
1차 프로젝트가 끝났다. 그동안 말로만 '남는 건 기록뿐'이라고 하면서 정작 내 블로그에는 소홀히 하는 내 자신을 반성하며 1차 프로젝트 후기인 만큼은 기합으로 제대로 적겠다.
Whachapedia Clone
우리님이 1차프로젝트로 클론한 프로젝트는 한국의 영화 추천 서비스인 왓챠피디아이다.
어떤 영화에 대하 별점을 매기면, 취향을 분석해 좋아할만한 영화를 알아서 추천해주는 사이트이다. 영화를 좋아하긴 하지만 추천서비스까지 사용할 만큼 진심인편은 아니여서 나에게는 생소한 사이트 였다. 익숙하지 않은 컨텐츠라 걱정은 되긴 했지만 뭐 별수있나 먹고살라믄 해야지
적용기술
- 언어 : Python
- 웹 프레임워크 : Django
- 데이터 베이스 : MySQL
- 인증 인가 : jwt, bcrypt
담당 기능
- 추천 영화 리스트 뷰(메인페이지)
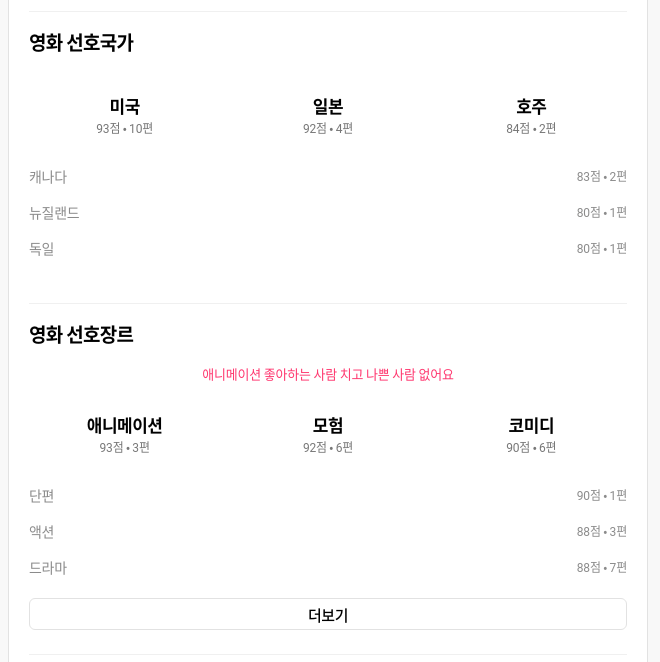
- 나의 선호 영화장르, 선호 영화국가 뷰
- 데이터 베이스에 추가할 데이터들 스크립트 작성
- aws 서버 구축
메인페이지는 팀원 각각이 실제 유저가 되어, 별점을 매긴 영화를 별점 순으로 보여주는 식으로 정하였다. 선호 영화 및 선호 장르 뷰는 사용자가 평가를 매긴 영화의 장르별, 국가별 평점과 순위를 보여주는 기능이다.
또한, 각각 팀원이 좋아하는 영화를 선정하고, 해당 영화의 정보를 네이버 OPENAPI에서 받아온 뒤
Django Shell 상에서 자동으로 데이터를 넣을 수 있도록 Script를 짰다. 이걸 작성하는데 하루를 쓸 만큼 시간이 많이 걸렸지만 모델링이 변경되거나 데이터 베이스에 문제가 있어 데이터 베이스를 날려야될때 유연하게 대처할 수 있어서 시간 낭비를 줄이는 데 많은 도움이 되었다.
