이전 포스트에서 equals 를 재정의한 클래스에서 모두 hashCode도 재정의해야한다고 언급했다. 이유를 알아보자 😃
🙅 hashCode() 를 재정의하지 않는 경우
Address
package item11;
public class Address {
private final String street;
private final String city;
private final String state;
private final String postalCode;
private Address(String street, String city, String state, String postalCode) {
this.street = street;
this.city = city;
this.state = state;
this.postalCode = postalCode;
}
public static Address of(String street, String city, String state, String postalCode) {
return new Address(street, city, state, postalCode);
}
@Override
public boolean equals(Object obj) {
if(obj == this){
return true;
}else{
if(obj instanceof Address){
Address address = (Address) obj;
if (!street.equals(address.street)) return false;
if (!city.equals(address.city)) return false;
if (!state.equals(address.state)) return false;
return postalCode.equals(address.postalCode);
}
return false;
}
}
}
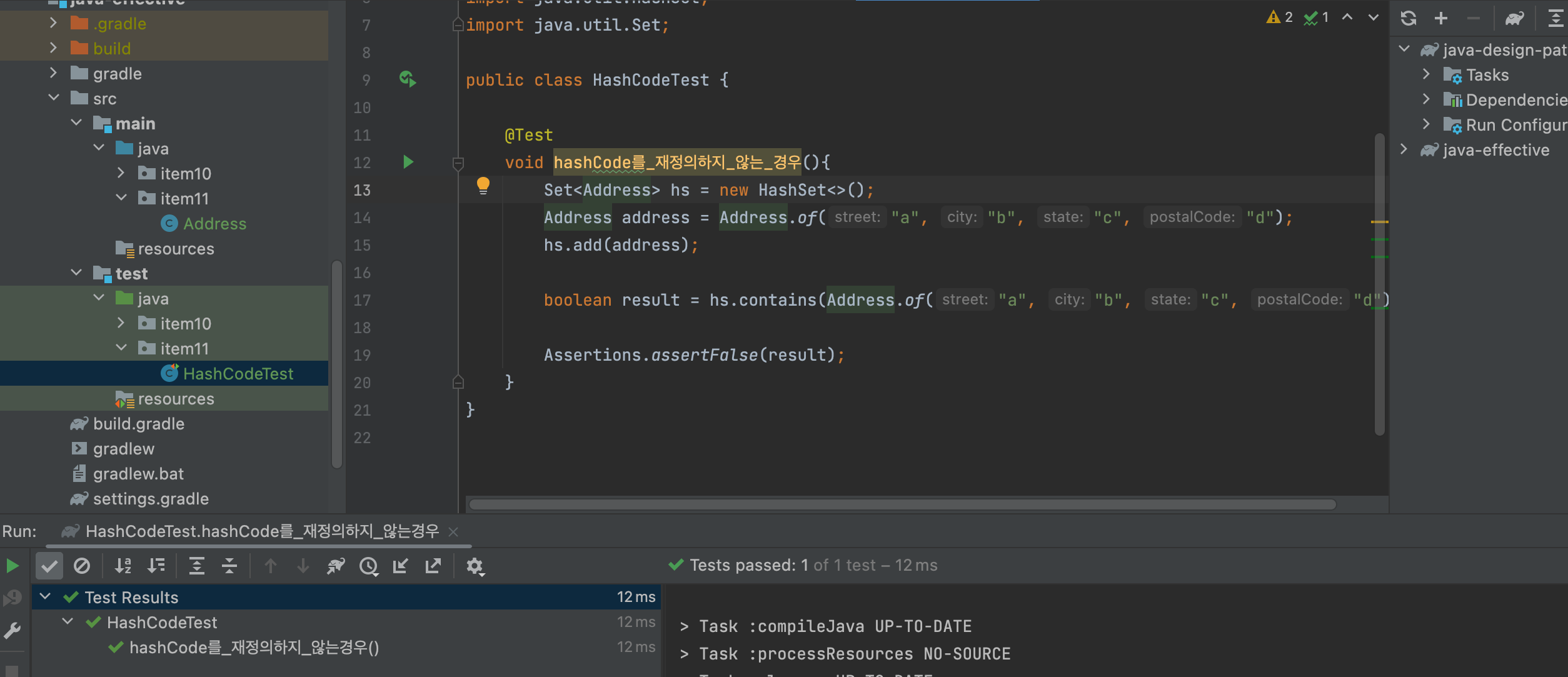
equals 만 재정의 후, hashCode 를 재정의 하지 않은 채로 Set에서 찾을 수 있는지 테스트해보면 찾을 수 없음을 알 수 있다.
