ohmo 라는 일정 관리 서비스를 개발 중이다.
일정 관리 서비스에서는 사용자가 특정 날짜의 일정을 바로 확인하는 기능이 가장 많이 쓰인다. 해당 API의 조회 성능을 Index를 사용해서 개선해 보겠다.
개선하려는 API는 한 사용자의 일정 중 특정 날짜인 일정을 조회하는 기능이다.
만약 서비스가 성장하고 사용자가 늘어나면 schedule 테이블에는 수백만 건의 데이터가 쌓일 수 있다. 이때 특정 사용자와 날짜를 기준으로 일정을 조회하면, DB는 외래키의 인덱스로 먼저 해당 사용자의 일정만 찾지만, 그 안에서도 수많은 row를 확인해야 한다.(한 사용자가 몇 만개의 일정을 가지고 있을 수 있다) 데이터가 많아질수록 이 과정에서 조회 속도가 느려질 수 있고 서비스 사용성에 불편함으로 이어진다.
따라서 많은 데이터에서도 빠르게 특정 날짜의 일정을 조회할 수 있도록 성능을 개선하는 것이 필요하다.
상황 가정
한 사용자가 3년 이상 서비스를 이용한다고 가정했다.
일정(schedule)에는 루틴(routine)과 투두(todo)가 따로 있어서
routine 테이블과 todo 테이블에는 각각 schdule_id로 외래키를 가지고 있고 schudule을 참조하고 있다.
사용자 1명은 하루 평균 3개의 todo와 3개의 routine이 있다고 가정하여 각각 3000(3 x 365 x 3(년) = 3285)개씩 해서 총 6000개의 일정 데이터를 날짜를 랜덤하게 설정하여 넣었다.
- 사용자의 수 100명
- 한 사용자가 2년 서비스를 이용한 상황
- 한 명당 6000개의 일정(루틴: 3000 + 투두: 3000)이 있는 상황
- routine 테이블에 100 x 3000개의 데이터, todo 테이블에 100 x 3000개의 데이터
- schedule 테이블에 총 600,000개의 데이터
인덱스 사용하기 전
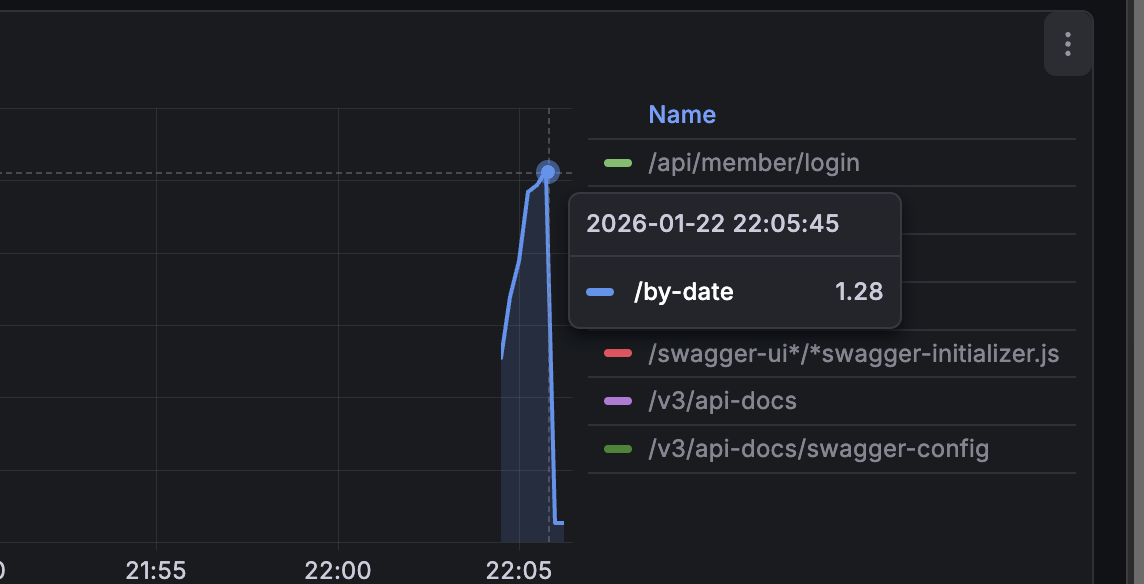
k6로 100명의 사용자가 동시에 요청하도록 테스트를 한 결과
p95는 1.28s가 나왔다.
