▶️ 원본 영상: https://youtu.be/eKLvaOJ3c5Q
🔖 Spark Runtime Architecture
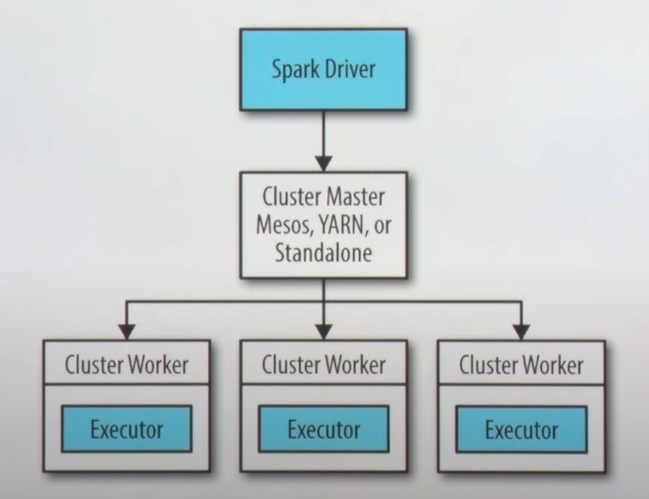
- 스파크 드라이브에서 메인 함수 실행, 스파크 세션 생성
- Spark Context = Spark Session
- spark submit으로 클러스터 매니저(Mesos, YARN, Standalone)로 job과 필요한 리소스(executor 개수, 코어 개수, executor 별 메모리) 요청
- 클러스터 매니저의 역할은 요청에 맞게 워커를 할당. 리소스가 없다면 spark submit을 뱉어버림
- 드라이버 프로그램의 스파크 세션 생성
- Spark Context = Spark Session
🔖 Spark runtime components
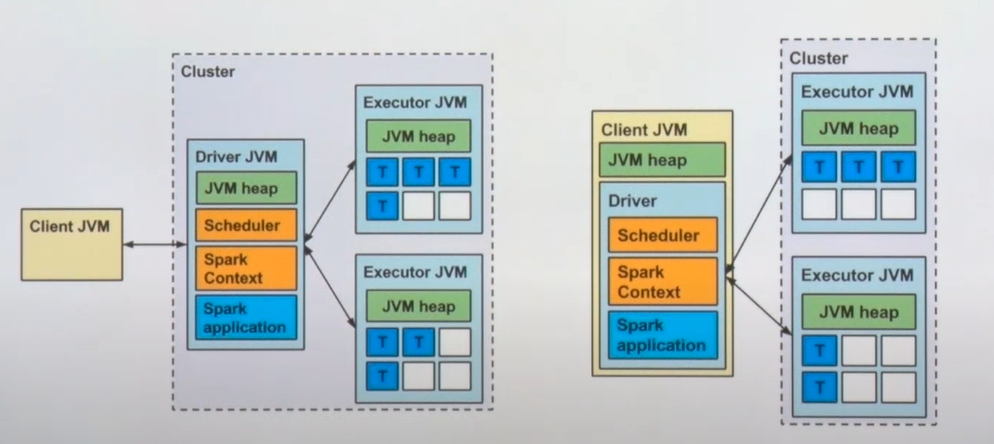
- 왼쪽: 클러스터 안에 드라이버가 포함
- 제약된 리소스를 공유
- 대부분의 애플리케이션들은 드라이버를 클러스터 안에 띄움. 드라이버 이슈가 발생하면 클러스터 매니저가 재구동해줌
- 오른쪽: 클러스터 바깥에 드라이버가 포함
- 전용 리소스를 점유해야하는 경우
🔖 Spark Driver
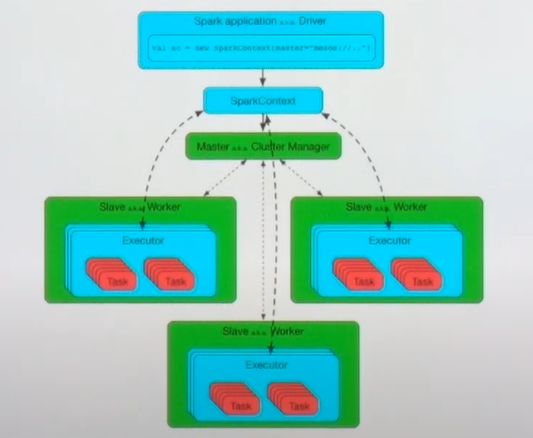
- Spark session 생성
- 클러스터 매니저에게 작업 할당된 executor에 대해서 어떤 태스크를 실행할 지
🔖 Terminology
- Driver: SparkContext(=Spark session)를 포함하는 프로세스. 메인 함수 포함. 실제로 동작하는 애플리케이션
- Executor: 실제로 스파크에서 병렬로 동작할 수 있도록 각각의 노드에 분산돼서 작동하는 프로세스
- Master: 어플리케이션을 매니지할 수 있는 프로세스.
- 클러스터 매니저의 구성(Yarn, Standalone 등등)에 따라 달라짐
- Work: 노드 단위.
