StringTokenizer 클래스는 Java 1.0 부터 제공하던 클래스로, 지정한 구분자로 문자열을 쪼개주는 클래스이다. Enumertaion 인터페이스를 구현하고 있다.
클래스를 사용한 간단한 예를 들면,
"This is how to use Tokenizer." 라는 문자열을 공백 한 칸을 기준으로 쪼갠다면,
This
is
how
to
use
Tokenizer.
이렇게 총 6개의 토큰으로 쪼개고 순서대로 반환할 수 있는 것이 StringTokenizer 클래스의 기능이다.
StringTokenizer 클래스를 사용하기 위해서는 먼저 java.util.StringTokenizer 를 import 해줘야 한다.
생성자(Constructor)
public StringTokenizer(String str) 전달된 매개변수 'str'을 기본 delimiter를 기준으로 각각의 토큰으로 분리한다. 이 때 기본 delimiter는 공백 문자인 " \t\n\r\f" 이다.
단순히 공백 한칸 기준으로 문자열을 분리할 때 사용한다.
public StringTokenizer(String str, String delim)직접 지정한 delimiter(delim)를 기준으로 전달된 매개변수 'str'을 각각의 토큰으로 분리한다. 공백이 아닌 자신이 원하는 delim(예: 공백 두 자, !, abc 등)을 사용하고 싶을 때 사용한다.
이 때, 연속되는 문자(예: abc)를 delim으로 사용할 경우, 문자열에서 'abc' 를 기준으로 분리하는 게 아닌, 'a', 'b', 'c' 각각을 기준으로 분리한다.
예를 들어, 'abcde'라는 문자열을 'abc'를 delim으로 정하여 분리할 경우,
결과는 'de' 이다. 이때는 'abc' 기준으로 분리되는지 'a', 'b', 'c' 기준으로 분리되는지 구별할 수 없으나, 만약 returnDelims:true 일 경우,
a
b
c
de
위와 같은 결과가 나오므로, delim이 문자열이더라도 구성하는 각각의 한 문자를 기준으로 분리된다고 할 수 있다.
public StringTokenizer(String str, String delim, boolean returnDelims)위 생성자와 비슷하나, 분리하는 기준인 delim 까지 토큰에 포함시킬 여부를 정할 수 있다. 매개변수 returnDelims가 true일 경우 포함, false일 경우 포함하지 않는다.
public StringTokenizer(String str, String delim)처럼 매개변수가 없을 경우 기본적으로 포함하지 않는다.
예외 : NullPointerException - str 이 null 일 경우
메소드
int countTokens()예외를 호출하기 전까지 남아있는 토큰의 갯수를 반환한다. 반환형은 int 이다.
**
boolean hasMoreElements()
boolean hasMoreTokens()두 메소드 기능은 완전히 동일하다. 반환할 수 있는 토큰이 남아있다면 True, 없다면 False를 반환한다. 반환형은 당연히 boolean 이다.
그런데 굳이 동일한 기능의 메소드가 두개 존재하는 이유가 분명히 있지 않을까? 조금의 차이라도 분명히 있을 것이다. 다음 링크를 참조하라.
[작성중]
**
String nextToken()
String nextToken(String delim)
Object nextElement()
다음 토큰을 반환하는 메소드들이다.
String nextToken() 메소드는 다음 토큰을 반환한다. 반환형은 String 이다.
String nextToken(String delim) 메소드는 매개변수로 주어진 "delim"을 기준으로 주어진 문자열을 다시 분리한다. 단, 이전에 주어진 문자열을 이미 분리했다면, 처음에 주어진 문자열을 처음부터 다시 분리하지 않고 분리 이후의 문자열을 다시 새로운 "delim"을 기준으로 분리한다. 역시 반환형은 String 이다.
이해가 어렵다면, 다음 예제를 보자.
