > Edge Location > CloudFront > 사용자 순서로 콘텐츠 제공
- REC에 캐시가 있다면 REC는 콘텐츠를 요청한 Edge Location으로 반환
- REC로부터 콘텐츠의 첫 번째 바이트가 도착하는 즉시 Edge Location은 이를 사용자에게 반환
- Edge Location은 나중을 위해 이 콘텐츠 캐시를 저장 (똑같은 요청이 들어오는 경우 리저널에 요청 보내지 않고 엣지 로케이션에서 반환할 수 있도록)
CloudFront Origin
*Origin: 데이터 원본이 위치한 곳
- 정적 콘텐츠 & 동적 콘텐츠 모두 처리
정적 콘텐츠: 서버(EC2)가 필요하지 않은 콘텐츠
동적 콘텐츠: 서버가 필요한 콘텐츠

{kind=link}