p95 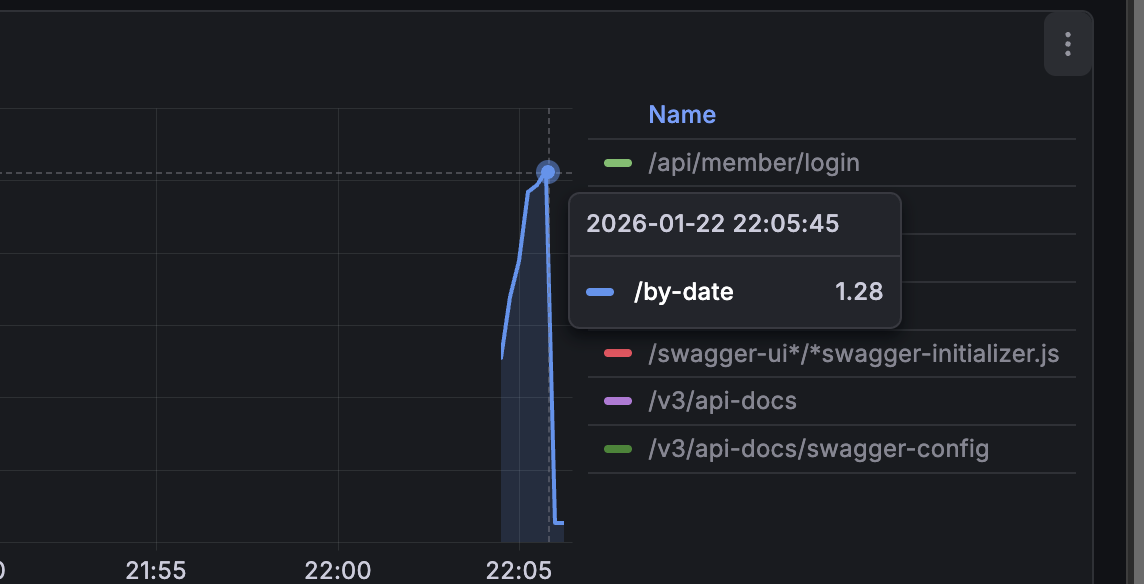
사용하는 쿼리는 아래와 같다
@Query("SELECT s FROM Schedule s " +
"JOIN FETCH s.todo " +
"JOIN FETCH s.memberCategory mc " +
"WHERE mc.member = :member " +
"AND s.date = :date " +
"AND s.scheduleType = :scheduleType")
List<Schedule> findSchedulesByMemberAndDateAndScheduleType(
@Param("member") Member member,
@Param("date") LocalDate date,
@Param("scheduleType") ScheduleType scheduleType);이 쿼리는 특정 회원의 특정 날짜(date) 및 타입(ScheduleType)에 해당하는 일정을 연관된 데이터(Todo, Category)와 함께 한 번에 조회하는 쿼리이다.
@Query("SELECT r FROM MemberCategory mc " +
"JOIN mc.scheduleList s " +
"JOIN s.routineList r " +
"WHERE mc.member = :member " +
"AND r.date = :date")
List<Routine> findRoutinesWithScheduleByMemberAndDate(
@Param("member") Member member,
@Param("date") LocalDate date
);
이 쿼리는 특정 회원의 카테고리와 스케줄을 순차적으로 탐색해 해당 회원이 특정 날짜(date)에 수행해야 할 모든 루틴(Routine)을 조회하는 쿼리이다.
explain
두 쿼리에 대해 explain 을 해봤다.
첫번째

-
rows: 3146
schedule 테이블에서 memberCategory 외래키 인덱스를 사용하여 특 정 사용자의 데이터를 필터링한다.-> 전체 60만의 데이터 중 해당 사용자의 카테고리에 속한 약 3,000개의 일정 데이터를 1차적으로 조회한다.
- filtered: 5
인덱스로 걸러낸 3000개는 date, type의 조건을 확인하지 않은 상태이다. 그래서 이 3000개를 하나씩 다 대조한 결과 3000개 중 실제 조건(date, type)에 맞는 데이터는 5%라는 뜻이다.
두번째

여기도 위와 비슷한 결과를 확인했다.