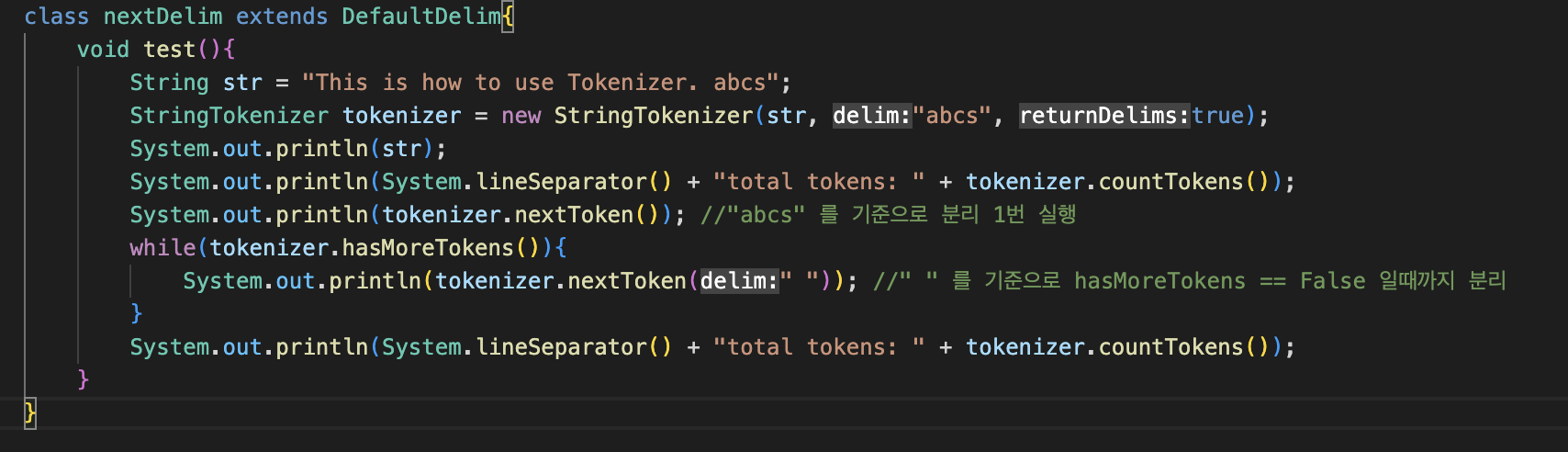
결과
This is how to use Tokenizer. abcs
total tokens: 11
Thi
s
is
how
to
use
Tokenizer.
abcs
total tokens: 0"This is how to use Tokenizer. abcs"라는 문자열을 분리한다.
이때, System.out.println(tokenizer.nextToken()); 에 의해 "abcs"라는 delim을 기준으로 한번 분리한다 -> Thi / s
그 이후, 반복문의 System.out.println(tokenizer.nextToken(" ")); 에 의해, "is how to use Tokenizer. abcs" 문자열이 " "(공백 1칸)을 기준으로 분리되었다.
예제
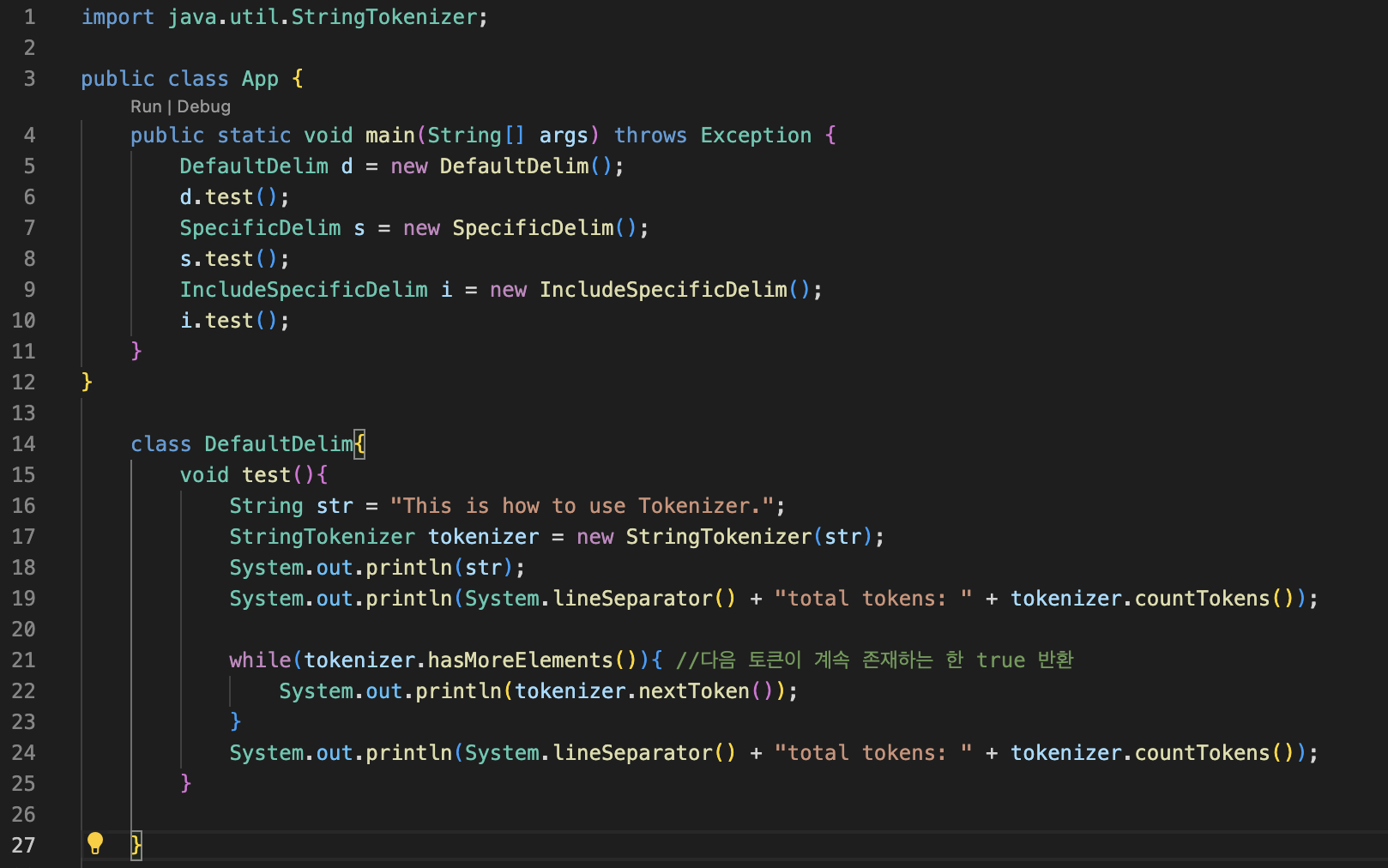
위 생성자와 관련한 d.test() 실행결과는 다음과 같다.
total tokens: 6
This
is
how
to
use
Tokenizer.
total tokens: 0
This is how to use Tokenizer.예외 : NoSuchElementException - tokenizer의 문자열에 토큰이 더 이상 없을 경우
