
개요
요즘 AI의 발전으로 점차 성능 좋은 임베딩 모델이 많아지고 있습니다.
임베딩 모델을 통해
Text, Image, Video 데이터를 벡터로 정형화하면
서로 다른 데이터 포멧 사이에서 검색이 가능하다는 장점이 있는데요.
또한,
벡터 검색은 기존 Keyword Exact 검색과는 달리
의미적 검색이 가능하다는 점도 강점 중 하나인 것 같습니다.
정확도가 높은 임베딩 모델일수록 Vector Dimension이 크기 때문에
효율적인 vector 검색을 위해서는 적절한 vector 저장 및 검색 방식을 선택해야 합니다.
Faiss
Faiss란 무엇인가
저는 vector 저장 및 검색 방식 중 하나인
Faiss를 소개해볼까 합니다.
Faiss란 Facebook AI Similarity Search를 줄인 말입니다.
이름에서 알 수 있듯이,
Facebook에서 개발한 라이브러리로
대량 고차원 벡터에서 벡터 similarity 검색 및 클러스터링을 빠르게 처리가능합니다.
Faiss 사용법
Faiss 사용법은 굉장히 간단합니다.
Faiss는 크게 Index와 Search로 구분할 수 있는데요.
Index는 벡터를 저장하는 공간,
Search는 index에서 vector search를 하는 것으로 이해하시면 될 것 같습니다.
Faiss는 cpu버전, gpu버전 모두 지원하고 있으며,
저는 cpu 버전으로 진행했습니다.
pip install faiss-cpu먼저 필요한 패키지를 install 해주시구요.
def create_random_index(n=1000000, dimension=128):
"""랜덤 인덱스 생성"""
embeddings = np.random.rand(n, dimension).astype(np.float32)
index = faiss.IndexFlatL2(dimension)
index.add(embeddings)
return index위에 함수를 실행하면 random index가 생성됩니다.
128차원 벡터 1,000,000개를 Index에 저장하는 코드입니다.
그 후 Index에서 search 메소드를 통해 vector 검색을 할 수 있습니다.
def search(index, query_vector, k=3):
query_vector = np.array(query_vector, dtype=np.float32)
query_vector = query_vector / np.linalg.norm(query_vector)
distances, indices = index.search(query_vector.reshape(1, -1), k)
return distances[0], indices[0]아래 코드를 실행하면
query_vector = np.random.rand(128).astype(np.float32)
index = create_random_index()
distances, indices = search(index, query_vector)
print(distances)
print(indices)distances: [6.328058 6.1224375 6.1192603]
indices: [842150 332656 858]
이와 같이 결과가 나옵니다
Faiss 벡터 검색
FAISS에서 L2 거리, Inner Product(IP) 두가지의 vector 유사도 측정 방식을 지원합니다.
1. L2 거리 (Euclidean Distance)
- 정의: L2 거리는 두 벡터 간의 유클리드 거리로 정의되며, 두 점 간의 직선 거리입니다.
- 사용 목적: 두 벡터간의 절대적인 거리 차이를 측정합니다. 주로 데이터 포인트 간의 구체적인 위치를 나타내는 데 사용됩니다.
- 특징: 두 벡터의 크기와 방향 모두에 의존하므로, 벡터 간의 절대적인 차이가 중요할 때 적합합니다.
2. Inner Product (IP)
- 정의: 두 벡터 간의 내적은 해당 벡터의 유사성을 측정하는 방법입니다.
- 사용 목적: 주로 벡터의 방향과 유사성을 측정하는 데 사용됩니다. 특정한 임베딩 공간에서 두 벡터가 얼마나 비슷하게 나란히 있는지를 확인할 때 유용합니다.
- 특징: 두 벡터의 크기 조정에 덜 민감하므로, 주로 방향적인 유사성을 평가하는데 적합합니다.
IP 사용을 원하시면
IndexFlatIP 메소드를 사용해 index를 만들어주면 됩니다.
def create_random_index(n=1000000, dimension=128):
"""랜덤 인덱스 생성"""
embeddings = np.random.rand(n, dimension).astype(np.float32)
# 정규화
embeddings = embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
# IP 사용해 index 만들기
index = faiss.IndexFlatIP(dimension)
index.add(embeddings)
return index그 후 검색을 해보면
distances: [0.85759556 0.8527152 0.8502388 ]
indices: [237760 940769 923805]
와 같은 결과를 얻을 수 있습니다.
IP는 크기보다는 방향의 유사성을 구하는 것이기 때문에
index에 넣어주기 전 정규화를 진행해주는 것이 좋습니다.
그러면 distance 결과값이 [0,1] 사이로 나오게 됩니다 (=cosine similarity)
Faiss 검색 속도 비교
Faiss 실제 vector 유사도 검색 속도는 어떨까요?