🔖 Spark Deployment
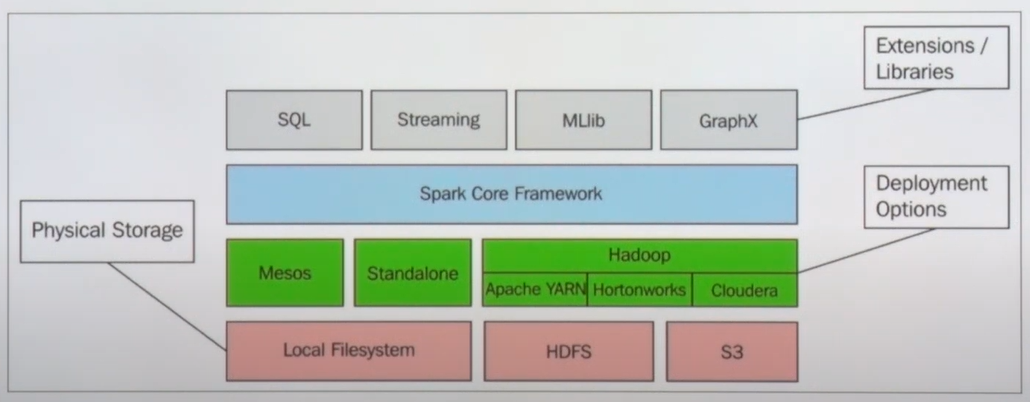
- shared storage, object storage, s3, HDFS, 로컬 파일 시스템
- 하둡에서는 Yarn을 사용
- 스파크만 사용하겠다 → Standalone
🔖 Cluster Management
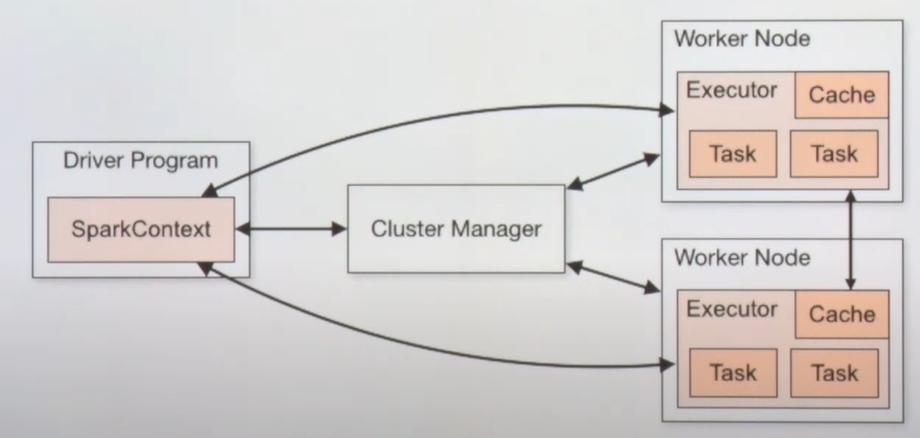
- 드라이버 프로그램은 SparkContext 생성
- 던진 코드는 각각의 worker executor들이 수행
🔖 Spark Deployement - Local Mode
./bin/spark-shell --master local[12]
./bin/spark-submiet --name "MyFirstApp" --master local[12] myApp.jarval conf = new SparkConf()
.setMaster("local[12]")
.setAppnAme("MyFirstApp")
.set("spark.executor.memory", "3g")
val sc = new SparkContext(conf)🔖 Spark Deployement - StandAlone Mode
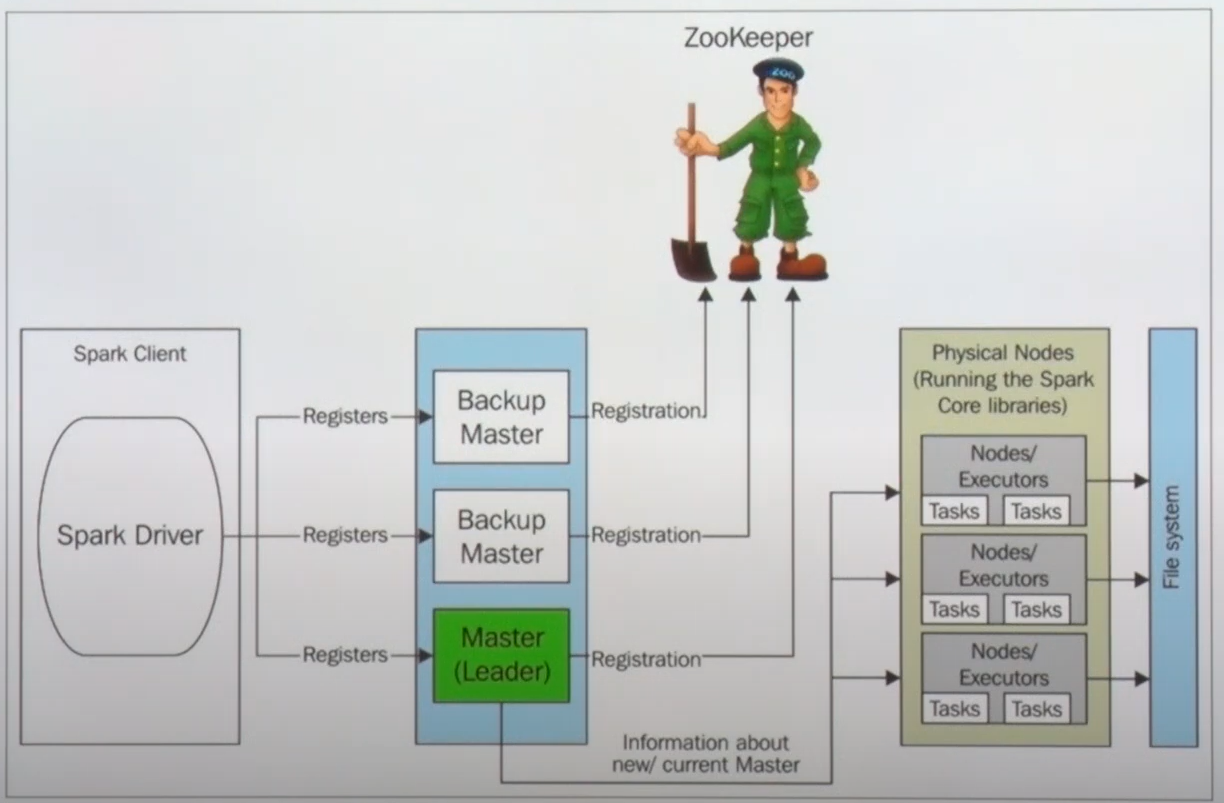
- 스파크 전용 구성: 노드들 전체 리소스를 사용. CPU, 메모리 전체 사용
- 주키퍼를 이용하여 마스터 이중화 관리를 주의해야 함
- YARN은 마스터 관리를 따로 해주기 때문. 마스터가 죽거나 다시 살리는 작업을 하지만 StandAlone 모드는 백업이나 리더를 지정하여 관리를 해줘야 함
🔖 Spark Deployement - Yarn Mode
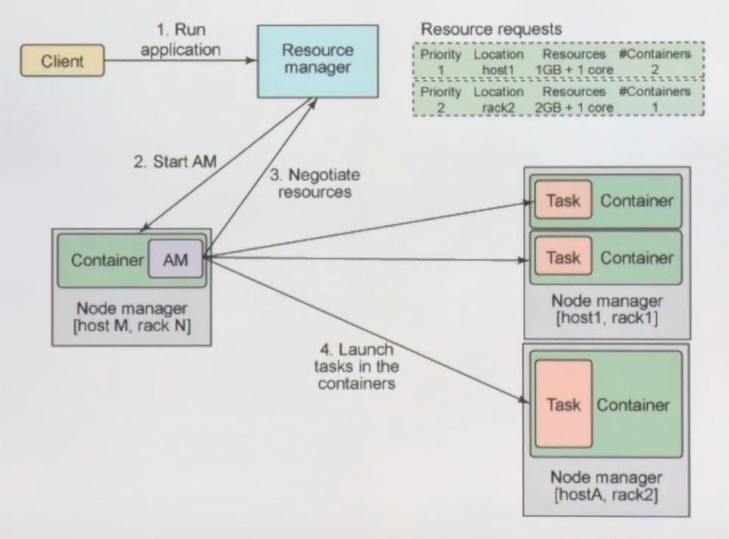