NullPointerException - delim 이 null 일 경우
split() 메소드와의 비교
StringTokenizer vs split() | 메모리 효율성
일반적으로 split()가 더 직관적이고 유연성이 높다. 그러나 정규식을 사용하지 않아도 분리가 가능한 경우에는, StringTokenizer가 더 효율적인 메모리 관리를 위해 사용될 수 있다.
split() 메소드는 문자열을 분할할 때마다 정규식을 사용하기 때문에, 매번 정규식 엔진을 초기화하고 실행해야 한다. 이는 메모리 사용량과 실행 시간을 더 많이 소모하게 만들어서, 문자열이 길고 분할되는 횟수가 많을수록 성능이 떨어질 수 있다.
또한 문자열을 분할하는 과정에서 새로운 문자열 객체를 생성해야 하므로 메모리 사용량이 더 많아질 수 있다.
반면에 StringTokenizer 클래스는 정규식을 사용하지 않으므로, 분할 작업을 더 빠르게 처리할 수 있다. 또한, StringTokenizer 클래스는 내부적으로 버퍼링(buffering) 기능을 제공하며, 이를 통해 메모리를 더 효율적으로 사용할 수 있다. 즉, 토큰을 생성할 때마다 새로운 문자열 객체를 생성하지 않고, 이미 생성된 문자열 객체를 재사용한다.
split()보다 2배나 빠른 StringTokenizer
split()과 StringTokenizer의 성능을 비교한 결과가 있다.