🧐 직접 코드를 까보며 왜 그런건지 알아보자
HashSet
public boolean contains(Object o) {
return this.map.containsKey(o);
}
HashMap
public boolean containsKey(Object key) {
return this.getNode(hash(key), key) != null;
}
final Node<K, V> getNode(int hash, Object key) {
Node[] tab;
Node first;
int n;
if ((tab = this.table) != null && (n = tab.length) > 0 && (first = tab[n - 1 & hash]) != null) {
Object k;
if (first.hash == hash && ((k = first.key) == key || key != null && key.equals(k))) {
return first;
}
Node e;
if ((e = first.next) != null) {
if (first instanceof TreeNode) {
return ((TreeNode)first).getTreeNode(hash, key);
}
do {
if (e.hash == hash && ((k = e.key) == key || key != null && key.equals(k))) {
return e;
}
} while((e = e.next) != null);
}
}
return null;
}
static final int hash(Object key) {
int h;
return key == null ? 0 : (h = key.hashCode()) ^ h >>> 16;
}코드를 까보면 다음과 같은 과정으로 컬렉션에 해당 인스턴스가 존재하는지를 찾고 있다.
-
키(key)가 null인 경우 해시 코드는 0이며 그렇지 않은 경우, key.hashCode()를 통해 해시 코드를 계산하고, 이를 비트 연산을 통해 조정하여 반환한다.
-
주어진 객체 o가 HashSet에 포함되어 있는지 확인하기 위해 map의 내부 테이블(table)에서 주어진 해시 코드와 키에 해당하는 노드(Node)를 찾는다. 이때 해시 코드 hash를 기반으로 내부 테이블(table)에서 해당 인덱스를 계산한다.
-
해당 인덱스에 위치한 첫 번째 노드 first를 가져오고 첫 번째 노드(first)의 해시 코드와 키를 비교하여 주어진 해시 코드와 키와 일치하는지 확인한다. 만약 일치하면 해당 첫 번째 노드(first)를 반환하고첫 번째 노드(first)와 동일한 해시 코드를 가진 다음 노드 e를 찾는다. 각 노드 e의 해시 코드와 키를 비교하여 주어진 해시 코드와 키와 일치하는지 확인한다. 만약 일치하는 노드 e를 찾으면 해당 노드를 반환한다.
-
일치하는 노드가 없을 경우, 루프를 계속하며 다음 노드를 확인한다.
정리하자면 애초에 hashCode 가 다르면 동치성 검사도 진행하지 않는다.
그런데 hashCode() 를 재정의하지 않으면 자바에서 기본적으로 제공되는 Object 클래스의 hashCode() 메서드가 객체의 메모리 주소를 기반으로 한 해시 코드를 반환하게 된다. 서로 다른 객체는 다른 메모리 주소를 가지므로 hashCode() 메서드를 재정의하지 않은 경우 모든 인스턴스는 전부 다른 해시 코드를 갖게 된다.
즉, 우리가 의도한 바와 결과를 일치시키려면 논리적 동치성 판단 기준인 equals를 정의할 때 컬렉션에서 사용될 수 있는 hashCode까지 정의를 해주어야한다.
