▶️ 원본 영상: https://youtu.be/rjJ54qtOjW4
Apache Hadoop
- Hadoop Common
- Hadoop Distributed File System(HDFS)
- Hadoop YARN
- Hadoop MapReduce
HDFS
- 하둡 에코시스템에서 분산 파일 시스템을 지원하는 것을 목표
- 큰 파일들을 잘 저장하고 잘 처리될 수 있도록 지원
- Hardware failure: Reliability를 위하여 안정적으로 서비스를 할 수 있도록 HDFS는 하드카피를 저장
- HDFS에게 적절한 파일은 큰 파일
- 최악인 경우는 작은 파일이 많은 경우
- 디스크 I/O를 일으킴 → latency 발생
Design of Hadoop Dstributed File System(HDFS)
- 마스터-슬레이브 설계
- 마스터 노드
- 싱글 네임노드
- 메타데이터 매니징
- 이중화, 백업 시 스냅샷을 통하여 고가용성 보장
- 슬레이브 노드
- 데이터 노드
- 실제 데이터가 저장
- 하둡 클러스터 몇대? = 스토리지 용량
- 네임노드 백업
- 각각 데이터 노드에 블락 단위로 저장
- 네임노드가 장애가 나면 모든 메타데이터는 사라짐 → 고가용성을 보장해야함
- 마스터 노드
HDFS 구조
- 네임노드
- 메타데이터 유지
- 파일이 들어왔을 때 이름과 어떤 노드의 어떤 블락으로 단위로 들어가 있는 지에 대한 정보 관리
- 데이터노드
- 블락 단위로 파일이 들어오면 블럭 단위로 쪼개져서 각각 저장
- 네임노드와 데이터노드가 서로 하트비트를 날림
HDFS Block
- 각각의 블락은 각각의 노드들에게 분산되어 있고 같은 RAG에 들어가 있지 않음
HDFS
- 블락 단위로 파일이 나뉘어짐
- 저장되는 블락 단위가 실제로 읽기/쓰기 단위
- 기본 크기는 64MB, 128MB까지 늘릴 수 있음
- 큰 파일을 저장할 때 분산 파일 저장소로 가장 좋은 구조
- 하나의 블럭이 하나의 노드에 존재하는게 아니라 여러 번 복제가 됨(기본 값: 3 copy)
- 특정 노드에 문제가 발생했을 때, 특정 디스크에 문제가 발생했을 때 fault tolerant를 보장
- 블럭이 잘 분배해서 저장되어 있으면 병렬성이 높아짐
MapReduce: Simple Programming for Big data Based on Google’s MR paper(2024)
- 하둡 에코시스템의 기본적인 프로그래밍 패러다임. 스파크의 동작 방식도 동일
- 전통적인 병렬 프로그래밍은 전문가의 스킬을 요구했음
- lock, semaphore, monitor 부분이 잘못 개발된 경우 문제가 프로그램의 전체에 영향을 끼칠 수 있음
- 구조 자체가 병렬 프로그래밍 모델 → hard failure에 대한 fault tolerant 보장이 되기 힘듦
- MapReduce는 이런 전통적인 병렬 프로그래밍 이슈를 고민하지 않고 간단하게 맵과 리듀스를 하는 작업. 코드를 병렬적으로 간단하게 돌리기 좋은 프로그램 모델,
Word Count Example
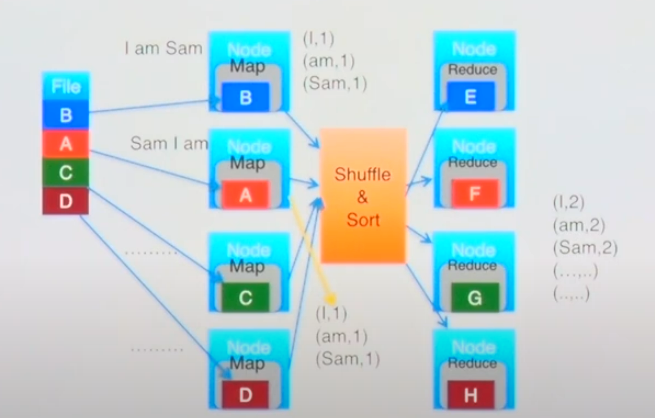
1. 파일이 4개의 블락으로 나뉘어짐
2. 각각의 블락은 특정 노드에 위치
3. Map 단계: 각 단어를 토크나이징하여 각 단어가 몇 번씩 노출이 되었는 지 count
4. Reduce: Shuffle(데이터를 모두 섞음) & Sort
Apache Spark
- 기존 MapReduce 보다 빠르게 컴퓨팅
- 디스크 기준으로 10배, 인메모리 기준으로 100배 빨라짐
- Python, Java, Scala, R로 처리 가능
What is Apache Spark?
