🔖 Introduction to Amazon Athena
😵💫 기존의 어려움
- S3 자체는 분석하는 툴을 가지고 있지 않아, 데이터를 분석하기 위해서는 Hadoop 클러스터나 Redshift 클러스터를 깔아 데이터를 불러오고 쿼리를 날려야 했음
📢 Amazon Athena
Athena는 서버리스 분산 쿼리 엔진
- S3에 저장된 데이터 한해서 처리
- 3가지 키워드 :
분산,SQL 쿼리,S3
🧐 Athena를 왜 사용할까?
- 데이터를 저장하는 저장 공간과 실제 쿼리를 수행하는 쿼리 엔진을 분리하여 athena를 제공
- 서버를 설치하거나 클러스터를 구성하는 작업 없이 서버리스 서비스로 제공
=> 관리와 사용이 편리 - 데이터를 처리하는 방식이 데이터를 읽어올 때 스키마를 정의해서 사용
=> 데이터를 넣을 때 스키마를 고려하지 않아도 되고 이미 저장된 데이터가 있다면 바로 분석
💸 Simple Pricing
- DDL operation - FREE
- SQL operation - FREE
- Query concurrency - FREE
- Data scanned - $5/TB
- S3에서 get이나 push 같은 데이터와 읽을 때 과금 발생
🔖 Athena in Action
Create External Tables
- Athena는 쿼리 엔진과 Storage가 분리 => 실제 쿼리 엔진 입장에서는 데이터의 스키마를 알 수 없음=> S3에 저장된 데이터에 대한 스키마를 정의(external table)