🚀 hashCode 정의 방법
hashCode를 정의할 때는 성능을 고려해서 정의해야한다.
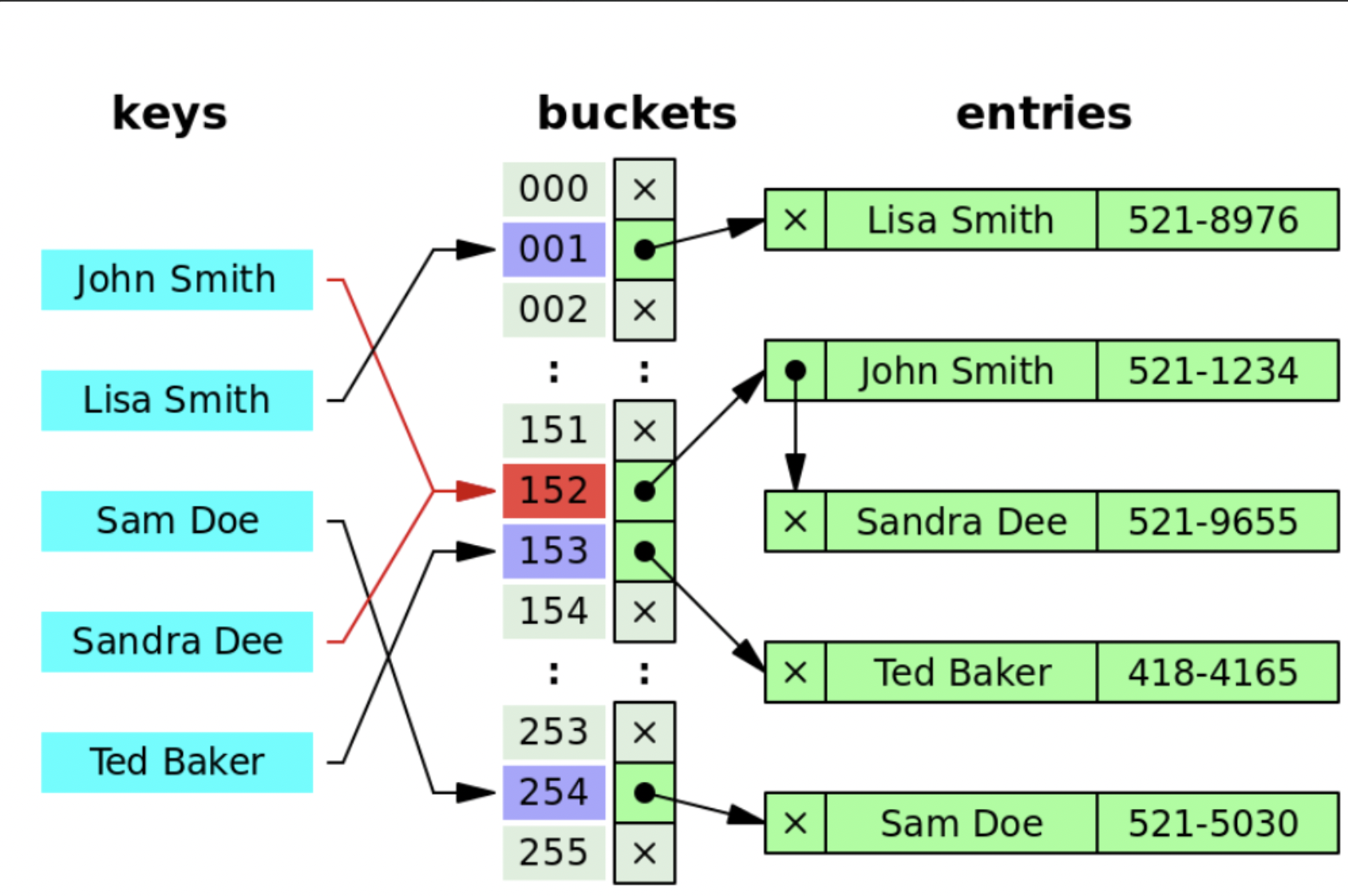
다음과 같이 해시 함수를 통해 도출한 해시 값이 같은 경우, 즉 해시충돌이 발생하는 만큼 성능이 저하된다.
