서울대학교 차세대데이터 여름학교 2025 단기 특강
Some History, Hardware Lottery
-
AI winter for Neural Networks :
- 원래 Neural Networks는 지금 hype 된 것보다 성능이 훨씬 별로였다
-
Marvin Minsky (1969) : “Nerual Networks” cannot learn the XOR relationship .. only linearly separable problems … and become too large for complex knowlege
→ 하지만 Single layer이 아닌 “Deep” neural network의 학습이 가능한 하드웨어적 기반이 마련되면서 NN의 성능 비약적 향상
-
- 원래 Neural Networks는 지금 hype 된 것보다 성능이 훨씬 별로였다
-
The Hardware Lottery :
- Sara Hooker이 Communications of the ACM, 2021에 주장한 개념. GPU의 발달으로 DNN이 AI 핵심 기술로 거듭난 것에 대한 설명
Some ideas win, not because they are better, but because they work better with existing hardware
- Hardware Lottery Winners: General-Purpose CPU Threads
- chip의 집적도가 증가한다는 Moore’s Law + chip 성능 향상에도 power density가 일정하게 유지된다는 Dennard Scaling = Dependable performance scaling
- 위와 같이 Moore’s Law와 Dennard Scaling이 건재할 때에는 미래에 더 빠른 general-purpose hardware(cpu)가 등장할 것이므로, 굳이 (gpu와 같은) 특화된 specific-purpose hardware을 개발할 필요가 없었다. → Resources focused on making general purpose CPUs faster
- 이러한 Von-Neumann general-purpose CPU는 :
- not very good with parallel execution 병렬 계산 별로 X & not much emphasis on memory bandwidth 메모리 접근 속도도 별로 X
- Thus, efficient with branch-heavy expert systems : favors symbolic approaches to AI (LISP, Prolog)
- But inefficient with neural networks with massivel parallel matrix multiplication! → 즉 hardware lottery losers: nerual network
- not very good with parallel execution 병렬 계산 별로 X & not much emphasis on memory bandwidth 메모리 접근 속도도 별로 X
- Hardward Lottery Losers: Nerual Nets and the AI Winter
-
general-purpose CPU 기반 연구에 집중하다 보니, 원래의 하드웨어가 잘 수행할 수 있는 symbolic approaches에만 집중. Neural net은 cpu로 학습시키기 너무 비효율적이었고 학습을 위한 cpu 여력이 부족하기도 했다.
-
Neural Network 이론 자체는 이미 등장했지만, lost the hardware lottery (cpu로 학습시키기 힘듦) → AI winter
-
NN을 위한 특화된 하드웨어를 개발하기 위한 벤처 기업들이 등장하긴 했지만(e.g. “connection machine”, 1985) 흐지부지됨
→ 그런데 어떻게 NN이 이렇게 승승장구 할 수 있었는가?
바로 다른 것도 아닌 Video game 때문!
-
- Sara Hooker이 Communications of the ACM, 2021에 주장한 개념. GPU의 발달으로 DNN이 AI 핵심 기술로 거듭난 것에 대한 설명
-
요약 : AI 흐름과 별개로 Video game 업체에서 3D 그래픽 게임에 대한 수요가 점점 높아지며, 이를 구현하기 위한 하드웨어 개발이 진행되며 3D Accelerator card, 그리고 gpu가 당연한 수순처럼 등장했다.
-
Graphic Processing History
-
1990’ : 게임을 위한 Real-time 3D rendering 보편화 (Doom, Quake, Descent, … ) + 3D 그래픽 처리가 점점 컴퓨팅 연산 많이 필요
3D accelerator(gpu)가 도입되기 전에 cpu의 연산으로 감당할 수 있는 게임 그래픽을 구현할 수 있도록 하는 gimmick들이 있었다
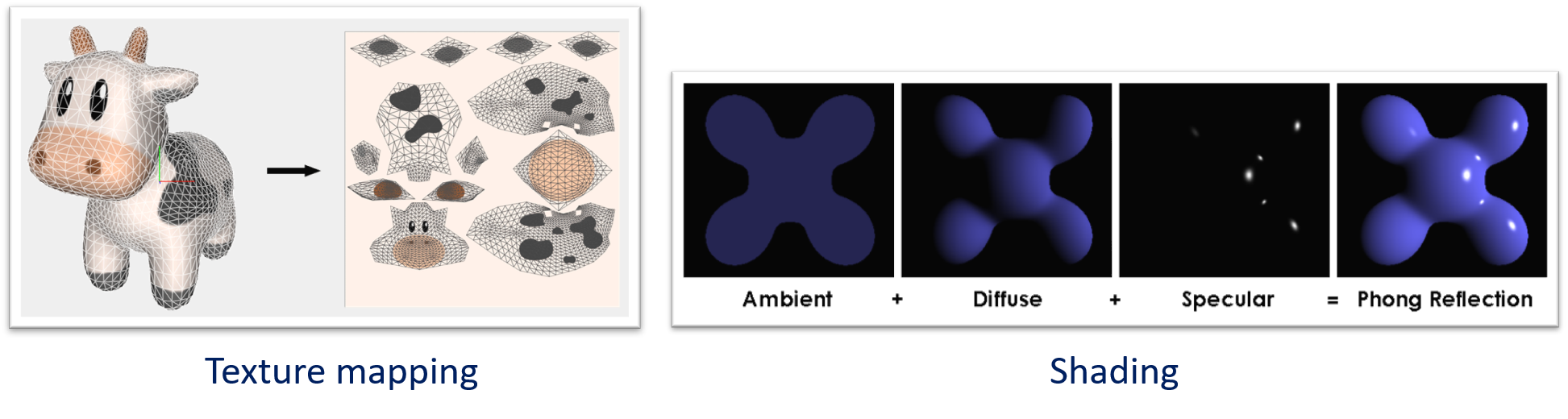
- Doom (1993) : “Affine texture mapping” → linearly maps textures to screen location (3D model → 2D space), disregarding depth; 게임 내 비스듬한 평면이 없었던 이유는 이를 가리기 위해
- Quake III arena (1999) : “Fast inverse square root” → 3d graphic에 필요한 연산을 우회적인 연산식으로 수행 (magic!)

