각 자료구조의 시간복잡도
- 배열 : O(n)
- 이진 탐색 트리 : O(n) -> 평균 O(log n)
- AVL 트리 : O(log n)
- B-Tree : O(log n)
Hashing은 O(1)인 file organization
간단한 개념
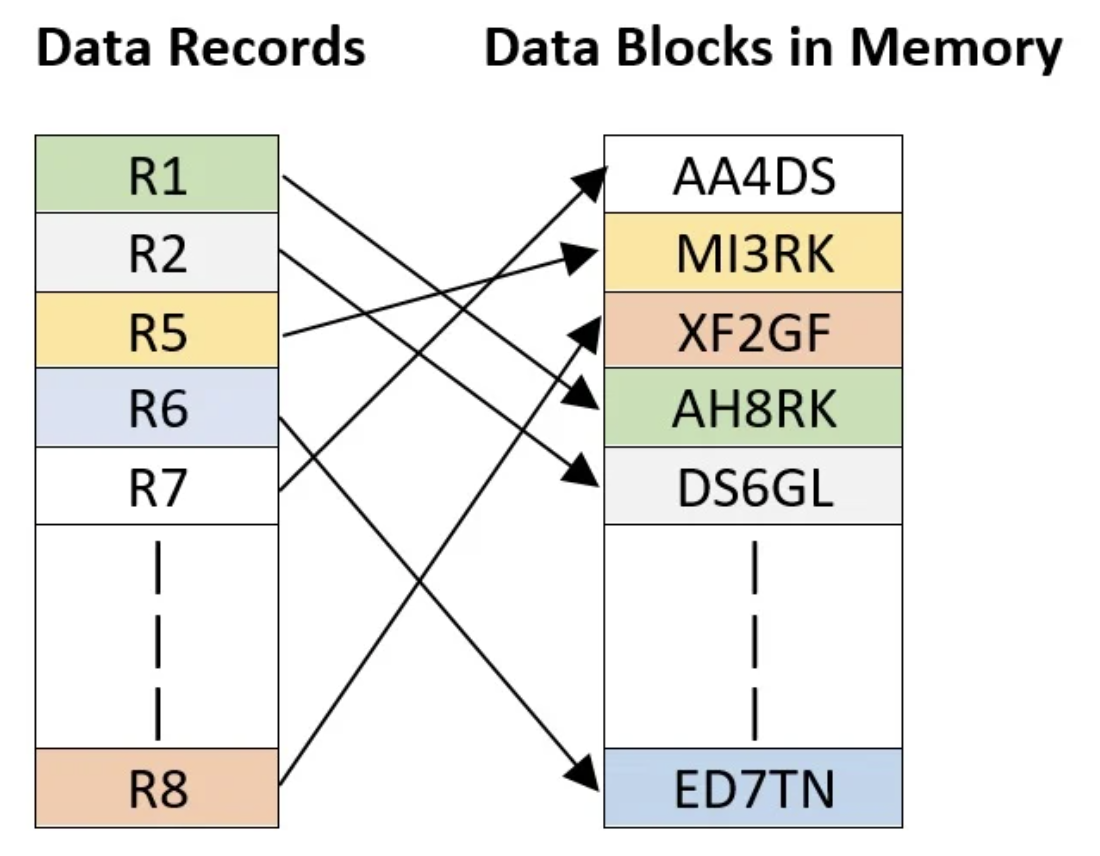
record의 key값 자체가 record의 실제 주소
해시 함수
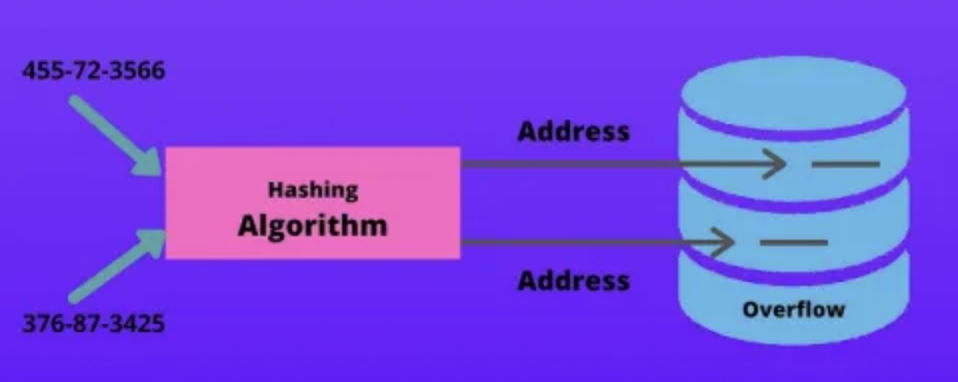
- HA = Hash(K)
- K를 key값으로 하는 주소 공간에 HA를 지정하여 record를 저장
- key값을 변환시킨 주소를 해시 주소(HA)라 부름
Hash Functions
1. Division Method
2. Folding
3. Mid-Square
4. Radix Conversion
5. Alphabetic Keys
Division Method