-
s table의 rows : 2974
s table에서는 3000개의 데이터를 가져온다.
schedule 테이블에서 memberCategory 인덱스를 사용해서 특정 member인 memberCategory로 약 30000개의 데이터를 조회한다. -
r table의 rows: 1
s 테이블 (Schedule)은 전체 탐색 범위가 3000개, r 테이블 (Routine)은 s에서 넘어온 행 1개당 인덱스를 타고 들어가 보니, 해당 schedule_id를 가진 데이터가 평균적으로 1개씩 있다는 뜻이다.현재 routine과 schedule의 관계는 아래와 같다.
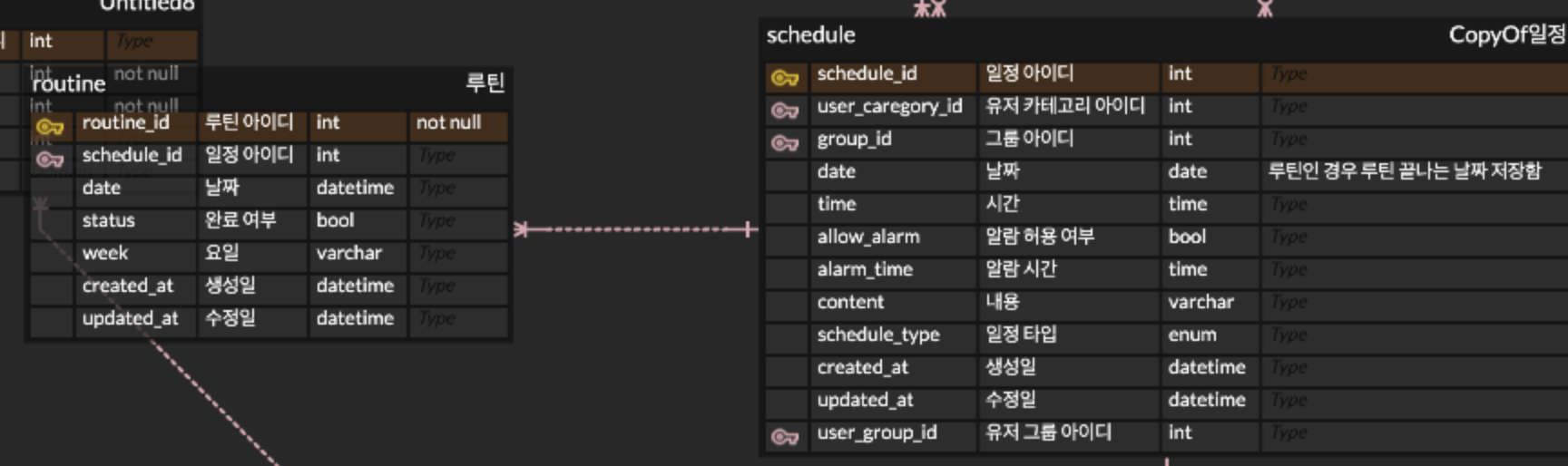
schedule 과 routine은 n:1 관계이다. 하지만 테스트 환경의 데이터에는 schedule마다 routine이 한 개씩 있는 걸로 해서 넣었기 때문에 rows가 1이 나오는 것이다. -> 실제 상황처럼 schedule마다 여러 개의 routine이 있다면 여러 개가 나오겠지?
-> 총 3,000번의 인덱스 탐색을 통해 3,000개의 routine 데이터를 메모리로 올린다. -
r table의 filtered: 10
메모리에 올라온 3,000개의 루틴 데이터에는 날짜(date) 조건이 확인되지 않은 상태이다.
따라서 이 3,000개를 하나하나 열어보며 오늘 날짜가 맞는지 대조하다 보니 3000개 중 10% 만 맞았다는 뜻이다.
인덱스 적용하기
첫 번째 쿼리를 보면 schedule에서 사용하는 조건이 memberCategoryId, date, scheduleType이다.
CREATE INDEX idx_schedule_member_date_type
ON schedule (member_category_id, date, schedule_type);
member_category_id : 가장 앞에 두었다. 60만 건의 데이터 중 특정 사용자의 카테고리(약 3,000건)로 범위를 가장 많이 좁힐 수 있다.
date & schedule_type: 후속에 배치했다. member_category_id로 조회된 3,000건 내에서 날짜와 타입으로 정렬된 상태로 빠르게 조회할 수 있다.