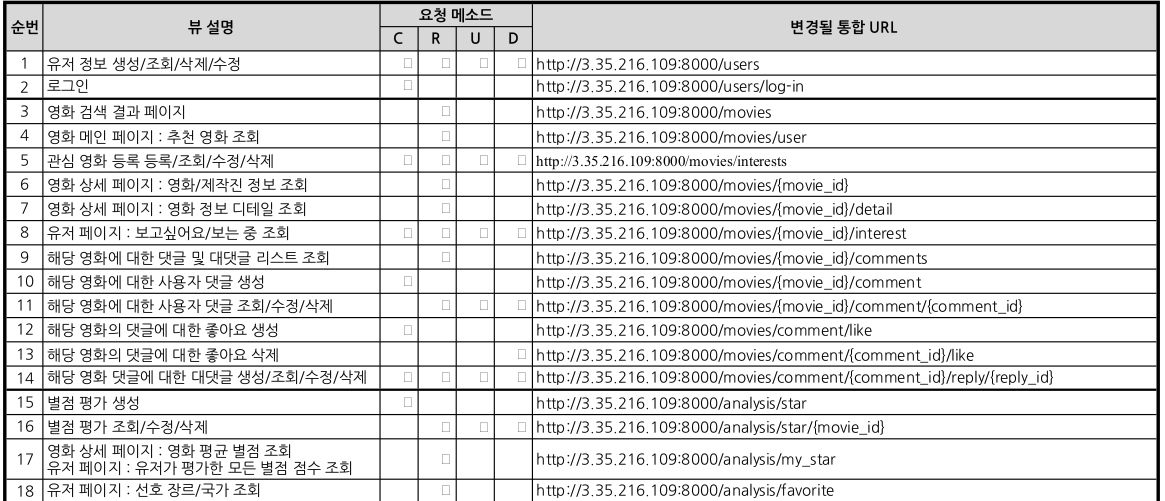
수희님은 본인이 맡은 기능 구현이외에도 이렇게 깔끔하게 URL을 정리해주셔서 프/백 모두 이 문서를 기준으로 엔드포인트 공유를 안정적으로 할 수 있었다. 이것 나에게는 쉬운일이 아니란 걸 잘 알고 있다.
영주님도 본인이 맡은 기능 구현이외에도 프로젝트의 룩앤필을 위해서 사진들을 한땀한땀 작업해주었다. 발표때는 정신이없어 제대로 보여주지 못했기에 여기에 박제한다. 역시나 이것도 나에게는 쉬운일이 아니다.



이런 디테일들이 모여 프로젝트를 더 빛내는 것 같다. 너무 좋고
모델링
모델링은 가능한 단순하게 구성하려고 하였다.
실제 현업에서는 모델링을 구현할 수 있는 기회는 흔치 않을 것이라고 생각이 들어 우리의 백엔드 엔젤들인 수희, 영주님과 모두가 이해할 수 있는 모델을 짜기 위해서 대화를 많이 한 것 같다.
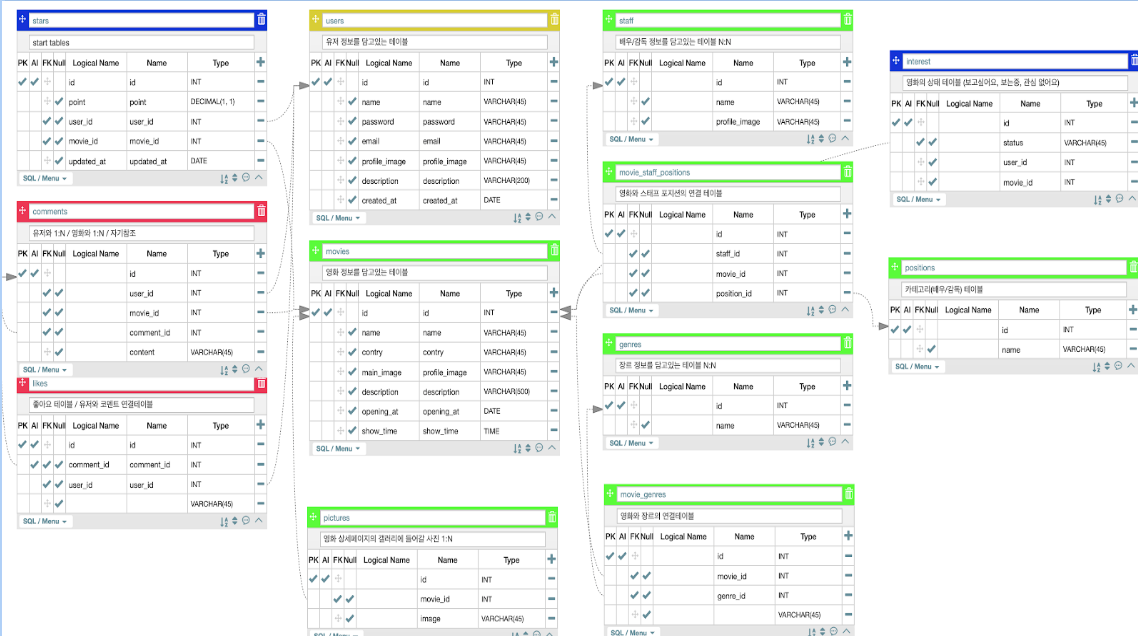
왓챠피디아는 영화라는 상품을 중심으로 '평가'를 보여주는 사이트이기 때문에 평가의 기준을 잡는 것이 필요했다. 우리는 별점을 기준으로 평가를 결정하기로 하였고 유저, 영화, 별점이라는 3가지 모델을 중심으로 모델들을 확장해나가니 프로젝트에 필요한 모델들만 추릴 수 있어서 좋았다.
기억에 남는 코드
기억에 남는 코드라 하면 단연 베스트가 있다.
class FavoriteView(View):
@login_decorator
def get(self, request):
account_id = request.user
category = request.GET.get('category', 'genre') # '장르(genre)' 또는 '국가(country)'
results = {}
stars = []
if category == 'genre':
stars = Star.objects.select_related('movie').prefetch_related('movie__genre_set').filter(user_id=account_id)
for star in stars:
if not star.movie.genre_set.name in results:
results[star.movie.genre_set.name] = {'count': 0, 'score': 0}
results[star.movie.genre_set.name]['count'] += 1
results[star.movie.genre_set.name]['score'] += star.point
