K-폴드 교차 검증에서 K의 값을 선택할 때 고려해야 할 점은 무엇인가요?
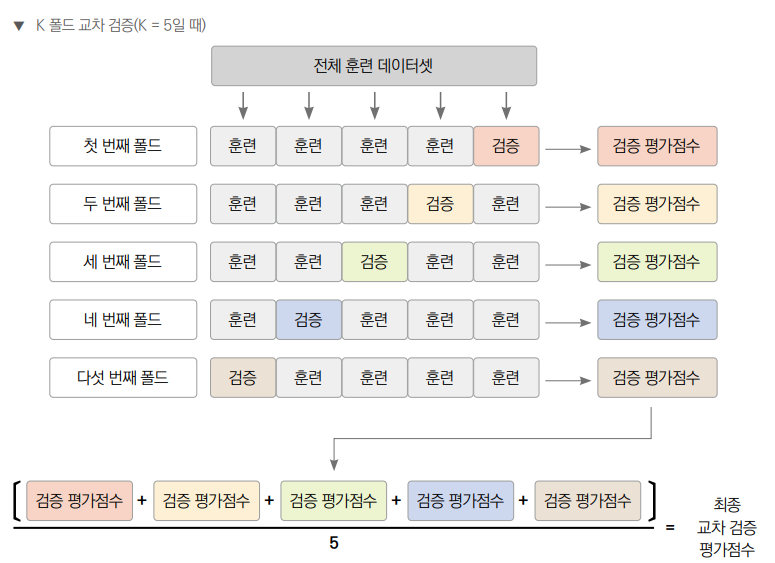
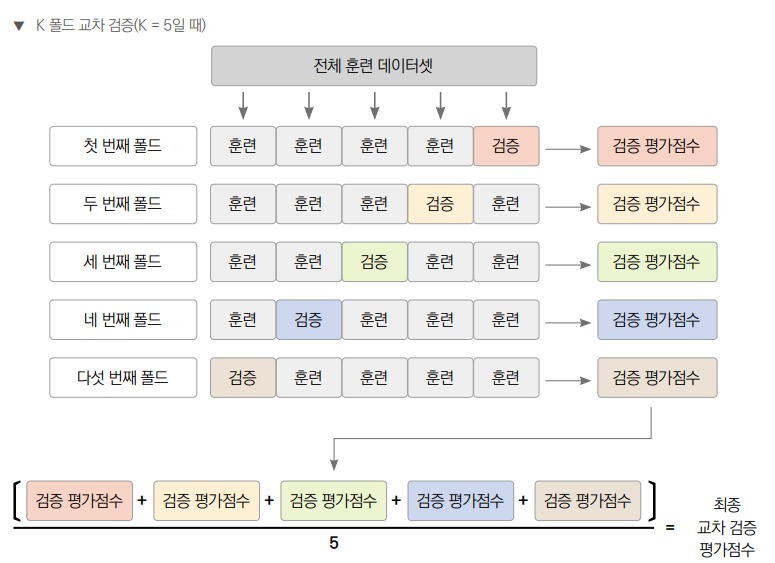
K-폴드 교차 검증
보통 머신러닝 모델을 학습시키기 위해서는 데이터를 훈련(train), 검증(validation), 테스트(test)의 3등분으로 나눈다. 여기에서 훈련과 검증 단계에 K-폴드 교차 검증이 사용된다.
우선 데이터를 K개의 폴드로 나눈 뒤에 K−1개의 폴드를 훈련 데이터로 사용하고, 나머지 1개의 폴드를 검증 데이터로 사용한다. K 값은 교차 검증 결과의 신뢰성과 모델 학습 성능에 영향을 미치므로 여러 요소들을 고려해야 한다.
1. 데이터셋의 크기
당연하게도 데이터셋의 크기가 크다면 K값 또한 크게 설정해야 한다. 반대로 데이터셋의 크기가 작다면 K값은 작게 설정해야 한다. 데이터가 적을 떄 K값을 너무 크게 설정하면 훈련 데이터가 작아져 모델이 충분히 학습하지 못할 수 있기 때문이다.
2. 계산 비용
K값이 커진다는 건 모델이 K번 학습하고 검증한다는 뜻이기 때문에 계산 비용이 높아진다. 따라서 주어진 예산으로 가능한 최적의 K값을 찾아야 할 것이다.
3. 신뢰성
K값이 커지면 검증 데이터의 크기가 작아지므로 평가가 더 세밀해지고, 결과의 분산(Variance)이 줄어들어 더 신뢰성 있는 평가를 제공할 수 있다. 하지만 검증 데이터가 너무 작아 오히려 불안정한 결과를 초래할 가능성도 있다.
반대로 K값이 작아지면 검증 데이터의 크기가 크기 때문에 더 많은 데이터를 사용해 평가할 수 있다. 그러나 평가 결과의 분산이 커져 모델 성능에 대한 신뢰성이 낮아질 수 있다.
일반적인 K-값
보통 K=5가 계산 비용과 평가 신뢰성의 균형이 좋아 가장 많이 사용되는 값이다. 또한, K=10은 데이터가 충분히 많으며 더 높은 신뢰성이 필요할 때 사용된다.