- 컴퓨터 클러스터에서 병렬 데이터 프로세싱을 하는 모든 라이브러리의 집합. 그리고 통합된 컴퓨터 엔진
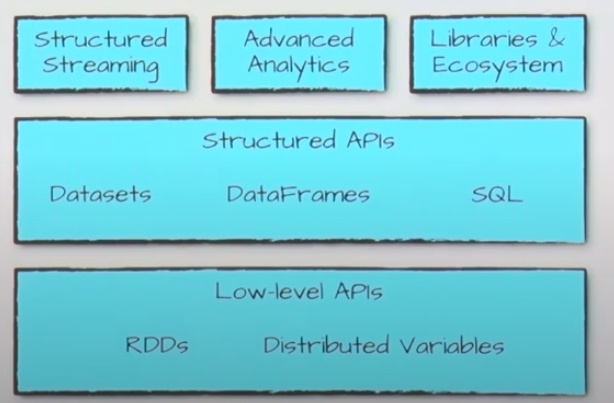
- Low-level APIs → 난이도가 있음
- RDDs
- 분산 variable
- Structured APIs: Structured Data는 데이터에 대한 스키마가 있는 것
- Datasets
- DataFrames
- SQL
- Structured Streaming: Stremaing + Structured Data
- Advanced Analytics
- Library & Ecosystem
MR vs Spark
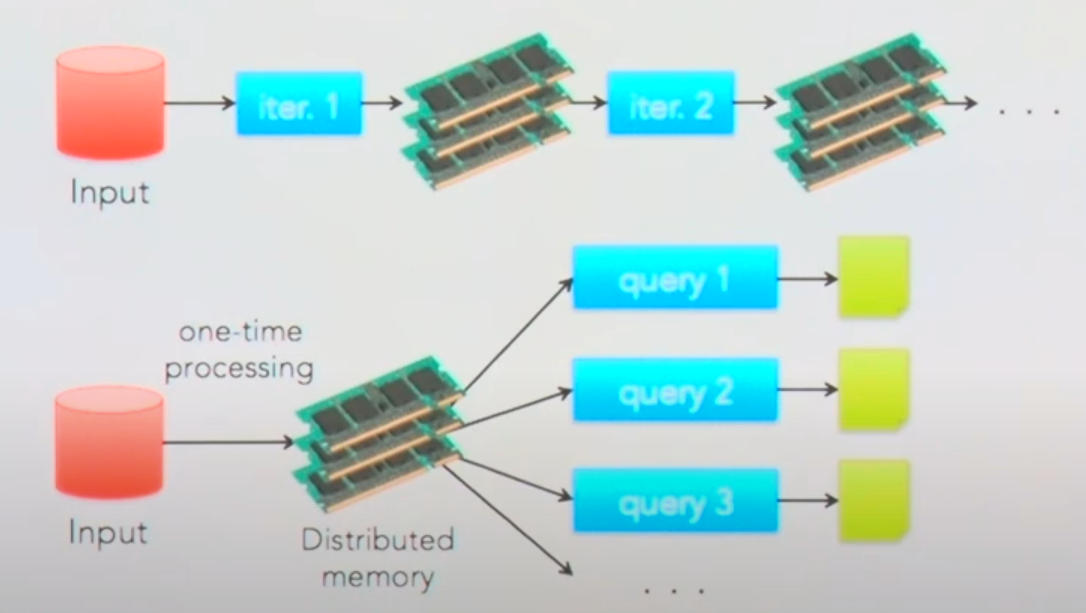
- MR
- 데이터를 읽고 쓰면서 디스크 I/O 발생
- SQL 질의가 갔을 때 HDFS를 읽어서 그 결과를 반환
- Shuffle & Sort 시 네트워크 I/O 발생: 모든 노드에 있는 값들을 모아서 Reduce 쪽으로 보내야 하기 때문
- Spark
- 인메모리에서 모두 처리
Apache Spark
- 데이터 분석
- 머신러닝 라이브러리 지원
