목적
- Docker Container Engine 기반의 Kubernetes 환경 (version < 1.23)
- Nvidia GPU가 장착된 서버/PC 환경의 Kubernetes 에서 GPU 인식, 사용
- Kubernetes 에서 Nvidia GPU 를 사용하는 Application yaml 테스트
준비
항상 Official Doc 먼저 확인
- https://github.com/NVIDIA/nvidia-docker
- nvidia gpu 를 도커 컨테이너에서 사용할 수 있는 nvidia-docker
- https://github.com/NVIDIA/k8s-device-plugin
- k8s 에서 nvidia gpu 설치된 노드의 device 에 접근하여 관리, 사용할 수 있는 k8s-device-plugin
- helm 버전: https://github.com/NVIDIA/k8s-device-plugin#deployment-via-helm
- https://www.nvidia.com/ko-kr/drivers/unix/
- linux 환경의 nvidia 공통 driver
GPU 노드 준비
- nvidia GPU 드라이버 설치
- 드라이버 다운로드: https://www.nvidia.com/ko-kr/drivers/unix/
- run 파일
chmod +x NVIDIA-Linux-x86_64*.run ./NVIDIA-Linux-x86_64*.run
-
nvidia-docker 설치
- 패키지 저장소 추가하고 nvidia-docker 설치
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-docker2 sudo systemctl restart docker- /etc/docker/daemon.json 확인해서 default runtime 변경되었는지 확인,
안되어있으면 아래와 같이 편집
{ "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } } }
설치
k8s nvidia device plugin 설치 (v0.11.0)
yaml 버전 (for development)
- yaml 파일 다운로드
- 컨테이너 이미지명: nvcr.io/nvidia/k8s-device-plugin:v0.11.0
curl -o nvidia-device-plugin.yml https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.11.0/nvidia-device-plugin.yml
helm 버전 (for production)
- helm repo 추가
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin helm repo update - helm pull
helm pull --untar nvdp/nvidia-device-plugin- 항상 values 의 값을 숙지할 것
vi nvidia-device-plugin/values.yaml - helm custom values 파일 생성
- nvidia gpu 가 설치된 노드에만 설치하기 위해 custom values 파일 사용
cp nvidia-device-plugin/values.yaml values/value-nvidia-device-plugin.yml- nodeSelector 로 nvidia gpu 가 설치된 노드에만 추가한 node label 을 지정
vi values/value-nvidia-device-plugin.ymlnodeSelector: node.resource/gpu: "true" - helm install
helm install \ --values=values/value-nvidia-device-plugin.yml \ nvidia-device-plugin \ nvidia-device-plugin/- 설치 옵션