if category == 'country':
stars = Star.objects.select_related('movie').filter(user_id=account_id)
for star in stars:
if not star.movie.country in results:
results[star.movie.country] = {'count': 0, 'score': 0}
results[star.movie.country]['count'] += 1
results[star.movie.country]['score'] += star.point
for result in results.values():
result['score'] = int(result['score'] / result['count'] * 20)
content = {
'wholeCount': len(stars),
'watchingTime' : sum([star.movie.show_time for star in stars]),
'data': sorted([{
'label': key,
'score': value['score'],
'count': value['count'],
} for key, value in results.items()], key=lambda data: data['score'], reverse=True)
}
return JsonResponse(content, status=200)다음의 코드는 선호 영화장르, 선호영화 국가를 보여주기 위해 작성한 뷰이다.
우선 Query String으로 장르를 가져올 것인지 국가를 가져올것인지 결정한다.
만약 장르를 선택할 경우 유저가 별점을 매긴 영화를 정참조(별점은 하나의 영화만 가질 수 있다) 후 해당 영화를 역참조(하나의 영화는 다양한 장르를 가질수 있다)로 가져온뒤 장르별 별점의 개수와 평균을 구하는 로직이다.
동작은 잘 된다 query도 낭비 되지않는다. 하지만 마치 고급빌딩에 푸세식 화장실을 만든 기분이 었다.
이때 멘토 지훈님께서 거의 계시와 같은 솔루션을 주셧다. queryset 요청부터 annotate과 Count,Avg를 이용해서 카테고리 별로 평균과 개수를 출력하는 방법을 알려주셨다. 처음에는 조금 벙쪘던것같다. annotate를 이용해서 원하는 컬럼을 만들 수 있다는 것은 알고 있었지만, 이럴 때 사용할 수 있다는 것은 알지 못했다.
지훈님의 솔루션으로 뚜드러 맞자마자 어떻게 코드를 바꾸면 될지 바로 느낌이왔다.