- YARN을 쓰는 목적은 다양한 어플리케이션을 사용
- YARN에서 전체 리소스 매니지먼트
- spark job을 요청하면 YARN에서 리소스를 확인하고 정보를 줌
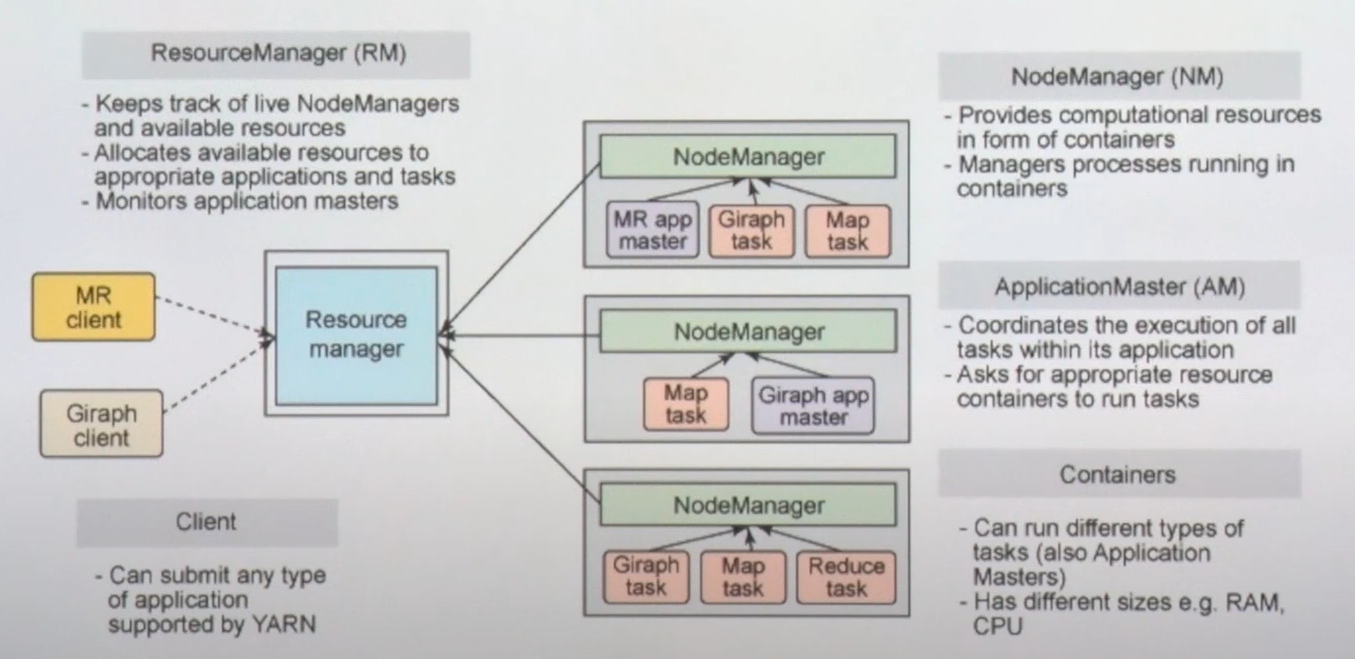
- 리소스를 요청하면 YARN의 리소스 매니저가 노드 매니저를 통해서 애플리케이션이 동작 될 수 있도록 할당
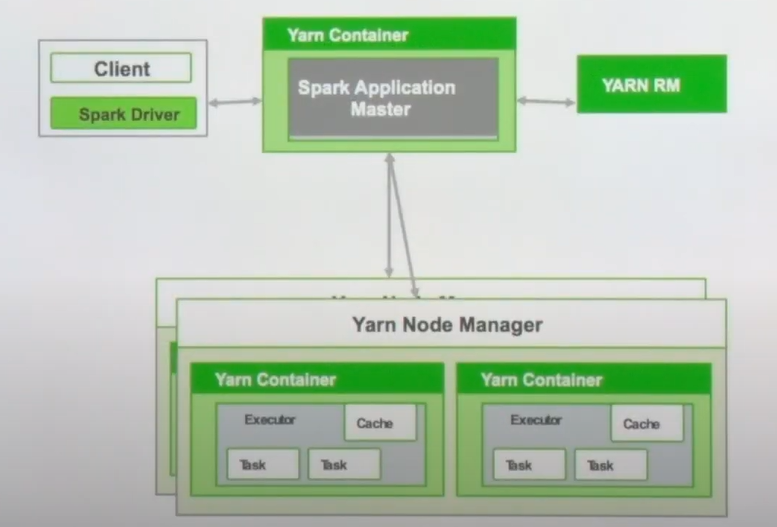
- 노드 매니저 안에 YARN 컨테이너로 구성
- YARN 컨테이너 안에는 executor가 실행. 캐시와 태스크 영역이 들어가 있음
- YARN mode
- YARN client mode: 드라이버가 밖으로 빼야한다면
- YARN cluster mode: 드라이버가 클러스터 내에서 실행할 수 있다면
🔖 Spark Deployment - Yarn Cluster
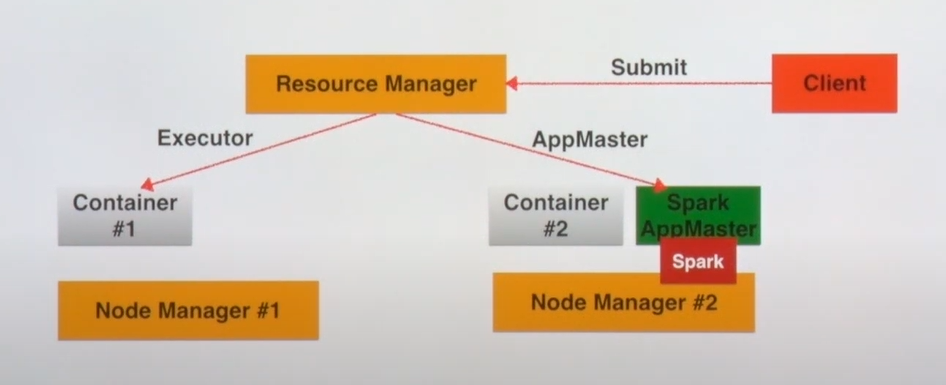
- 리소스 매니저로부터 스파크 마스터와 executor를 할당 받게 됨
🔖 Spark Deployement - Yarn Client
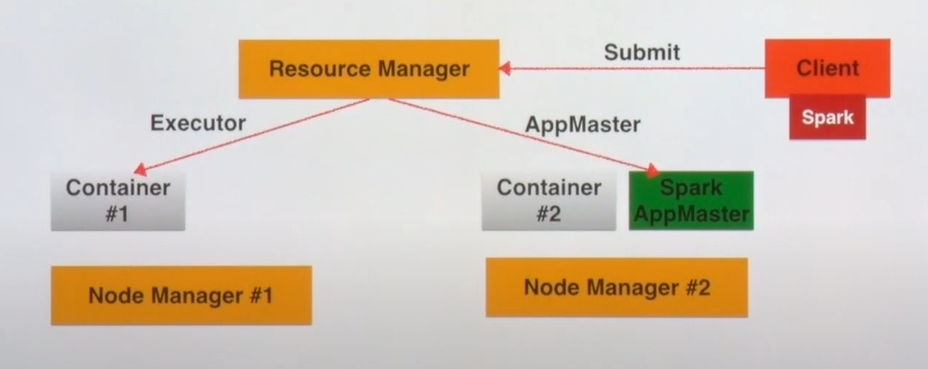
- 스파크 드라이버가 바깥의 클라이언트 쪽에서 로드
Spark Deployment - Running thrift server
sbin/start-thriftserver.sh
--master yarn \
--deploy-mode client \
--executor-memeory 30G \
--num-executor 60 \
--executor-cores 8 \
--driver-cores 12 \
--supervise \
--driver-memory 40G \