failOnInitError: fail the plugin if an error is encountered during initialization, otherwise block indefinitely 초기화 중에 오류가 발생하면 플러그인을 실패로 처리하고, 다른 경우엔 무기한 차단 (default 'true') compatWithCPUManager: run with escalated privileges to be compatible with the static CPUManager policy 고정된 CPUManger 정책과 호환되도록 상승된 권한으로 실행 (default 'false') legacyDaemonsetAPI: use the legacy daemonset API version 'extensions/v1beta1' 예전 daemonset 'extensions/v1beta1' API 버전을 호환 (default 'false') migStrategy: the desired strategy for exposing MIG devices on GPUs that support it MIG를 지원하는 GPU에 MIG 장치를 노출하는 방법 선택 [none | single | mixed] (default "none") deviceListStrategy: the desired strategy for passing the device list to the underlying runtime 기본 런타임에 장치 목록을 전달하기 위해 사용하는 방법 선택 [envvar | volume-mounts] (default "envvar") deviceIDStrategy: the desired strategy for passing device IDs to the underlying runtime 기본 런타임에 장치 ID를 전달하기 위해 사용하는 방법 선택 [uuid | index] (default "uuid") nvidiaDriverRoot: the root path for the NVIDIA driver installation (typical values are '/' or '/run/nvidia/driver') NVIDIA 드라이버 설치하는 루트 경로 지정 (/ 혹은 /run/nvidia/drive) runtimeClassName: the runtimeClassName to use, for use with clusters that have multiple runtimes. (typical value is 'nvidia') 여러 런타임이 있는 클러스터를 사용하는 경우 runtimeClassNmae 지정 (defaul 는 nvidia)
설치 확인
- 지정한 노드에만 설치되는 것을 확인
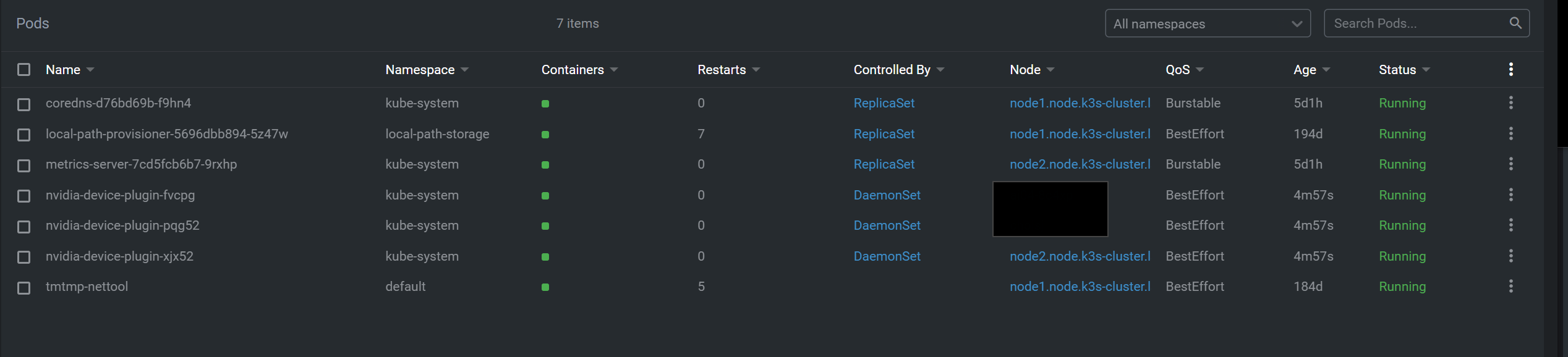
테스트
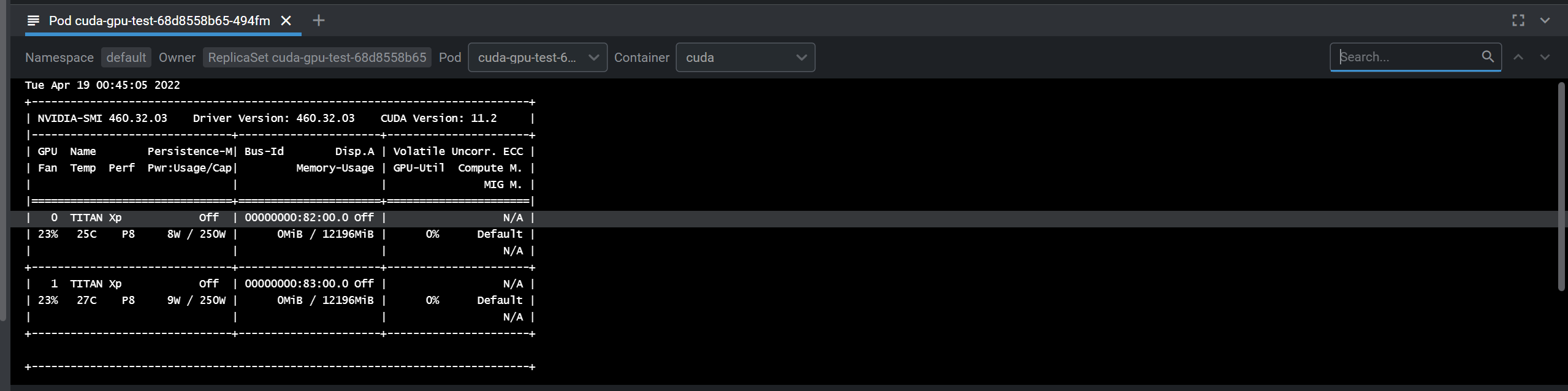
- nvidia-smi 테스트용 Deployment 작성
apiVersion: apps/v1
kind: Deployment
metadata:
name: cuda-gpu-test
labels:
app: gpu-test
spec:
replicas: 1
selector:
matchLabels:
app: gpu-test
template:
metadata:
labels:
app: gpu-test
spec:
containers:
- name: cuda
image: nvidia/cuda:10.0-base
command: [ "sh", "-c" ]
args: ["nvidia-smi && sleep 300"]
resources:
limits:
nvidia.com/gpu: 2
- kubectl apply -f {파일명} 으로 테스트
- 혹은 lens 에서 생성

안녕하세요 좋은 포스트 감사합니다. 혹시 클러스터의 기본 컨테이너 런타임을 도커로 사용하신 건가요?? containerd의 경우에는 device plugin이 제대로 gpu를 인식하지 못하는 것 같아서요 ㅠㅠ