학교 축제와 3차전공시험이 있었던 바빴던 지난 한주가 끝나고 이번주부터 본격적으로 딥러닝과 머신러닝을 공부하고자 합니다.
케글데이터를 뒤져보다가 음성신호를 통해 각 감정들을 분류하는 알고리즘을 구현한 코드가 있었습니다. 딥러닝을 통해 이 발화자가 어떤 감정인지를 알아맞추는 프로그램이였습니다.
음성신호를 전처리하는 과정은 생략하겠습니다.(작년에 저를 괴롭혔던 푸리에 변환등 어마무시한 공학적 지식들이 녹여져 있어서요ㅠㅠ)
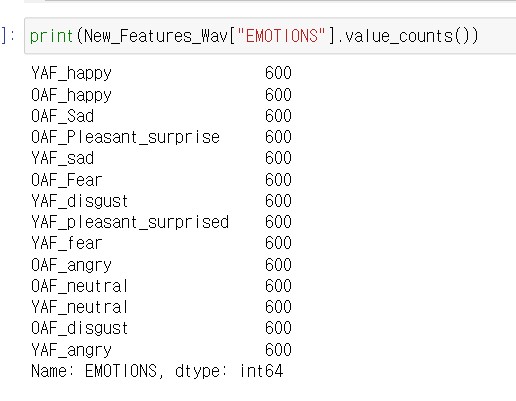
'OAF_angry', 'OAF_disgust', 'OAF_Fear', 'OAF_happy', 'OAF_neutral',
'OAF_Pleasant_surprise', 'OAF_Sad', 'YAF_angry', 'YAF_disgust',
'YAF_fear', 'YAF_happy', 'YAF_neutral', 'YAF_pleasant_surprised',
'YAF_sad'] 위 데이터의 감정들은 총 14가지가 있습니다.
딥러닝을 이용해 학습시켜서 각 음성신호가 지금 어떤 감정인지 14가지로 분류해 보았습니다.
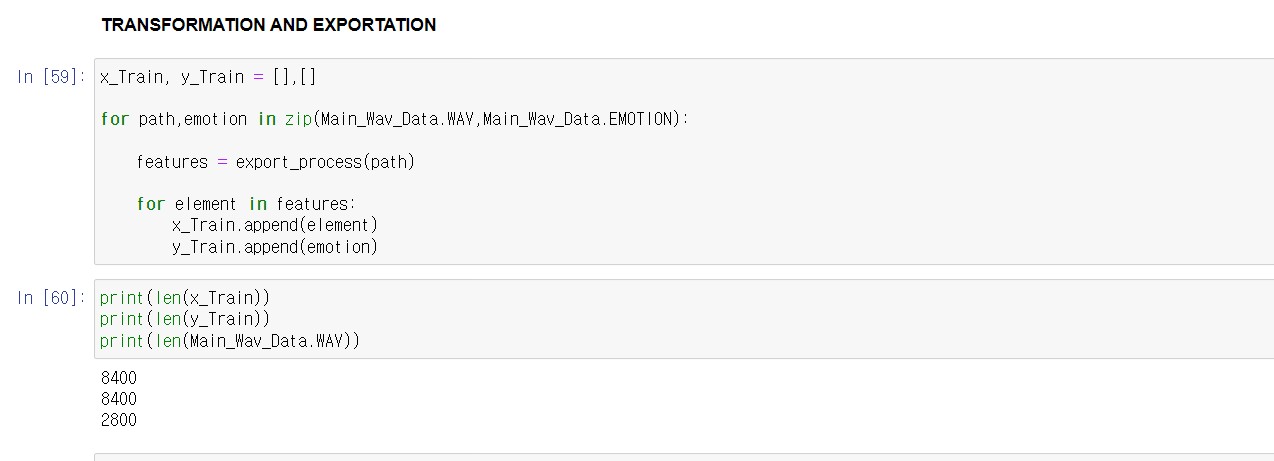
음성신호의 개수는 8400개입니다. x_train에는 162개의 수치화된 칼럼이 있습니다. 이때 수치화된 칼럼이 어떤것을 의미하는지는 잘 모릅니다. y_train에는 각 감정들을 나타내는 타켓값이 있습니다.