--name "thrift"- thrift 서버를 띄우면 JDBC, ODBC 연결이 가능
- 드라이버 쪽이 드라이버 thrift 서버가 됨
-> 드라이버가 executor에 비해서 많은 리소스를 점유해야 함
-> 드라이버 코어를 따로 설정하거나 클라이언트로 더 많은 자원을 드라이버에 주는 YARN client mode를 사용할 수 있음
🔖 Dynamic Resources Allocation on YARN
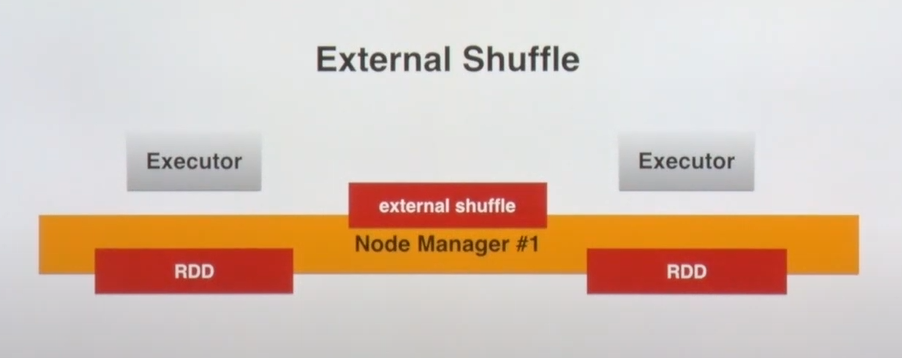
- exeternal shuffle을 사용하여 리소스의 할당을 워커노드에 따라서 scale-in/out
- scale out 하는 경우 수행하고 있는 RDD의 정보를 보내줘야 할 때 사용하는 것이 external shuffle
- 설정 방법
- shuffle plugin add jar
yarn-site.xmladd plugin
<property>
<name>yarn.nodemanager.aux-servies</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>- edit
spark-default.conf
spark.dynamicAllocation.enalbe true
spark.shuffle.service.enabled true
spark.dynamicAllocation.minExecutors 50
spark.dynamicAllocation.maxExecutors 100
spark.dynamicAllocation.ubutuakExecutors 50
spark.dynamicAllocation.cacheExecutorIdleTimeout 600Spark Deployment - Job Server