- 그래프 분석
- 실시간 스트리밍 데이터 처리
Spark Basic Architecture
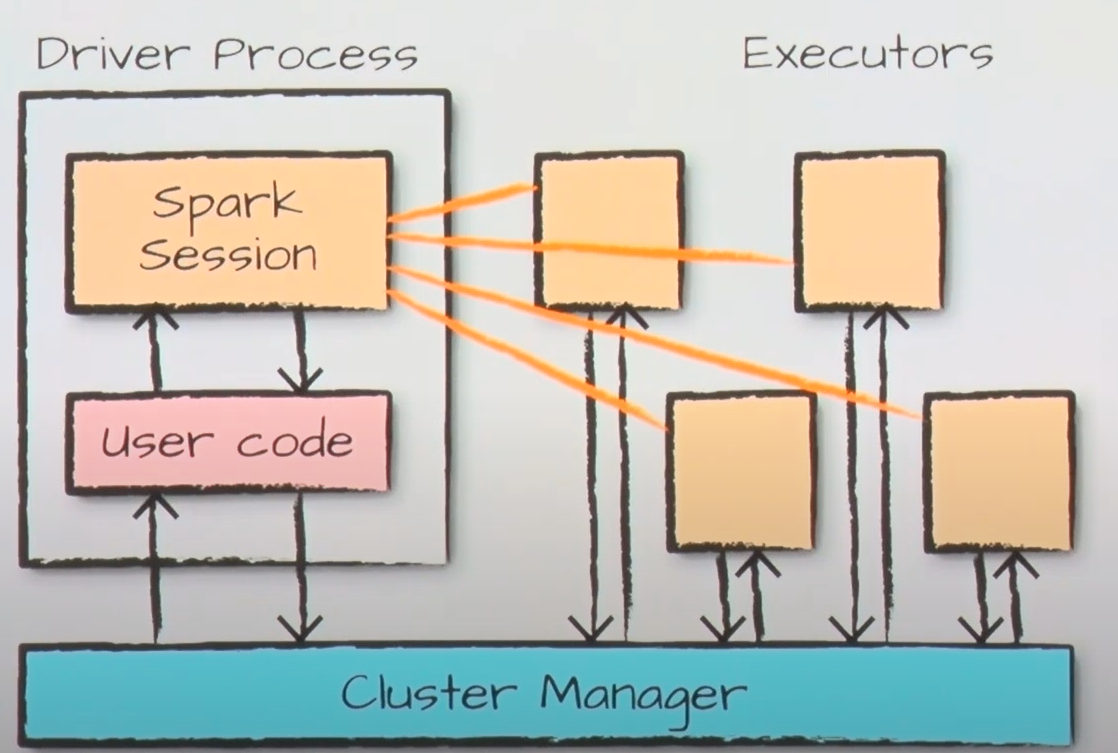
1. spark submit: 서버 클러스터의 유저 코드를 제출. 이 때 리소스를 얼마 쓰겠다고 지정해서 제출(excutore 개수, excution 하고 싶은 코어 메모리 수 등)
2. spark submit 후에는 드라이버 프로세스가 뜸
3. 드라이버 프로세스에서는 스파크 세션을 생성
Spark Language APIs
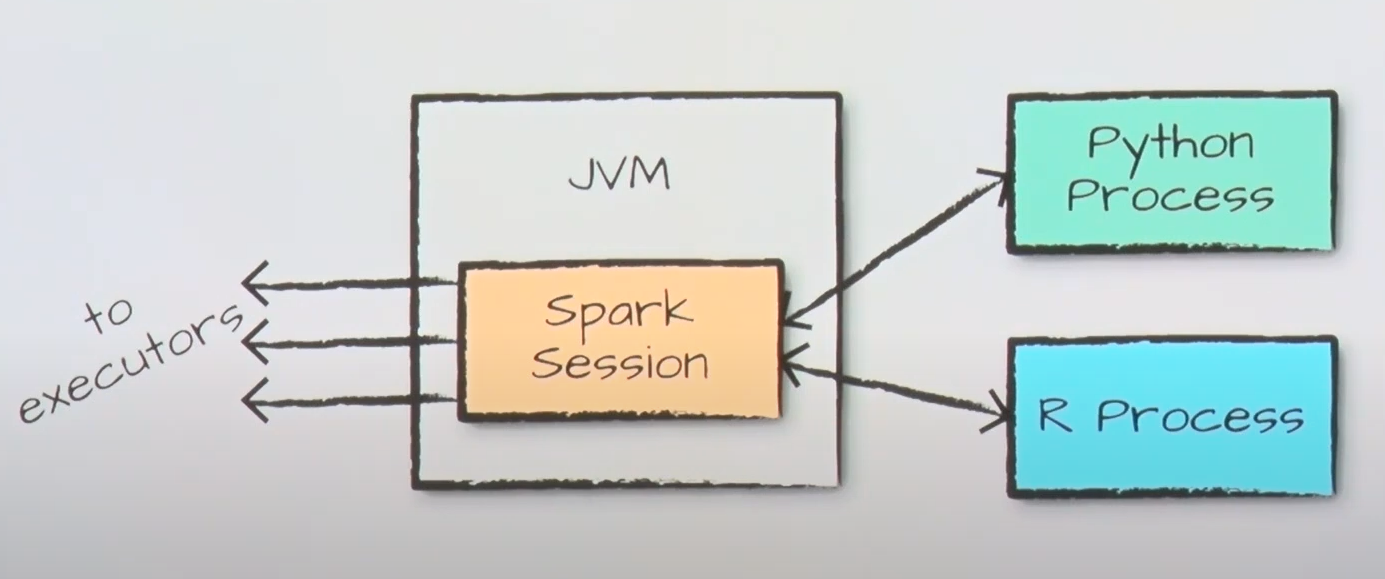
- 스파크 자체는 JVM 내에서 구동
- 실제로 일하는 건 다수의 executor
DataFrames
- 분석 쪽에서는 열과 행이 있고 정리된 데이터들을 손쉽게 처리할 수 있는 구조
- 스파크에서는 단일이 아닌 멀티 클러스터 환경에서 데이터를 분산 병렬 처리하는 것
Spark’s Use cases
- 실시간 처리 스트리밍 데이터
- 머신 러닝
- Interactive Analysis: 스파크는 latency가 적기 때문
- Data warehousing