https://www.javamex.com/tutorials/regular_expressions/splitting_tokenisation_performance.shtml
테스트 환경은 [2GHz Pentium running JDK 1.6.0 under Windows]
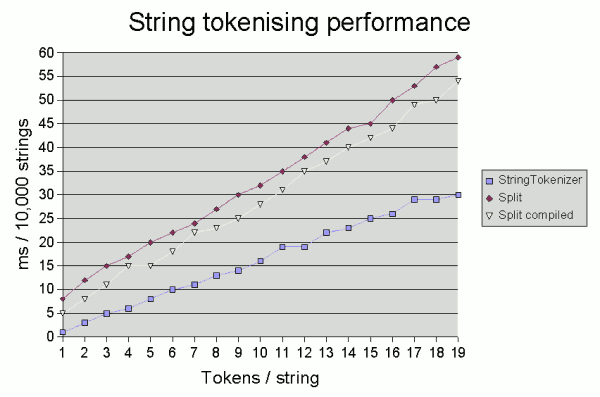
랜덤으로 생성된 5자의 1만개의 무작위 문자열을 분리한 결과이다.
StringTokenizer가 split()에 비해 약 두배의 성능을 보인다.
그럼에도, split()을 사용하는 이유
StringTokenizer의 한계
StringTokenizer는 문자열을 간단하게 분리할 수 있지만, 정규식 등을 사용하여 더 복잡한 문자열 처리를 해야하는 경우 StringTokenizer로는 한계가 있다. 이 경우, java.util.regex 패키지에서 제공하는 정규식을 사용하거나, String 클래스의 split() 메서드를 사용하는 것이 더 적합할 수 있다.
메모리 효율성 측면에서, 일반적인 상황에서 StringTokenizer가 더 좋은 것은 맞다. 하지만 split()은 StringTokenizer보다 더 유연하고, 사용하기 쉽다.
StringTokenizer는 Java가 정규 표현식을 지원하기 이전의 클래스인 반면, split()은 정규 표현식 또한 지원한다. 그리고 split()의 반환값은 일반적으로 우리가 많이 원하는 문자열 배열이다.
성능 차이도 딱히..
성능도, delimeter를 단일 문자 범위로 좁히면, 거의 동일하다.
작은 성능을 위해 추가 코드를 더하는 것을 메리트도 없을 뿐더러, split()또한 충분히 빠르다. 위의 비교 결과에서도, 1만개의 문자열을 처리하는 데에 split()은 사실 60밀리초 밖에 걸리지 않았다.
StringTokenizer는 레거시 코드(Legacy Code)이다
StringTokenizer is a legacy class that is retained for compatibility reasons although its use is discouraged in new code. It is recommended that anyone seeking this functionality use the split method of String or the java.util.regex package instead.
자바 공식 문서에서도, 새로운 사용을 권장하지 않지만, 호환성을 이유로 유지되는 레거시 클래스라고 한다. 이 기능을 이용하려면 java.util.regex 패키지를 이용하라고 한다.
나와 같은 생각을 가진 분이 계셨다.
"StringTokenizer의 내부에 구현된 함수 및 로직들이, 구분자(delimeter)와 문자열을 일일이 비교하고, 구분자가 유니코드 일 경우, hasMoreToke 혹은 nextToken 호출 시, 문자열과 구분자 전체를 비교하는 로직이 있어, 효율이 좋지 못하다.
따라서, StringTokenizer에 여러 구분자를 세팅하고, 구분자가 유니코드인 경우, hasMoreToken이 잦을 수록, 성능이 확 나빠질 수 있다는 것이다."
출처 : [StringTokenizer VS String.split] 누가 더 빠른가
StringTokenizer클래스 내부 메소드의 효율이 좋지 않은데에 비해, split()은 일정한 성능을 보인다고 한다.
더 자세하게 알고 싶으면 아래 글을 참고하면 된다.
java StringTokenizer : 생각보다 느릴까? 뜯어보자.
사실 StringTokenizer라는 클래스를 새로 알게 되어 간단히만 적을려 했는데, "split() 메소드랑 이거랑 무슨 차이지?" 라는 의문이 들어 계속 깊게 파고들게 됬다. 두 기능의 메모리 효율에 대해 스택오버플로우에서도 논쟁이 좀 있었던 것 같다.
원래 쓰고 있던 JVM, 메모리, hashcode() 관련 글을 써야 되는데... 결국 끝까지 파고들었다. 그래도 원래 쓰던 글과 달리 꼬리질문이 많지 않아 다행이다.