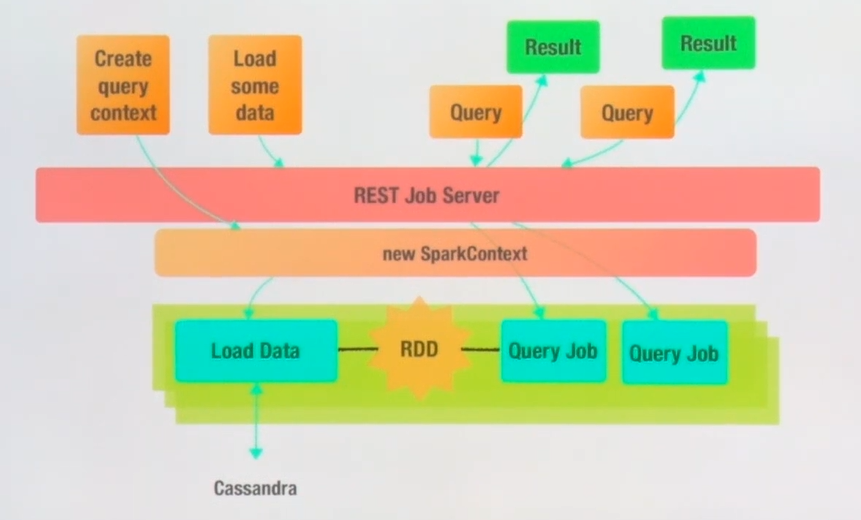
- YARN 기반으로 리소스 매니저를 사용하고 있고 매번 제출할 때마다 드라이버가 동작되면 SparkContext가 생성되고 executor 할당을 받아 job이 실행됨
-> 그러나 부트 타임이 걸림. SQL을 한번 실행할거지만 SparkContext가 여러 개 생성됨
-> 이를 해결 하기 위해 Job server 사용 - 하나의 SparkContext를 공유하여 여러 개의 쿼리를 처리
🔖 Spark with YARN on EMR
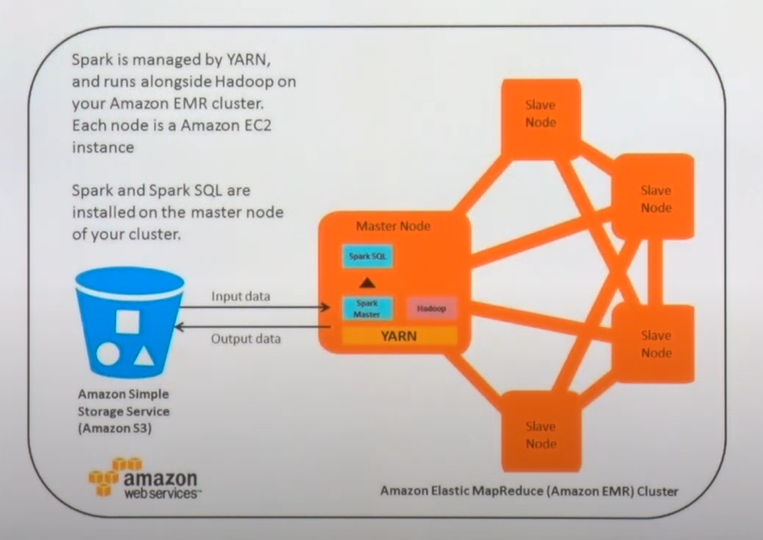
- S3에 데이터가 저장되고 데이터를 읽는 방식으로 진행
- EMR 노드에 있는 디스크는 temporary 영역으로만 사용, 물리적으로 저장되는 건 S3
🔖 Spark meet K8s
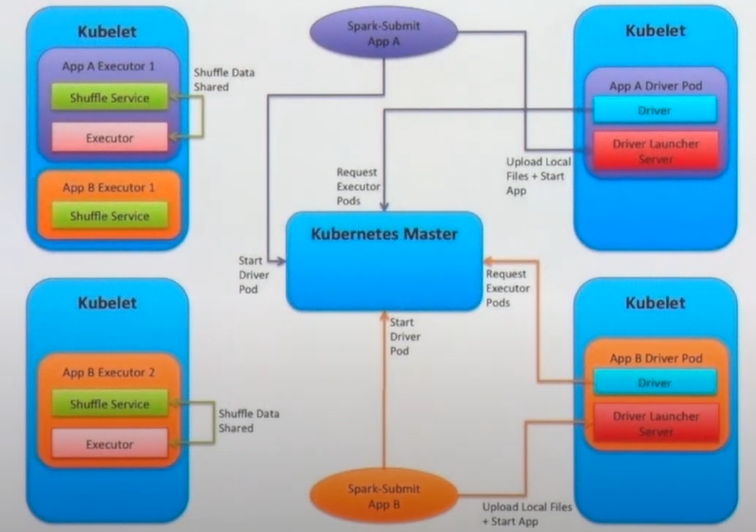
- 쿠버네티스 기반으로 스파크를 구동할 수 있음
- 쿠버네티스 파드(pod): 여러가지 프로세스를 띄울 수 있음. 셔플 서비스를 통해 스케일링 지원
- 쿠버네티스를 고려해볼 만한 케이스: ML 연산 작업 시 리소스를 많이 쓰거나 리소스를 해제 후 다시 받는 케이스가 많음
🔖 Design Choices
- Scala vs Java vs Python vs R
- 분석가는 pyspark 추천
- R은 R 서버에 의존적임
- Dataframe vs SQL vs Dtasets vs RDDs
- Dataframe: 가장 일반적인 인터페이스
- Dataset: 컴파일 타임 에러나 방어코드, 코드 제외 등등
- Object Serialization in RDDs(