방금 전에 코드를 통해 살펴봤듯이 HashSet같은 경우 FistNode 부터 순서대로 값을 찾아가기 때문에, 해시 값이 모두 같아 동일 bucket에 모든 entry가 들어가게 되면 최대 O(N) 의 시간복잡도를 갖게 되므로 최대한 bucket 이 겹치지 않게 해시값을 설정해야 O(1) 에 근접한 성능을 낼 수 있다.
따라서 좋은 해시함수란, 서로 다른 인스턴스에 대해 다른 해시 코드를 반환하는 것이며, 32 비트 정수 범위에 균일하게 분배해야하는데 이상은 어렵지만 비슷하게 만들기는 어렵지 않다.
다음은 해시 코드 작성하는 간단한 요령이다.
-
int 변수인
result를 선언한 후 값을 c로 초기화한다. -
나머지 핵심 필드인 각각에 해시코드를 계산한다.
-
기본 타입 필드라면, Type.hashCode(f)를 수행한다. 여기서 Type은 해당 기본타입의 박싱 클래스다.
-
참조 타입 필드면서, 이 클래스의 equals 메소드가 이 필드의 equals를 재귀적으로 호출하여 비교한다면, 이 필드의 hashCode를 재귀적으로 호출한다.
-
필드가 배열이라면, 핵심 원소 각각을 별도 필드처럼 다룬다. 모든 원소가 핵심 원소라면 Arrays.hashCode를 사용한다.
result = 31 * result + c;
- result를 반환한다.
31을 곱해주는 것은 홀수이자 Prime 이기 때문에 해시 결과를 더 넓게 그리고 더 고르게 분배하여 해시 충돌을 줄이기 위함이다. 꼭 31 을 사용하는것은 아니지만 일종의 관례이다.
기존 코드에도 적용을 해보자.
Address
public class Address {
private final String street;
private final String city;
private final String state;
private final String postalCode;
private Address(String street, String city, String state, String postalCode) {
this.street = street;
this.city = city;
this.state = state;
this.postalCode = postalCode;
}
public static Address of(String street, String city, String state, String postalCode) {
return new Address(street, city, state, postalCode);
}
@Override
public boolean equals(Object obj) {
if(obj == this){
return true;
}else{
if(obj instanceof Address){
Address address = (Address) obj;
if (!street.equals(address.street)) return false;
if (!city.equals(address.city)) return false;
if (!state.equals(address.state)) return false;
return postalCode.equals(address.postalCode);
}
return false;
}
}
@Override
public int hashCode() {
int result = street.hashCode();
result = 31 * result + city.hashCode();
result = 31 * result + state.hashCode();
result = 31 * result + postalCode.hashCode();
return result;
}
}
다시 동일하게 컬렉션에 넣어 테스트를 진행해보자.
