
시작하며
오늘은 Thread 에 대해서 제가 이해한 내용을 정리해보도록 하겠습니다.
중점이 되는 질문은 다음과 같습니다.
Thread가 왜 필요한지- 공유하는 변수를 Lock(Mutex)없이 처리하면 어떻게 되는지?
Multi Threading의 한계는 무엇인지?
예제코드를 분석하면서 진행하도록 하겠습니다.
예제 1
Code
import threading # threading 모듈
import time # 시간 측정용 time 모듈
shared_number = 0 # 공유할 전역변수
def thread_1(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1 # 공유변수(shared_number)의 값을 1 증가
def thread_2(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
if __name__ == "__main__":
# 다음의 형태를 기억하자 쓰레드가 2개일 때는 그냥 각각 join해주는것이 더 간편하겠지만
# Thread 갯수가 늘어나면 threads list에 object 넣어 놓고 for문으로 join하면
# 코드가 깔끔해진다.
threads = [ ]
start_time = time.time() # 시간 측정 시작
t1 = threading.Thread( target= thread_1, args=(50000000,) ) # 스레드1 생성
t1.start() # 스레드1 시작
threads.append(t1) # 스레드1 object를 threads에 추가
t2 = threading.Thread( target= thread_2, args=(50000000,) ) # 스레드2 생성
t2.start() # 스레드2 시작
threads.append(t2) # 스레드2 object를 threads에 추가
# 각 쓰레드를 join 하여 값을 계산
for t in threads:
t.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("shared_number=",end=""), print(shared_number)
print("end of main")Result
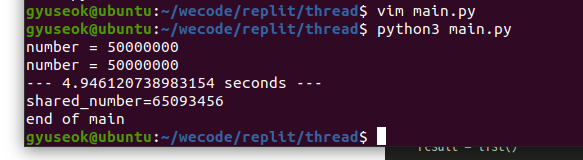
분명히 둘이 합쳐 shared_number가 1억까지 증가해야 하지만 그렇지 않은 결과가 나왔다.
이해하는 데 다음의 블로그에서 도움을 얻었다.
shared_number= 0- 스레드1에
shared_number의 값을 레지스터에 복사한다. (res1=shared_number= 0) - 스레드2에
shared_number의 값을 레지스터에 복사한다. (res2=shared_number= 0) - 스레드1에서
res1의 값을 증가 시킨다. (res1= 1) - 스레드2에서
res2의 값을 증가 시칸다. (res2= 1) - 스레드1의 res1 값을
shared_number에 복사한다. (shared_number=res1= 1) - 스레드2의 res2 값을
shared_number에 복사한다. (shared_number=res2= 2) - 최종
shared_number= 1
이렇게 연산은 동일하게 2번을 수행했지만 실제 공유변수에 제대로 반영되지않았다.
이는 파이썬의 GIL 라는 특성 때문인데 우리는 멀티쓰레드를 사용하지만 사실을 하나의 쓰레드를 시분할 해서 사용하는 것이다. 따라서 한 쓰레드에서 공유변수를 사용중일때 다른 쓰레드에서 공유변수에 접근하면 값이 충돌이 나게되는것이다.

해결하려면 어떻게 해야할까? 당연히 한 쓰레드가 공유변수를 붙잡고있는 동안 다른 쓰레드가 진입하지 못하게 하여야한다.
예제1(수정)
Code
import threading
import time
shared_number = 0 # 전역변수
lock = threading.Lock() # ++lock 객체 생성
def thread_1(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
lock.acquire() # ++thread_1이 동작하는 동안 다른 thread가 접근하지 못한다.
shared_number += 1
lock.release() # 사용을 마치면 반드시 해제를 해준다.
def thread_2(number):
global shared_number
print("number = ",end=""), print(number)
for _ in range(number):
lock.acquire() # ++thread_2가 동작하는 동안 다른 thread가 접근하지 못한다.
shared_number += 1
lock.release()
if __name__ == "__main__":
threads = [ ]
start_time = time.time()
t1 = threading.Thread( target= thread_1, args=(50000000,) )
t1.start()
threads.append(t1)
t2 = threading.Thread( target= thread_2, args=(50000000,) )
t2.start()
threads.append(t2)
for t in threads:
t.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("shared_number=",end=""), print(shared_number)
print("end of main")Result
.png)
예상 했던 결과가 나오는 것을 알 수 있다.
마치며
스레드는 병렬처리를 이해함에 있어 처음 마주치는 난관(?)으로 많은 생각을 하였다.
내가 이해한 것은 어떤 복수개의 명령이 있을 때 하나 스레드가 하나의 명령을 처리중인 동안 어떤 입력을 기다리고 있다면 원래는 입력이 들어올때까지 기다려야하지만 다른 쓰레드가 뒤의 명령을 수행함으로써 프로세서의 사용에 있어 공백의 최소화 할 때 유용한 방식이 멀티 쓰레딩 이라고 이해하였다.
그렇기 때문에 입출력 순서에 영향을 받지 않는 고용량의 데이터처리에는 쓰레드는 비효율적일 수도 있다.
그럴때는 멀티프로세싱 이 더 효율적일 수 있다.
