[Udemy(유데미) 강의 후기] Apache Spark 와 Python으로 빅데이터 다루기

👀 1. 들어가며

글또('글쓰는 또라이가 세상을 바꾼다' 글쓰는 개발자 모임)에서 유데미의 강의 쿠폰을 제공받아 강의를 들을 수 있는 기회가 생겼습니다. 많은 강의 중에 최대 2개를 선택할 수 있었는데, 그 중 하나로 'Apache Spark 와 Python으로 빅 데이터 다루기'강의를 선택했습니다.

'Apache Spark 와 Python으로 빅 데이터 다루기' (강의 소개 페이지)는 Spark와 Python을 함께 배우는 강의로 20개 이상의 실제 예시를 제공한다는 점이 마음에 들어 선택했습니다. 이 글에서는 강의 구성 소개와 강의 중 좋았던 점과 아쉬웠던 점을 다뤄보려고 합니다. 강의 후기가 궁금하신 분이 읽으시면 도움이 될 것 같아요
🖥️ 2. Apache Spark 와 Python으로 빅 데이터 다루기
2.1. 강의 소개
'Apache Spark 와 Python으로 빅 데이터 다루기'는 8개의 섹션, 66개의 강의로 구성돼있습니다. 총 길이는 6시간 55분이고, 가격은 99,000원입니다. (유데미를 처음 수강한다면 쿠폰 적용이 가능한지 확인해 보시길 바랍니다. 쿠폰 적용시 할인을 받아 수강 가능합니다!)

이 강의는 Windows에 Spark를 설치는 것을 기준으로 설명해주고 있어요. 저는 Windows를 사용해서 이 강의를 들어서 문제가 없었는데, 만약 Mac등 을 사용하시면 강의 듣기 전에 Spark 설치 방법 등을 확인해보시길 추천드려요. 그리고 이 강의는 실습 위주의 강의예요. 강의의 좋았던 점과 아쉬웠던 점에 언급 할 예정이지만, 이론 위주 강의를 원하시는 분은 원하시고 기대하시는 내용이 아닐 수 있어요. 또 Python을 사용해서 Python을 처음 사용해보신 다면 실습을 따라가기 어려우실 수 있어요.
2.2. 학습 방법
강의는 실습 위주로 진행되서, 실습에 사용될 데이터와 코드를 제공합니다. 저는 데이터와 코드를 한 번에 다운 받아두고 Visual Studio를 사용해서 강의 내용은 Markdown형식으로 기록해두고, 코드에 대한 설명은 주석으로 기록하면서 들었어요!
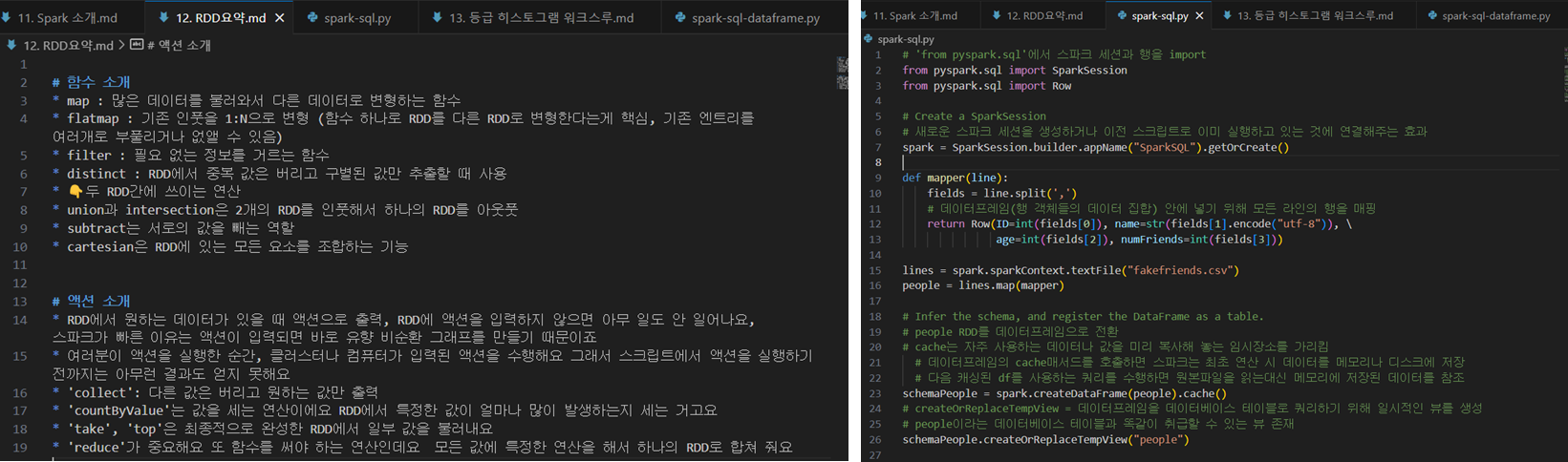
2.3. 아쉬웠던 점과 좋았던 점
아쉬웠던 점과 좋았던 점을 소개할게요!
먼저 아쉬웠던 점입니다!
- 강의는 실습 위주여서 이론 설명이 자세하고 길지 않았어요. 개념에 대해 자세히 설명을 듣고, 그 개념이 활용된 예시를 파악하고 실습을 진행하는 흐름의 강의에 익숙하던 저로서는 처음에 적응하기가 어려웠습니다. 만약 저처럼 이런 흐름의 강의에 익숙하시고, 이런 흐름을 기대하시고 들으신다면 원하시는 방향이 아니실거예요. 이 강의는 이런 함수가 있다 정도만 개념 설명 때 소개하고 실습 때 반복되는 문제들에서 그 함수가 어떻게 동작하는지를 설명하는 방식인데요. 저도 강의가 어떻게 동작하는지 파악하기 전에는 강사님이 가볍게 설명한 개념을 완전히 이해하고 넘어가려고, 어떻게 활용되는지 검색도 해보고 다른 블로그도 참고하면서 진행했어요. 이 과정이 스터디 할 때 도움은 됐지만, 강의 진도가 너무 안나가고 느려서 이대로는 안되겠다 싶더라구요😓 일단 이런 함수가 있구나라고 넘어가고 계속해서 나오는 실습 때 그 함수를 사용하니 익숙해지고 이해가 되니 일단 강의 진도를 나가시는 것을 추천드려요!
- 한국 강의는 인프런 등 잘 설명된 PPT로 구성된 경우가 많잖아요. 외국 강의와 실습 위주 다 보니 강의 자료가 우리가 계속 봐오던 기대하는 모습이 아니예요. 강의 자료만 봐도 강의의 흐름과 개념 이해가 다 되는 친절한 자료가 아니기도하고, 영어 강의과 한국어 자막과 강의 자료를 모두 파악하면서 듣기 쉽지 않아요. 이 부분이 적응이 안될 수 있는데요. 저는 유데미에서 제공하는 대본 기능을 활용하니 도움이 많이 되더라구요. 대본은 우측 하단의 버튼을 클릭하면 확인 할 수 있는데요. 자막 전체를 확인 할 수 있고, 지금 강사님이 말하고 있는 부분도 보라색으로 표시되서 문맥을 파악하면서 강의를 들을 수 있어요! 저는 어려운 부분은 한 번 강의를 듣고, 대본 기능을 읽으면서 정리를 했어요. 대본 기능을 잘 활용하면 이해하고 흡수하는데 도움이 되실 겁니다!