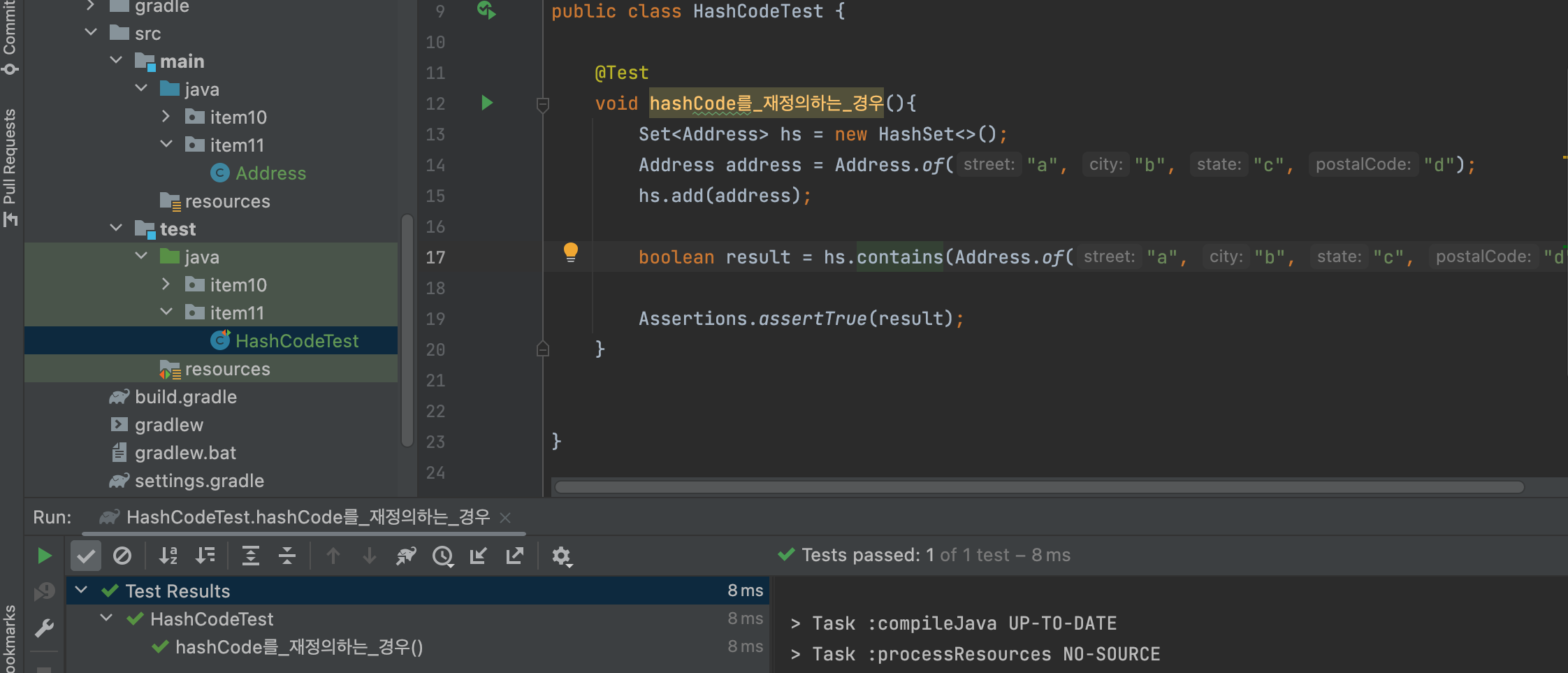
이제 필드가 모두 같을 경우 같은 해시값을 갖게 되어 컬렉션에서 해시 탐색을 통해 찾을 수 있게 된다.
정리
hashCode를 재정의하지 않으면 컬렉션에서 최적화를 위해 해시값이 일치하지 않는 경우에 equals 비교를 시작하지도 않아서 찾질 못한다. 즉, 논리적 동치성을 재정의하여 equals 가 같더라도 최적화를 위한 로직에 걸리게 된다.
따라서 hashCode도 함께 정의해야 컬렉션을 이용하게 되었을 때 프로그래머가 예상 가능한 결과를 낼 수 있다. hashCode는 성능을 고려하여 O(1)에 가까운 성능을 낼 수 있도록 재정의해야한다.
물론 컬렉션을 사용하지 않는다면 굳이 hashCode를 재정의할 이유는 없다. 하지만 지금 정의한 클래스가 1년 2년뒤 어떻게 사용되고 어떻게 활용될지는 모르는 일이니, 조금이라도 가능성이 있다면 작성해주는 것이 좋지 않을까?