spark.serializer to org.apache.spark.serializer.KryoSerializer) - Dynamic allocaiton:
🔖 Memory Pressure and Garbage Collection
- Measuring the impact of gargace collection
adding -verbose: gc -XX:+PrintGCDetails -XX: +PrintGCTimeStamps to Spark’s JVM options using the spark.executor.extraJavaOption configuration paramter
- Garbage collection tuning
- ry the G1GC garbage collector with
-XX:+UseG1GC - large executor heap sizes, it can be important to increase the G1 region size with
-XX:G1HeapRegionSize
- ry the G1GC garbage collector with
🔖 Parallelism
spark.default.parallelismspark.sql.shuffle.partitions
🔖 Temporary Data Storage(Caching)
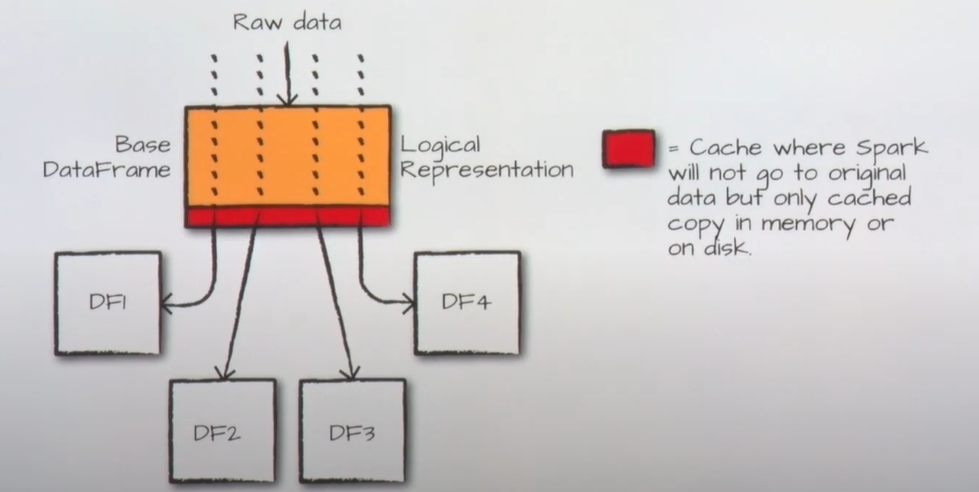
- raw data를 불러와서 처리하는 4개의 데이터프레임이 존재한다고 가정하자. 캐쉬로 해서 각각 executor 캐시 영역으로 올려버리면 데이터프레임은 저 캐시를 바라보기 때문에 raw data를 처음부터 읽지 않음
DF1 = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load("/data/flight-data/csv/2015-summary.csv")