좋았던 점입니다.
- 실습 위주 강의답게 예시가 정말 많다는 점이 좋았습니다. 저는 이전에 Spark SQL만 다뤄본 정도 였는데요. 강의를 통해 다양한 상황의 예시를 접할 수 있어 좋았어요. 실무에서도 내가 자주 사용하는 함수나 쿼리를 모아두면 적재적소 상황에 가져다쓰면 업무도 빨라지고 효율적이잖아요. 여러 상황의 코드를 제공해주고 있어, 비슷한 상황에 가져다 써야겠다는 무기고를 채운 것 같아요.
- 뿐만아니라 강의 구조도 학습에 도움이 많이 됐어요. 강의는 다양한 활동으로 예시 상황을 보여준 뒤 연습할 수 있는 상황을 제공해줍니다. 각 예시는 어떤 문제를 풀어야하고 데이터 구조는 다음과 같다고 설명하면서 시작하고, 강사님은 문제를 푸는 코드에 사용된 함수나 결과를 차근차근 설명해줍니다. 특히 여기서 이전에 개념 설명에서 간단히 다뤘던 함수를 반복해서 설명해주시는 것이 이해에 도움이 됐어요. 그렇게 강사님이 몇가지 활동을 설명해준 뒤에는 특정 문제 상황과 데이터의 구조를 설명해주고 연습하는 시간을 가지게해요. 본인이 직접 문제 상황을 어떻게 해결할지 이전에 배운 활동들로 코드를 짜보게 하는 건데요. 이전에 배운 활동들로 충분히 해결할 수 있는 난이도의 문제를 제공해주고, 직접 코드를 짜면서 문제를 풀어보고 이 상황을 어떻게 해결할지 사고할 수 있도록 해줘서 도움이 많이 됐습니다! 실습 강의 중에서 실습 코드만 제공해주는 경우도 있는데 이 강의는 꼭 중간에 멈춰서 연습 문제를 풀어보도록 하고 있어 좋았어요.

🙌 3. 정리하며
유데미에서 Apache Spark 와 Python으로 빅 데이터 다루기를 듣고 좋았던 점과 아쉬운 점을 소개드렸는데요. 개념보다는 실습으로 일단 부딪히며 시작해보고 싶은 분이시라면 들어보시길 추천드려요!
※ 해당 콘텐츠는 유데미로부터 강의 쿠폰을 제공받아 작성되었습니다.
📑 참고 자료