저는 Clip을 사용해 데이터를 512차원으로 저장하고,
테스트를 해보았습니다.
데이터 개수 500개일 때
pytorch
0.01초
Faiss
0.01초
데이터 개수 50,000개일 때
pytorch
0.49초
Faiss
0.01초
➡️ 데이터가 많아질수록 Faiss 검색이 휠씬 빠른 것으로 확인되었습니다.
검색 정확도 체크
그렇다면 Faiss의 검색 정확도는 어떨까요?
trade precision for speed, ie. give an incorrect result 10% of the time with a method that's 10x faster or uses 10x less memory
Faiss는 정확도를 10% 낮춘 대신 10배 더 빠르고 메모리 효율적인 특징을 가지고 있는데요.
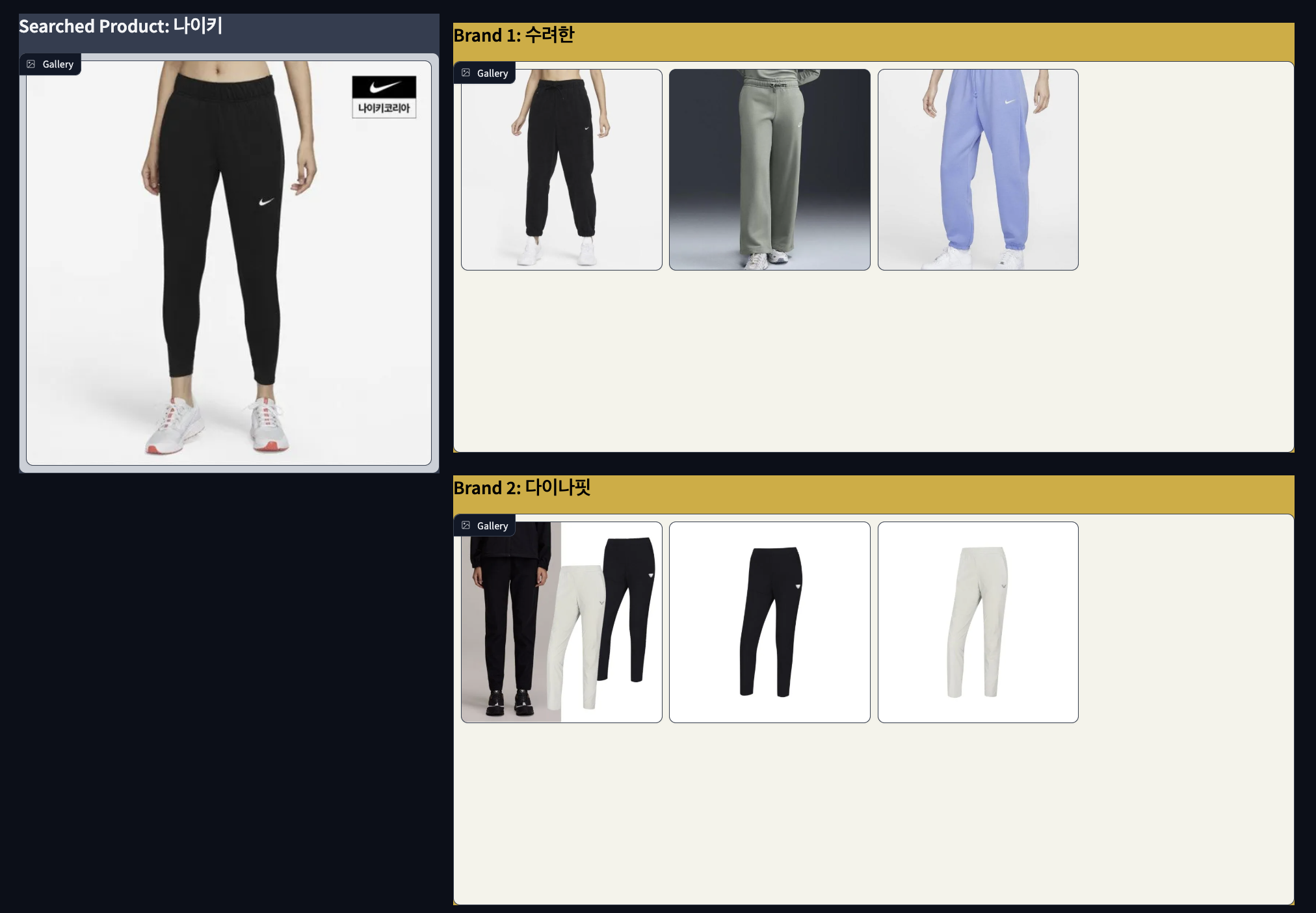
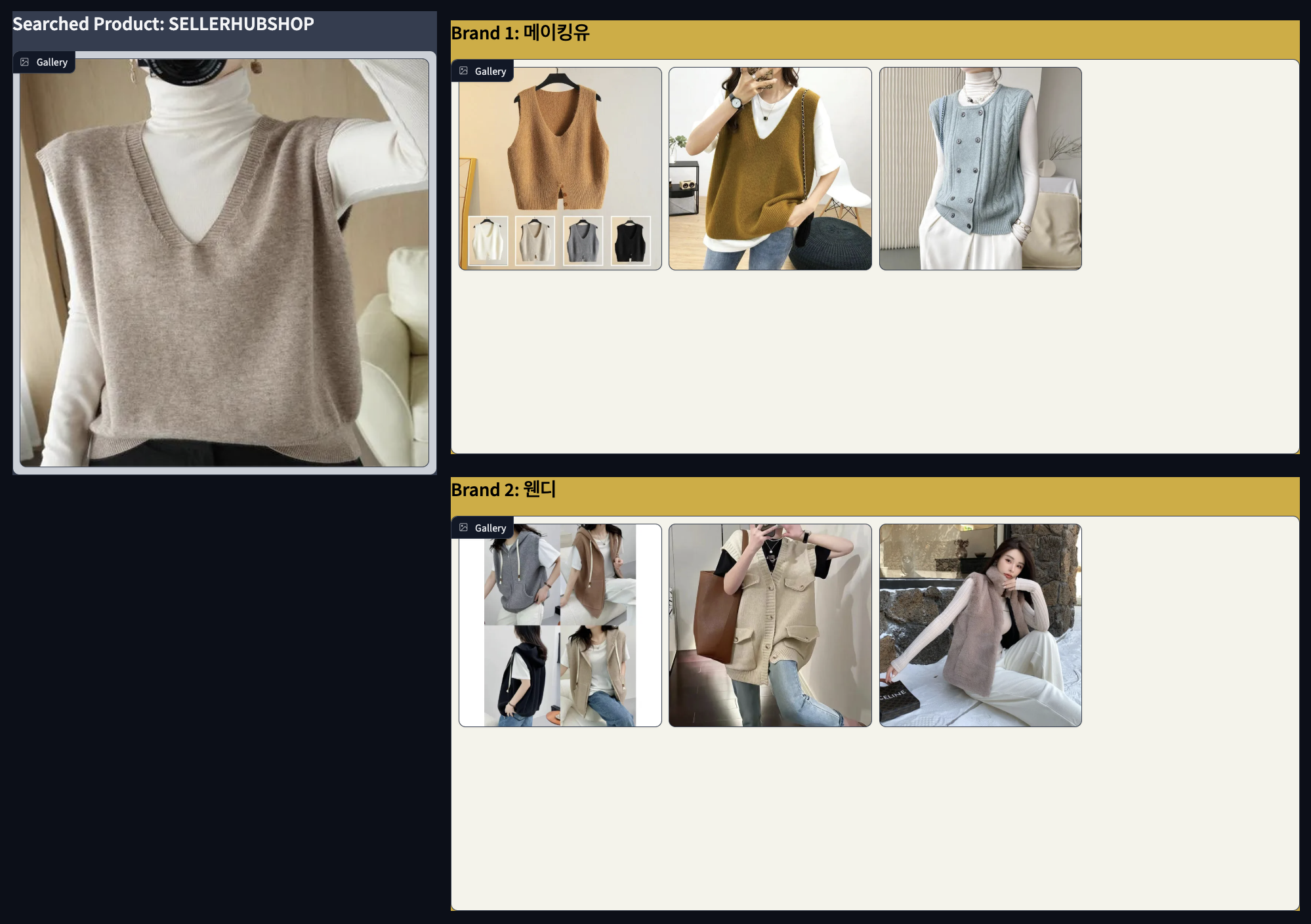
아래는 Faiss 검색을 통해
각 브랜드에서 왼쪽 사진과 가장 유사한 제품 3개씩 뽑아낸 결과입니다.
왼쪽 사진의 이미지 벡터(512차원)을 query vector로 사용하여
검색을 진행했는데요.
결과1
결과2
결과3

➡️ 저는 결과가 괜찮게 나왔다고 생각합니다.
오른쪽 검색 결과들을 왼쪽 사진과 비교했을 때 느낌이나 세부 카테고리가 비슷한 것 같습니다.
요약
Faiss 용도
- 대용량 벡터 처리를 원할 때
- 대용량 벡터에 대한 빠른 처리를 원할 때
- 별도 필터링 작업 없이 유사도 검색 혹은 클러스터링을 원할 때
평가
- 편의성 5/5
- 속도 5/5