- Doom (1993) : “Affine texture mapping” → linearly maps textures to screen location (3D model → 2D space), disregarding depth; 게임 내 비스듬한 평면이 없었던 이유는 이를 가리기 위해
-
그러다가 Starfox(1993)에서 처음으로 dedicated accelerator (전용 가속기 칩) 등장
-
가정용 게임기에서 처음으로 3d 그래픽을 구현한 super Fx chip : 게임기 안에 cpu를 하나 더 넣은 것이라 생각할 수 있음 (16-bit RISC processor + some plotting commands, Dynamic Memory Access)

-
DMA; Dynamic Memory Access 가벼운 설명
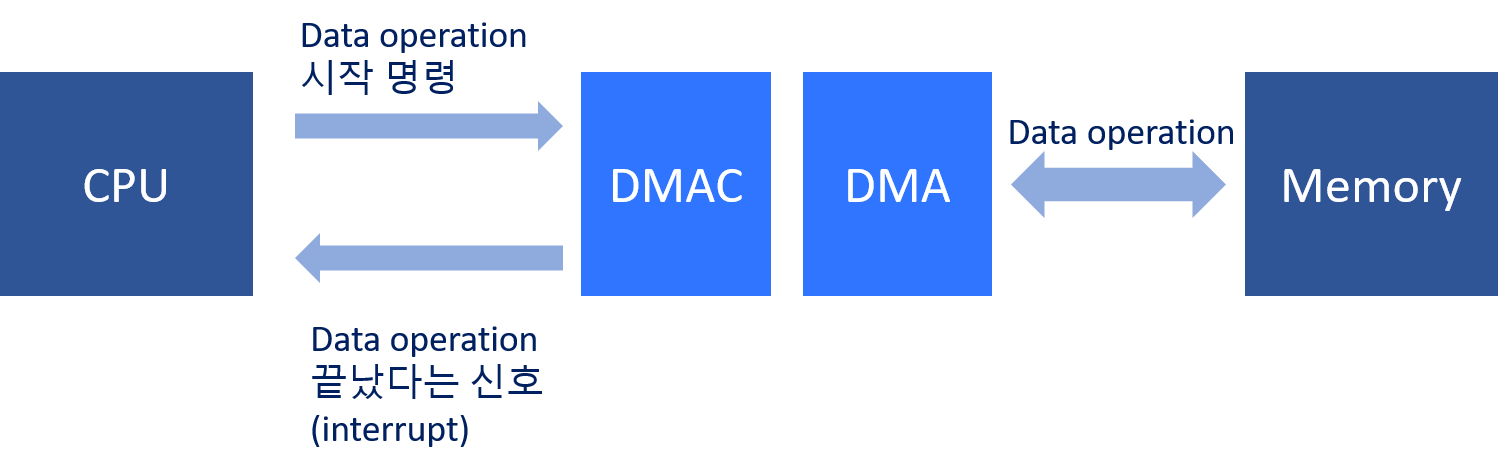
Dynamic Memory Access; 즉 DMA unit이 CPU와 독립적이게 메모리 작업을 할 수 있게 하는 구조
CPU는 DMAC, 즉 DMA control unit을 통해 메모리 작업 시작 명령을 내리고 다른 작업을 하다가 DMAC에서 작업 완료 신호를 받을 수 있음.
-
-
-
Introduction of 3D Accelerator Cards :
→ 3D 게임에 대한 수요가 많아지며 3D Accelerator card가 당연한 수순처럼 등장
3D 그래픽 처리는 많은 양의 데이터를 반복 처리하는 짧은 알고리즘 → 전용 가속기accelerator에서는 단순 연산을 빠르게 병렬적으로 계산해 줌.