DF2 = DF1.groupBy("DEST_CONTRY_NAME").count().collect()
DF3 = DF1.groupBy("ORIGIN_COUNTRY_NAME").count().collect()
DF4 = DF1.gruopBy("count").count().collect()
DF1.cache()
DF1.cont()
🔖 Data locality
- Data locality means close the data is to the code to be processed
| Data Locality | Meaning | Special Notes |
|---|---|---|
| ANY | 데이터가 어디에 있는지 모름 | 다른 옵션이 없는 한 권장되지 않음 |
| PROCESS_LOCAL | JVM에 이미 포함 데이터와 코드가 같은 위치에 있음 | locality가 가장 좋은 경우 |
| NODE_LOCAL | 해당 블락 해당 노드에 있음 | 네트워크를 타지 않고 디스크만 타면 됨 |
| RACK_LOCAL | 노드에는 없지만 같은 RACK에는 있음 | 내부 I/O만 사용 |
| NO_PERF | 어디서든 동일하게 접근 가능 | has no locality preference |
🔖 Resource management using YARN
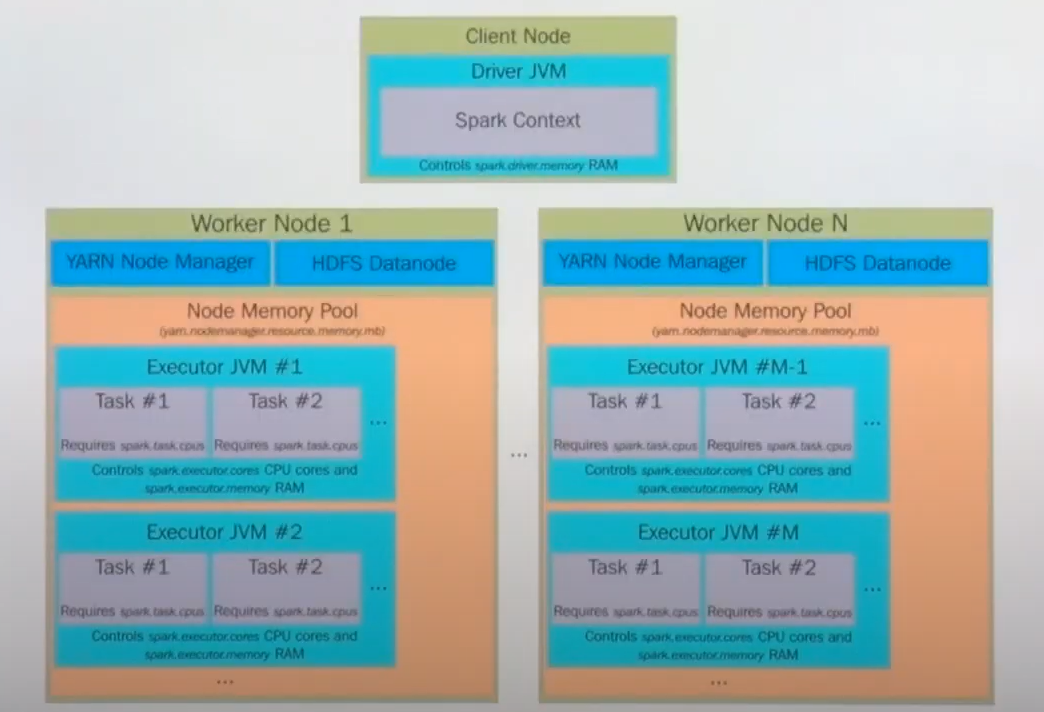
🔖 JVM Memory Management
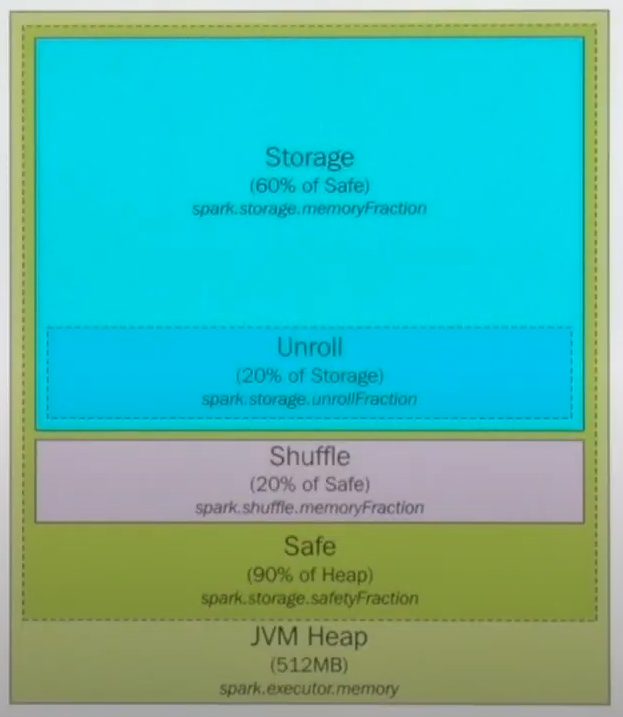
- Java Heap 사이즈는 전체 executor 메모리의 90%
- Storage 영역이 실제로 캐시되는 영역. 기본이 60%
- 캐쉬가 다 차면 LRU 알고리즘에 의하여 오래된 것들은 ??