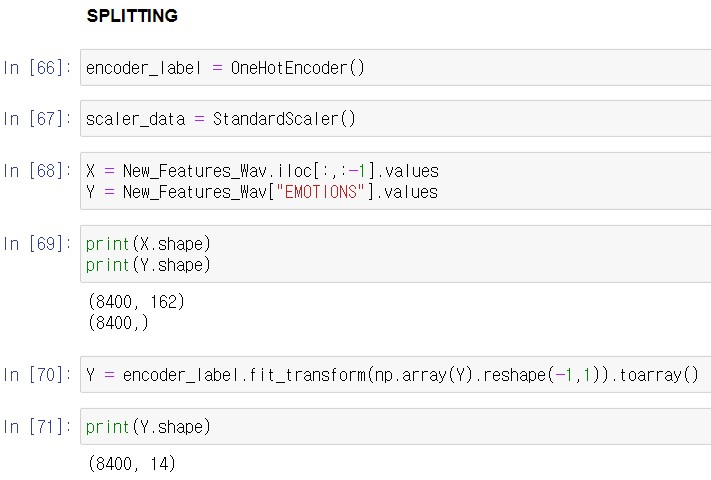
문자로 된 감정들의 타켓값을 OneHotEncoder를 통해 인코딩 해줍니다.
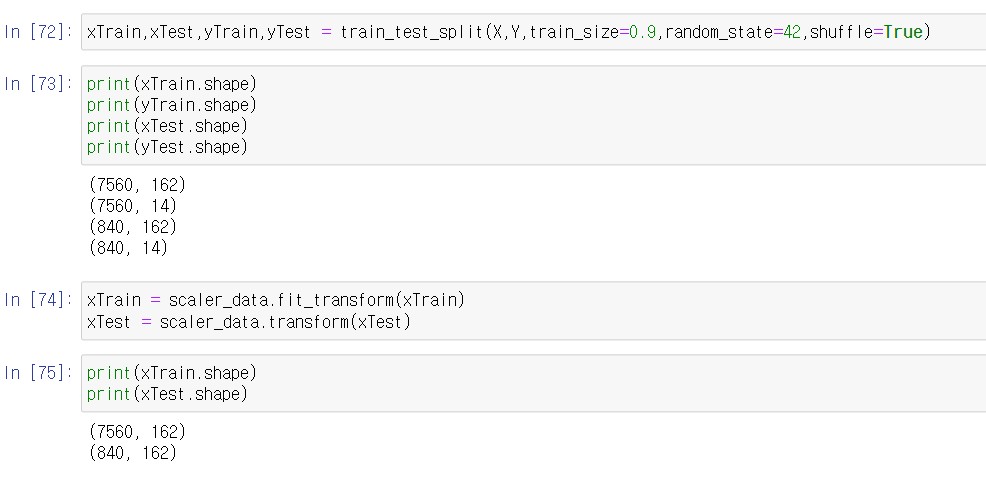
8400개의 음성데이터들을 train데이터와 test데이터로 9대 1 비율로 쪼갭니다. 쪼갠 후에 수치 데이터를 standardscaling을 통해 변수간의 스케일 차이를 줄여주고 모델의 성능을 개선합니다.
데이터 전처리는 모두 끝냈고 딥러닝을 위하여 2차원 데이터를 3차원으로 변환시켜줍니다.