- Key mod N(table size)
- Key mod P(prime number) : 소수가 더 균등히 분포됨

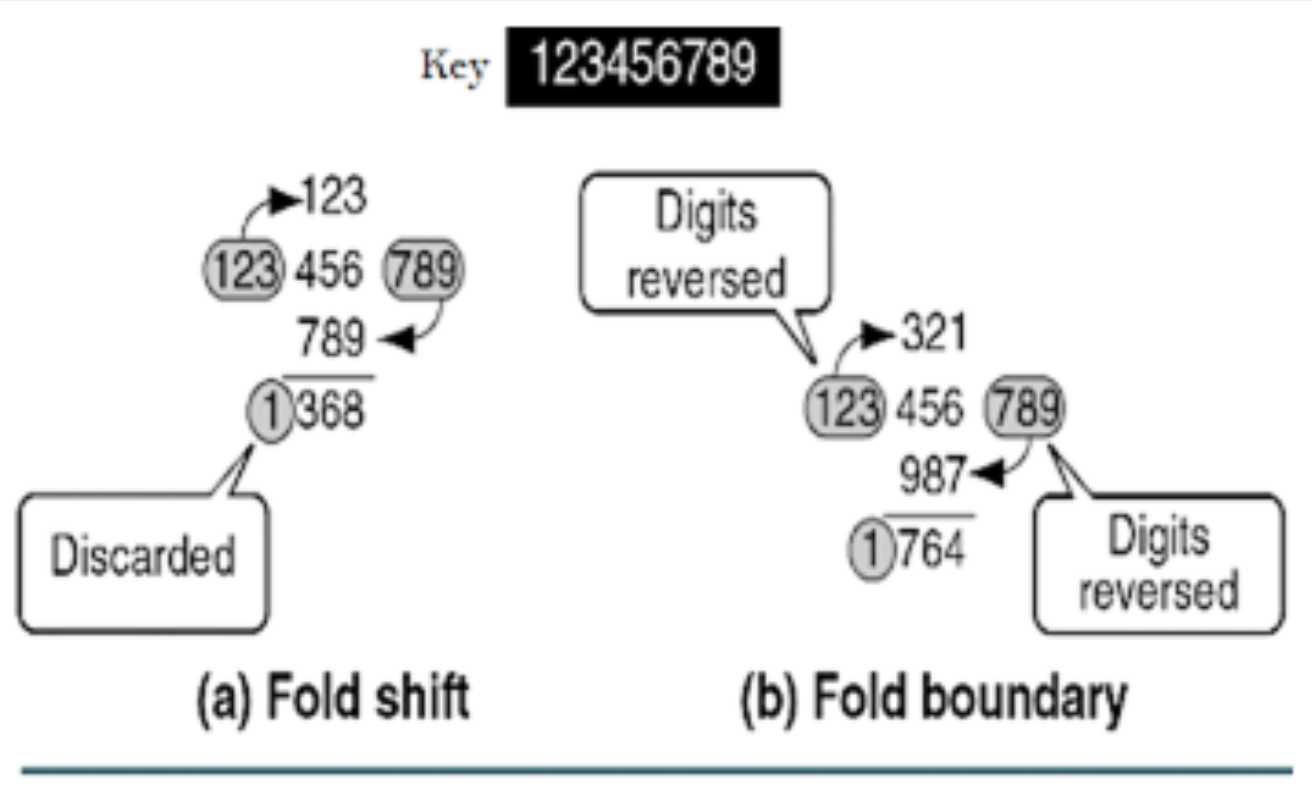
Folding (실제로는 Division Method 선호)
- Folding by boundary
- Folding by shifting
Mid-Square
- key 값을 제곱한 후 제곱한 수의 중간에 정해진 자리 수만큼을 가져와 HA로 변환
Radix Conversion
- key를 진법으로 계산
Alphabetic Keys
- key의 첫 번째 문자의 ASCII 값 사용
문제점
충돌(Collision) 발생
- 서로 다른 key들이 동일한 hash값을 가질 때
-> 2가지 해결 방법- Chaining 방법
- Chainless 방법
두 가지 방법은 다음 시간에 알아보도록 하겠습니다.

meme