- Batch Processing: Hive를 많이 사용
- EDA
- 그래프 데이터 분석
- GIS 데이터 분석
Spark: when not to use
- 스파크는 분산 병렬 컴퓨팅을 하는 프레임워크. HDFS나 DB 솔루션을 대체하는 것이 아님
- 단독을 사용하는 것보다는 기존 Hadoop나 NoSQL DB, 그 외 다른 기술을 결합하여 사용되었을 때 컴퓨팅 할 수 있는 능력이 더 좋아짐
- 데이터가 복잡한 경우
- 스파크가 데이터를 읽는 구조 자체가 HDFS나 shared 스토리지에 있는 데이터를 올리는 거기 때문에 디스크 I/O 발생 → DB들은 인덱스 구조를 가지고 있고 질의 최적화 되어 있으므로 DB처럼 성능이 나오지 않음
- 메모리 뿐만 아니라 CPU도 중요
Hadoop & Spark
- Hadoop(HDFS, MapReduce)
- 빅데이터의 가장 손쉬운 솔루션
- Spark
- MapReduce의 확장
- 인메모리 컴퓨팅으로 데이터 latency 등의 문제를 해결
- 스트리밍 데이터
- interativce
- iterative 연산: 캐시에 올려놓는다면 다시 데이터를 읽을 필요가 없음

어쩌다보니 데이터쟁이