그리고 두 번째 쿼리에서는 routine에서 조회할때 scheduleId, date를 조건으로 조회한다. 그래서 이 두개를 가지고 인덱스를 만들겠다.
CREATE INDEX idx_routine_schedule_date ON routine (schedule_id, date);위와 같은 방식으로 schedule_id로 먼저 30만개의 routine에서 3000개로 좁힌다. 그리고 date로 정렬한 index로 빠르게 조회할 수 있다.
결과
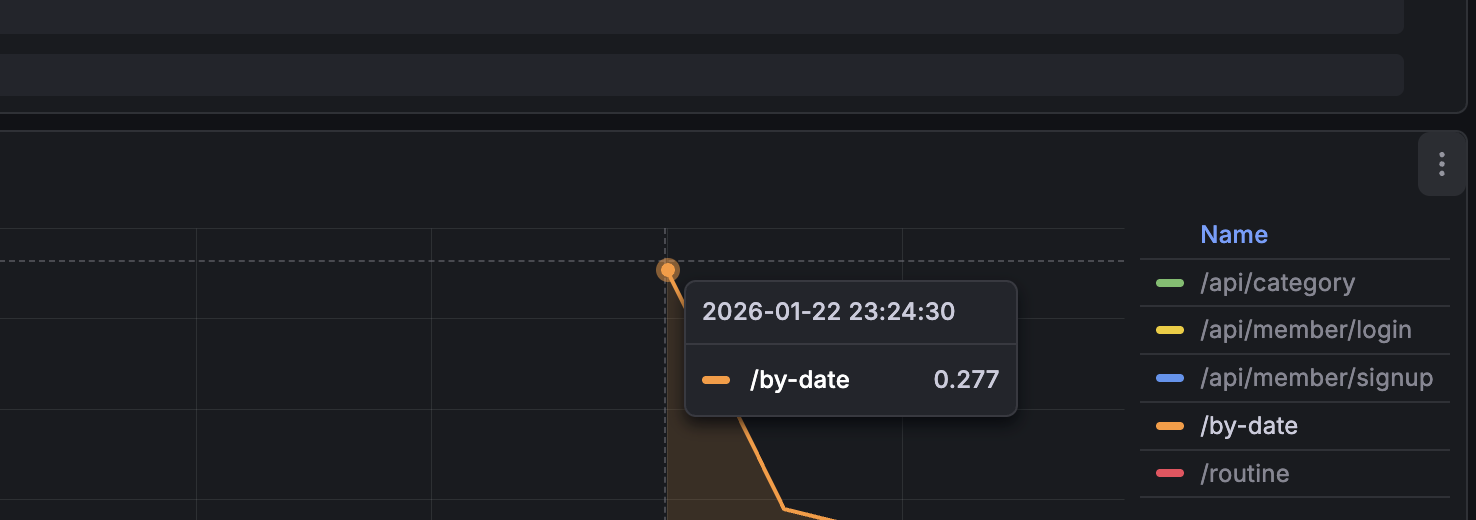
p95가 0.277로 확실하게 감소한 것을 확인할 수 있었다.
explain을 다시 해봤다.

- rows : 3,146 → 8 (비교 작업 99.7% 감소)
인덱스를 보고, 조건에 맞는 딱 8건의 위치로 바로 간다. - filtered: 5 → 100 (버리는 데이터 없음)
전에는 3,146개를 가져와서 95%는 조건에 안 맞아서 버렸는데, 가져온 8건 모두가 찾던 날짜와 타입에 딱 들어맞는 데이터라는 뜻이다.

-
filtered: 10 → 100 (버리는 데이터 없음)
여기도 마찬가지로 이전에는 3000개의 데이터 중 특정 날짜와 맞는 데이터가 10% 뿐이었는데 이제는 date 인덱스로 조건에 맞는 데이터로 곧 바로 가서 데이터를 가져오기 때문에 모두 일치하다는 것을 볼 수 있다.
결과 요약
개선 전: P95 응답 속도 1.28s
개선 후: P95 응답 속도 0.277s
단축된 시간: 1.003s
개선율: 약 78.36%