기본 원리 : 그래픽 카드에서 렌더링의 많은 연산을 대신 해준 후 모니터로 보내는 방식
-
→ 요컨대 AI를 빼어놓고 보아도 graphic card, gpu의 등장은 게임 측면의 marketing pressure에 의한 당연한 수순이었다!
- 단순 병렬 연산을 수행하는 core의 개수가 많아지고, 그에 비해 cache/control이 차지하는 비율은 ↓

-
High-Performance Graphics Memory
-
100K+ threads place enormous pressure on memory!
→ gpu의 많은 연산 thread를 위해 효과적으로 빠른 메모리 필요
-
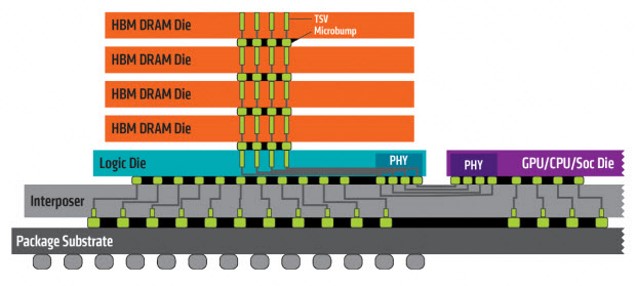
Modern GPUs empoy 3-D stacked memory via a silicon interposer
→ 이런 HBM (High-Bandwidth Memory) 구조는 더 넓은 data bus를 제공함으로써 이런 문제 방지
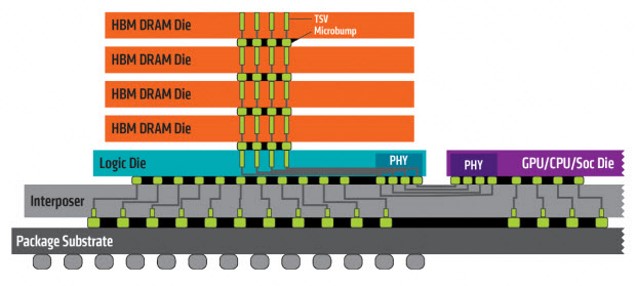
e.g. HBM2 in Volta, Ampere, etc
→ HBM2도 AI 이전 게임 때문에 등장
-
-
Thus New Hardware Lottery Winners : GPUs
→ 이렇게 공교롭게 3D 게임을 위해 등장한 GPU가 nerual network를 가능하게 함
→ gpus originally designed for gaming; massively parallel; high memory bandwith; re-purposed for training.
-
CNNs and GPUs → perfect match!
⇒ CNN은 동일한 matrix multiplication(multiply-add) 연산을 필요로 하므로 GPU로 병렬 연산하기 좋음
- two papers using CNNs to identify cats :
-
“Building high-level features using large scale unsupervised learning”(2012) : 16000 cpu 사용
-
“Deep learning with COTS HPC systems”(2013) : two cpu cores + two gpus 사용
→ 둘의 결과가 맞먹을 정도로 gpu의 위력이 대단했다!
-
- “what other ideas are we missing due to the hardware lottery?”
- 좋은 idea인데도 실현가능한 하드웨어가 없어서 놓치고 있을 수도 있음
- 좋은 idea인데도 실현가능한 하드웨어가 없어서 놓치고 있을 수도 있음
- two papers using CNNs to identify cats :
-
Yet another lottery winners : specialized hardware
- DNN에 더욱 최적화된 하드웨어 개발 진행 : tensore cores in GPUs, bfloat units in CPUs, TPUs …
-
Quantizied arithmetic, unstructured pruning 등 dnn 외에는 적용할 게 없는 매우 specific 것들도 하드웨어 개발에 적용
→ 이런 specialized hardware은 더욱 큰 AI 모델을 가능하게 함(더 많은 파라미터)
-
- DNN에 더욱 최적화된 하드웨어 개발 진행 : tensore cores in GPUs, bfloat units in CPUs, TPUs …
-
Yet another lottery losers : Non-DNN Models
- 하지만 DNN만큼 복잡한 대안 알고리즘이 TPU/GPU로 training 가능하지 않다면; 실현가능하지 않으므로 역사의 뒷전으로 빠짐 … (e.g. “capsule network”)
- 다른 예시 graph nerual network : convolutions on graph-structure data, reasoning about non-euclidean data structure → graph data는 주로 매우 sparse하기 때문에 accelerator/gpu에 잘 맞지 않음
- 다른 예시 graph nerual network : convolutions on graph-structure data, reasoning about non-euclidean data structure → graph data는 주로 매우 sparse하기 때문에 accelerator/gpu에 잘 맞지 않음
- 하지만 DNN만큼 복잡한 대안 알고리즘이 TPU/GPU로 training 가능하지 않다면; 실현가능하지 않으므로 역사의 뒷전으로 빠짐 … (e.g. “capsule network”)
-
Thus ; researchers will gravitate towards models/algorithms well-suited for GPU/TPU/Matrix multiplication since it is the most feasible
→ what great ideas are we missing because they lost the hardware lottery?