🔖 Monitoring
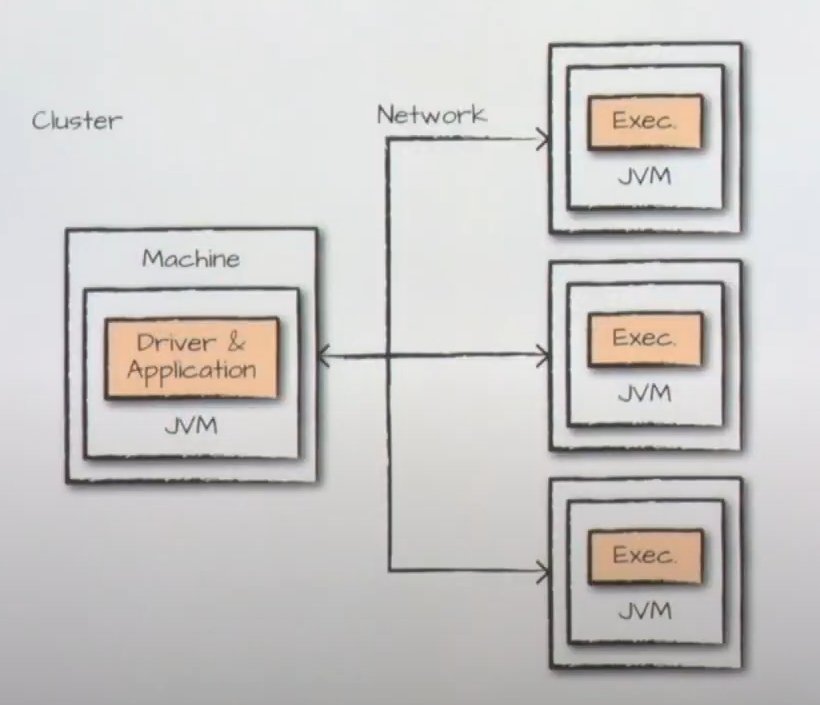
- 클러스터에서는 드라이버와 각각의 executor을 모니터링
- OS/머신
- 클러스터
- 네크워크
- JVM
🔖 Spark First Aids
⚠️ Spark Job이 시작되지 않음
-
[증상]
- submit 했지만 spark job이 시작되지 않음
- spark UI가 드라이버 제외하고 클러스터에서 어떤 노드도 보이지 않음
- spark UI에 들어가면 없다고 뜸
-
[원인]
- 다른 포트를 사용하고 있음
- 리소스를 제대로 할당받지 못하면 스파크 드라이버가 뜨지 않음
⚠️ Slow Tasks or Stragglers
- 전체적으로 데이터가 균등하게 퍼져 동등하게 일을 하는 것이 베스트
- [원인]
- 전체 태스크 중에 종료된 건 80%인데 종료되지 않은 20%는 retry나 뭔가를 하고 있음. 그 - retry는 out of memory일 수도 있고 디스크나 네트워크 문제일 수도 있음
- skew된 작업
- [해결법]
- 파티션을 늘림(리파티셔닝): 특정 블럭이 데이터가 균등하지 않고 커져있는 상태로 들어가 있다면 오래걸림.
- 100개의 태스크가 있다고 가정하자. 200개를 리파티션 하면 200개의 태스크가 실행
- 메모리를 더 올려줌
- 파티션을 늘림(리파티셔닝): 특정 블럭이 데이터가 균등하지 않고 커져있는 상태로 들어가 있다면 오래걸림.
Driver OutOfMemoryError or Driver Unresponsice
⚠️ Spark Application is unresponsive or crashed OutOfMemoryErros or garbage collection messages in the driver logs
- [해결법]
- collect, count, take, show 같이 드라이버쪽에 호출되는 함수는 디버깅 단계에서 필요하지만 실제 어플리케이션에서는 사용 자제
- broadcast join은 롱러닝 프로세스에서는 부담이 됨
-> 드라이버 메모리나 드라이버 자원이 필요하다면 클라이언트처럼 따로 빼서 전담하여 메모리나 코어를 줄 수 있음
Executor OutOfMemoryError or Executor Unresponsive
⚠️ OutOfMemoryErros or garbage collection messages in the executor logs Executors that crash or become unresponsive
- [원인]
- external system과 연결하여 데이터를 옮김
- [해결법]
- 메모리 늘리기 = executor 늘리기
- JVM 모니터링을 통해 executor 쪽 OutOfMemeory가 심하다면 JMX 통하여 모니터링

어쩌다보니 데이터쟁이