- athena에서 데이터 테이블을 삭제한다고 해서 실제 데이터가 S3에서 삭제되는 것은 아님
- S3에 이미 저장된 데이터를 해석하는 방법을 정의=> 읽을 때 스키마를 정의(Schema-on-read)
👨💻 Navigate to ‘Saved Queries’ to get DDL
👨💻 How to execute query?
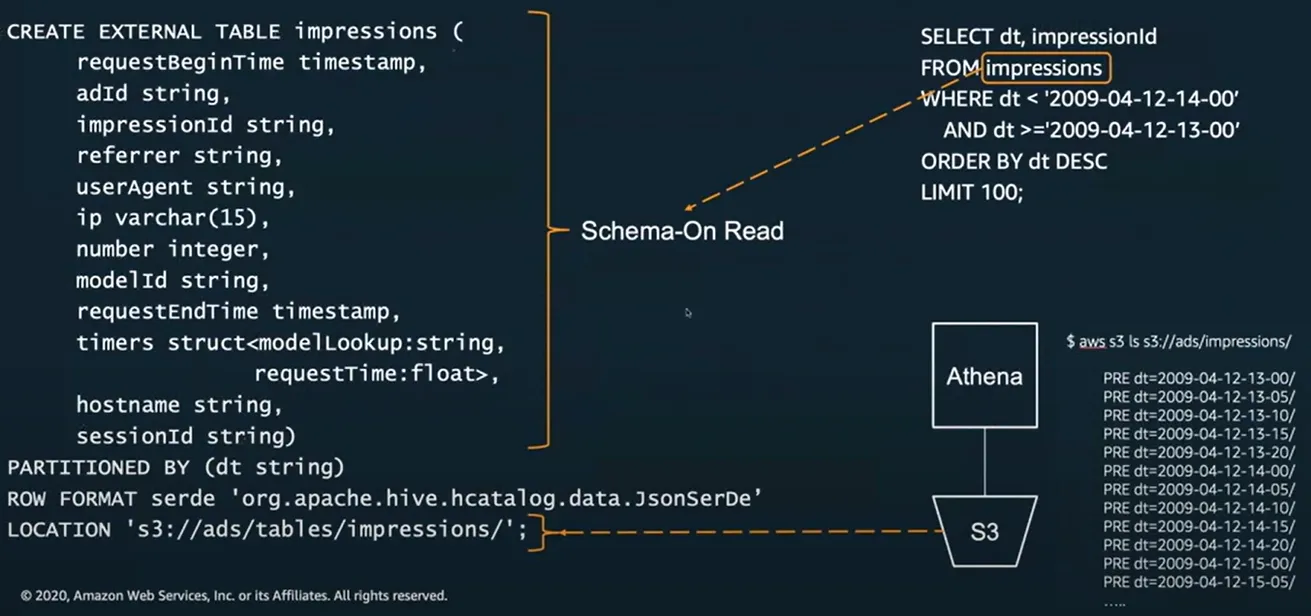
create external table에서 중요한 것은 스키마 내용과 어디에 저장되는지- 먼저 데이터 스키마를 정의
- 쿼리를 수행할 때 dt와 impresison이 어디에 있는지, 어떤 타입인지 알 수 있음
- 쿼리를 수행할 때 어디에 저장할지(S3) 표시
👨💻 Partitions
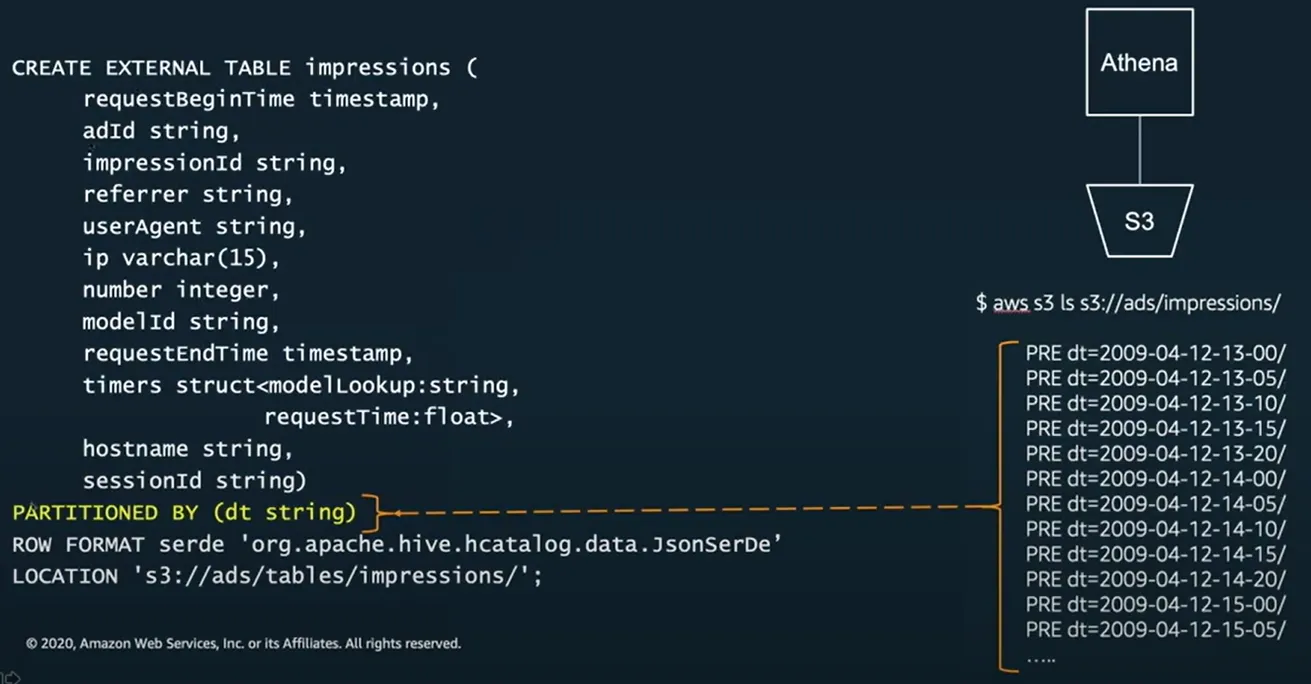
- 데이터를 저장할 때 S3에 파티션 방식으로 저장
- 파티션은 폴더 같은 것
- 시간 순 데이터나 실시간 데이터를 시간 단위로 잘라 특정 폴더에 저장
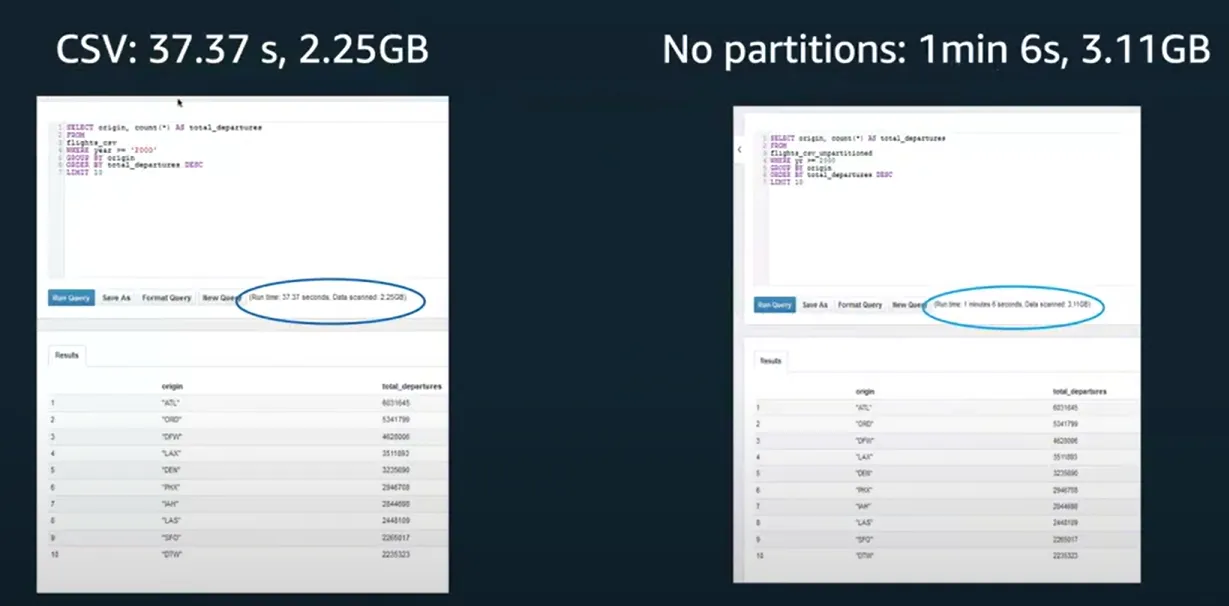
Where year>=2000: 파티셔닝을 하게 되면 Athena에서는 2000년 이전의 데이터를 아예 보지 않음
📑 reference

어쩌다보니 데이터쟁이