코드를 수정하면 다음과 같다.
class FavoriteView(View):
@login_decorator
def get(self, request):
account_id = request.user
category = request.GET.get('category', 'genre') # '장르(genre)' 또는 '국가(country)'
stars = []
category_path = ''
if category == 'genre':
stars = Star.objects.select_related('movie').prefetch_related('movie__genre_set').filter(user_id=account_id)
category_path = 'movie__genre__name'
if category == 'country':
stars = Star.objects.select_related('movie').filter(user_id=account_id)
category_path = 'movie__country'
context = {
'wholeCount': len(stars),
'watchingTime' : sum([star.movie.show_time for star in stars]),
'data': [{
'label': star[category_path],
'score': int(star['avg']),
'count': star['count'],
} for star in stars.values(category_path).annotate(count=Count(category_path), avg=20 * Avg('point')).order_by('-avg')]
}
return JsonResponse(context, status=200)거이 밋였다고 볼수 있다.. 이렇게 되면 다른 선호 영화카테고리가 추가되도 if문 포함 3줄씩만 추가되면 된다. 또한 코드가 무엇을 하려하는지 더 명확하게 알 수 있다.
느낀점
1차프로젝트에서는 기술적인 부분보다는 협업에 대해서 많이 집중했던 것 같다.
기술적인 부분은 혼자서도 공부해도 되지만 협업은 절대 혼자 할 수 없다. 말그대로 협업이니까.
물론 기술적인 부분도 중요하다 멘토링과 코드리뷰를 통해서 '나는 이정도면 괜찮은거 같은데'라는 생각을 많이 깰 수 있었다. 역시 기술은 필요에 의해서 배우는게 가장 머리에 강하게 남는 거 같다.
하지만 그런것 보다는 백엔드 동기들과 머리를 맞대고 '셋이 머리를 모으면 아이큐300!'을 외치면서 즐겁게 모델링을 했던 것, 다른 팀에 비해 프로젝트가 진행이 더뎠을 때도 게속해서 '아니야 우리 할 수 있어'를 말하면서 서로를 다독였던 것, 그런 기억 하나 하나가 사실 프로젝트의 완성도 보다 소중한 것 같다.
어떻게 이제 막 배운 사람들끼리 단번에 좋은 서비스를 만들겟는가. 서로 다른 기준을 가진 사람들끼리 하나의 목적을 가지고 같이 가는 과정 자체가 너무 흥미로웠다. 그렇게 만든 결과물은 부족하더라도 소중하다. 우리의 얘기가 담긴 것들이니까.
위코드 멘토 준님의 블로그에서 '프로그래밍 실력을 깊이 있게 해 나가는 즐거움보다 동기 한 사람 한 사람이 보여주는 세계를 마주하는 일이 더욱 즐겁다.'라는 문구가 다시금 와닿는다.
2차 프로젝트
감동은 대충 여기까지 하도록 하고 항상 무언가를 진행하다보면 이런 생각이 든다. 어? 처음부터 이렇게 했으면 더 좋았을 텐데 이 방식으로 하면 더 효율적일 텐데 보통은 기차 떠나고 후회를 많이 하지만 위코드는 한번의 기회가 더있다. 1차에서는 그냥 필요한대로 부딫혀가면서 한거 같다. 그건 백엔드가 아니다. 좀 더 구성지고 단단해져야한다. 2차 프로젝트에서는 더 단단하게 프로젝트를 진행해보고 싶다.
우선 엔드포인트가 늘어날 수록 테스트가 번거로워 진다. 반드시 테스트를 작성하자. 아니 아예 TDD처럼 테스트를 먼저 작성하고 기능을 구현하자. 테스트를 귀찮아하지 말자. 테스트를 귀찮아하면 다른 귀찮은 일들이 생긴다.
두번째 Django 기능 구현을 시작하기전 URL 먼저 정리를 해놓자.
리스트 출력이 필요한 구간과 CRUD를 구분하고 URL 단위로 업무를 분배하자.
기능을 짤 때 전체적인 양과 진행도의 기준으로 삼으면 훨씬 체계적으로 일을 진행 할 수 있을 것 같다.
마지막으로 가슴이 웅장해지는 사진을 남기며 마치겟다.





그저 규---멘