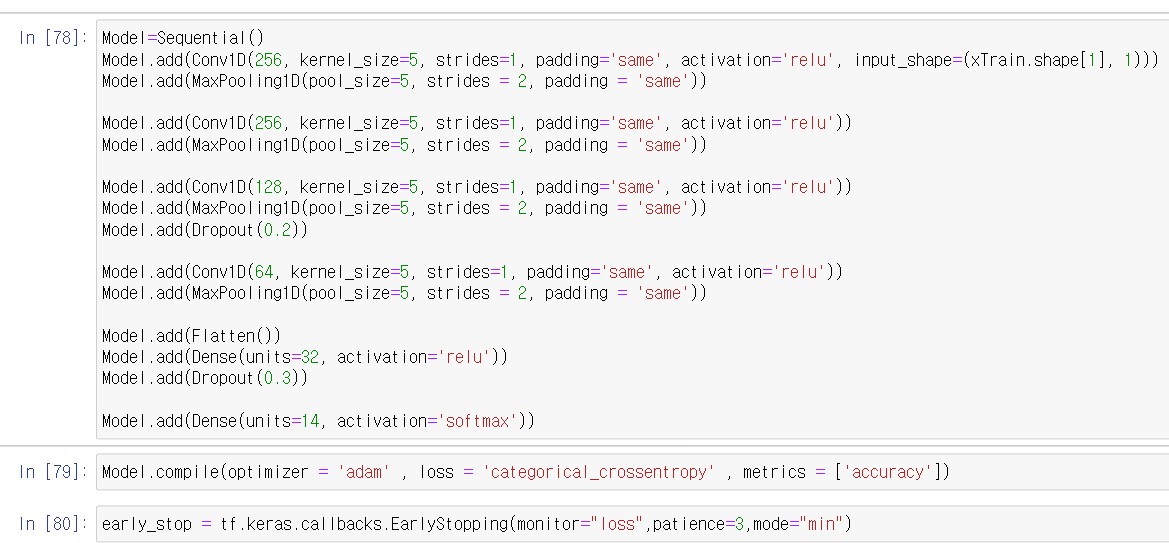
이 포스팅의 알파이자 오메가인 CNN을 하는 과정입니다.
Model.add(Conv1D(256, kernel_size=5, strides=1, padding='same', activation='relu', input_shape=(xTrain.shape[1], 1)))
필터의 크기는 5이고 strides가 1이니 한칸식 이동하면서 convolution연산을 수행한다. 이때 필터의 출력값은 relu함수를 적용하여 음수는 0 양수는 그대로 출력한다. 처음에 CNN을 수행 할때엔 칼럼 수대로 입력을 해줘야 되기 때문에 xTrain.shape[1] 총 162개의 뉴런이 필요하고 1차원 연산이기 때문에 (162,1)의 형태로 입력값을 넣어준다.
maxpooling과 은닉층을 쌓아가면서 CNN연산을 수행한다.( 이때 은닉층의 개수는 자율적으로 조절한다. conv1D, maxpooling이 많다고 좋은 것은 절대 아니다.)
Model.add(Dense(units=14, activation='softmax'))
감정의 형태가 14가지가 있으므로 맨 마지막에는 출력 뉴런(차원)이 무조건 14여야 된다.
Model.compile(optimizer = 'adam' , loss = 'categorical_crossentropy' , metrics = ['accuracy'])
adam이라는 경사하강법과 categorical_crossentropy라는 손실함수를 이용하여 정확도를 측정하는 코드이다.
Conv1D_Model = Model.fit(xTrain, yTrain, batch_size=64, epochs=50, validation_data=(xTest, yTest), callbacks=[early_stop])
아까 분리되어진 train데이터들을 학습시키는 과정이다. 이때 검증데이터는 test데이터로 각epochs(학습)대로 loss와 accuracy를 측정하고 보여준다.
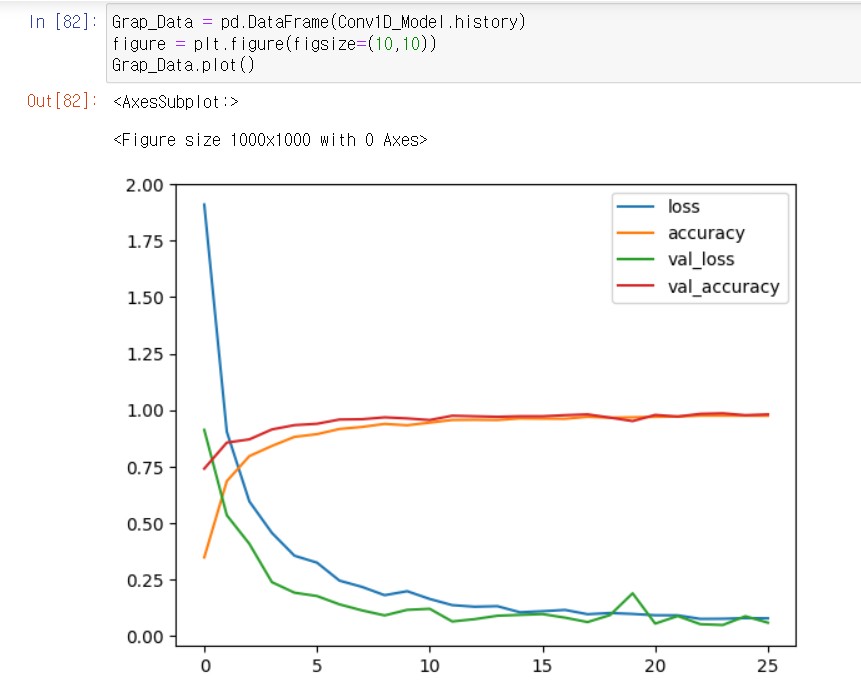
정확도가 점차적으로 증가하는 모습이다. epoch가 너무 많으면 과적합될 위험성도 있다. 이때 조기종료를 하는 방법이 있다.
일반적으로 적절한 에포크 수를 찾기 위해서는 초기에 작은 값으로 시작하고, 학습 과정에서 검증 데이터의 성능을 모니터링하여 최적의 에포크 수를 결정하는 것이 좋습니다.[gpt의 말씀]
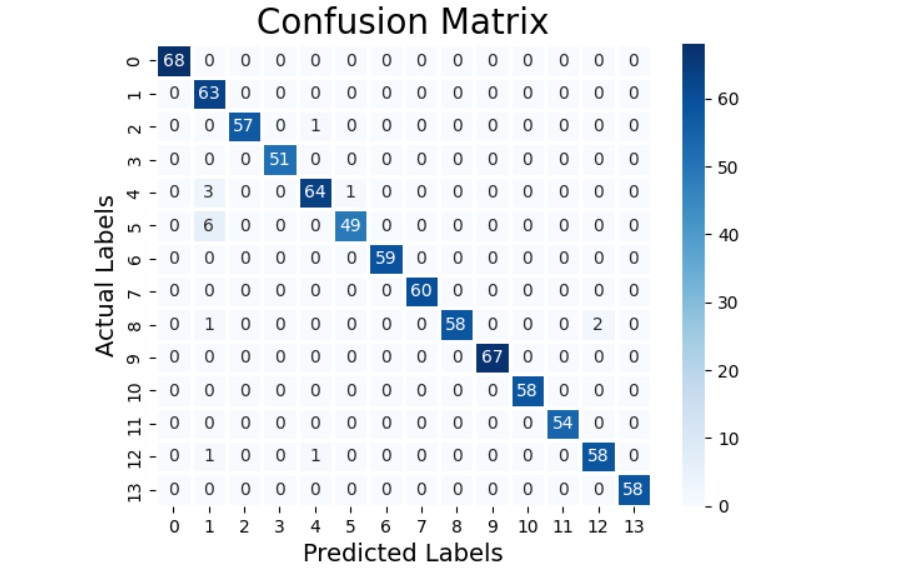
confusion행렬을 통해 어떤 감정을 잘못예측했는지 알 수 있다. 현재 scale이 되어 있는상태이기 때문에 숫자로 나와있어서 잘 모르겠지만 predicted을 1로 예측했지만 실제값은 5로 잘못예측된 건수가 6개가 있다는 것을 알 수 있다. 이때 대각선으로 된 것은 올바르게 예측했다는 것이다.
