MySQL이란?
- 가장 널리 사용되고 있는 관계형 데이터베이스 관리 시스템(RDBMS:Relational DBMS)
- 오픈소스임, 다중 사용자와 다중 스레드 지원
- 여러 프로그래밍 언어를 위한 다양한 API 제공
- 유닉스, 리눅스, 윈도우 등 다양한 운영체제에서 사용가능
-> PHP와 함께 웹 개발에서 자주 사용
SQL 기본
SQL의 분류
[DML(Data Manipulation Language)]
- 데이터 조작 언어
- 데이터를 조작(선택, 삽입, 수정, 삭제)하는데 사용되는 언어
- DML 구문이 사용되는 대상은 테이블의 행
- DML 사용하기 위해서는 꼭 이전에 테이블이 정의되어 있어야 함
- SELECT, INSERT, UPDATE, DELETE가 이 구문에 해당함
- 트랜잭션(Transection)이 발생하는 SQL도 이 DML에 속함
- 테이블의 데이를 변경(입력/수정/삭제)할 때 실제 테이블에 완전히 적용하지 않고 임시로 적용시키는 것- 취소 가능함
[DDL(Data Definition Language)]
- 데이터 정의 언어
- 데이터베이스, 테이블, 뷰, 인덱스 등의 데이터 베이스 개체를 생성/삭제/변경하는 역할
- CREATE, DROP, ALTER 구문
- 트랜잭션 발생X
- ROLLBACK이나 COMMIT 사용 불가
- 실행 즉시 MySQL에 적용
[DCL(Data Control Language)]
- 데이터 제어 언어
- 사용자에게 어떤 권한을 부여하거나 빼앗음
- GRANT,REVOTE,DENY 구문
SHOW DATABASES
- 현재 서버에 어떤 DB가 있는지 확인
SHOW DATABASES;USE
- 사용할 데이터베이스 지정
- 지정해 놓은 후 USE문을 다시 사용하지 않는 이상 처음 선택한 DB에서 SQL문 수행
USE database_name
USE worldSHOW TABLE
- 데이터 베이스의 테이블 이름 보기
SHOW TABLES;SHOW TABLE STATUS
- 데이터베이스의 테이블 정보 조회
SHOW TABLE STATUS;DESCRIBE(DESC)
- 특정 테이블에 무슨 열이 있는지 확인
DESCRIBE city;
or
DESC city;[Lab 01]country 테이블과 countrylanguage 테이블 정보 보기
SELECT
- <SELECT...FROM>
- 요구하는 데이터를 가져오는 구문
- 가장 많이 쓰는 구문
- 데이터베이스 내 테이블에서 원하는 정보 추출
SELECT select_expr
[FROM table_references][WHERE where_condition]
[GROUP BY {col_name | expr | position}][HAVING where_condition]
[ORDER BY {col_name | expr | position}]
[SELECT *]
SELECT * FROM city[SELECT 열 이름]
- 테이블에서 필요로 하는 열만 가져오는 기능
- 여러 개의 열을 가져오고 싶을 때는 콤마로 구분
- 열 이름의 순서는 출력하고 싶은 순서대로 배열 가능
SELECT Name, District FROM city;SELECT FROM WHERE
[기본적인 WHERE절]
- 조회하는 결과에 특절한 조건으로 원하는 데이터만 보고 싶을 때 사용
- 조건이 없을 경우, 테이블의 크기가 클수록 찾는 시간과 노력 증가
SELECT 필드 이름 FROM 테이블 이름
WHERE 조건식;
[관계 연산자 사용]
- 조건 연산자(=, <, >, <=, >=, <>, != 등)
- 관계 연산자(NOT, AND, OR 등)
- 연산자의 조합으로 데이터를 효율적으로 추출
SELECT *
FROM city
WHERE Population > 8000000 AND Population < 9000000[Lab 02] 한국에 있는 도시들 보기, 한국에 있는 도시들 중 인구 수가 1,000,000이상인 도시 보기
BETWEEN
- 데이터가 숫자로 구성되어 있어 연속적인 값
=> BTWEEN...AND 사용가능
SELECT *
FROM city
WHERE Population BTWEEN 7000000 AND 8000000IN
- 이산적인 Discrete 값의 조건에서는 IN() 사용가능
SELECT *
FROM city
WHERE Name IN('Seoul', 'New York', 'Tokyo')[Lab 03] 한국, 미국, 일본의 도시들 보기
LIKE
- 문자열의 내용 검색하기 위해 LIKE 연산자 사용
- 문자뒤에 % => 무엇이든(%) 허용
- 한 글자와 매치하기 위해서 => '_' 사용
SELECT *
FROM city
WHERE CountryCode LIKE 'KO_'Sub Query
- 서브쿼리
- 쿼리문 안에 또 쿼리문이 들어 있는 것
- 서브 쿼리의 결과가 둘 이상이 되면 에러 발생
SELECT *
FROM city
WHERE CountryCode = ( SELECT CountryCode
FROM city
WHERE NAMe = 'Seoul' );ANY
- 서브쿼리의 여러 개의 결과 중 한 가지만 만족해도 사용가능
- SOME은 ANY와 동일한 의미로 사용
- =ANY 구문은 IN과 동일한 의미
SELECT *
FROM city
WHERE Population > ANY ( SELECT Population
FROM city
WHERE District = 'New York' );ALL
- 서브쿼리의 여러 개의 결과를 모두 만족 시켜야 함
SELECT *
FROM city
WHERE Population > ALL ( SELECT Population
FROM city
WHERE District = 'New York' );ORDER BY
-결과가 출력되는 순서를 조절하는 구문
- 기본적으로 오름차순(ASCENDING)정렬
- 내림차순(DESCENDING)으로 정렬
- 열 이름뒤에 DESC 적어야됨 - ASC(오름차순) 는 default이므로 생략 가능
SELECT *
FROM city
ORDER BY Population DESC- ORDER BY 구문을 혼합해 사용하는 구문도 가능
SELECT *
FROM city
ORDER BY CountryCode ASC, Population DESC[Lab 04] 인구수로 내림차순하여 한국에 있는 도시 보기, 국가 면적 크기로 내림차순하여 나라 보기(country table)
DISTINCT
- 중복된 것은 1개씩만 보여주면서 출력
- 테이블의 크기가 클수록 효율적
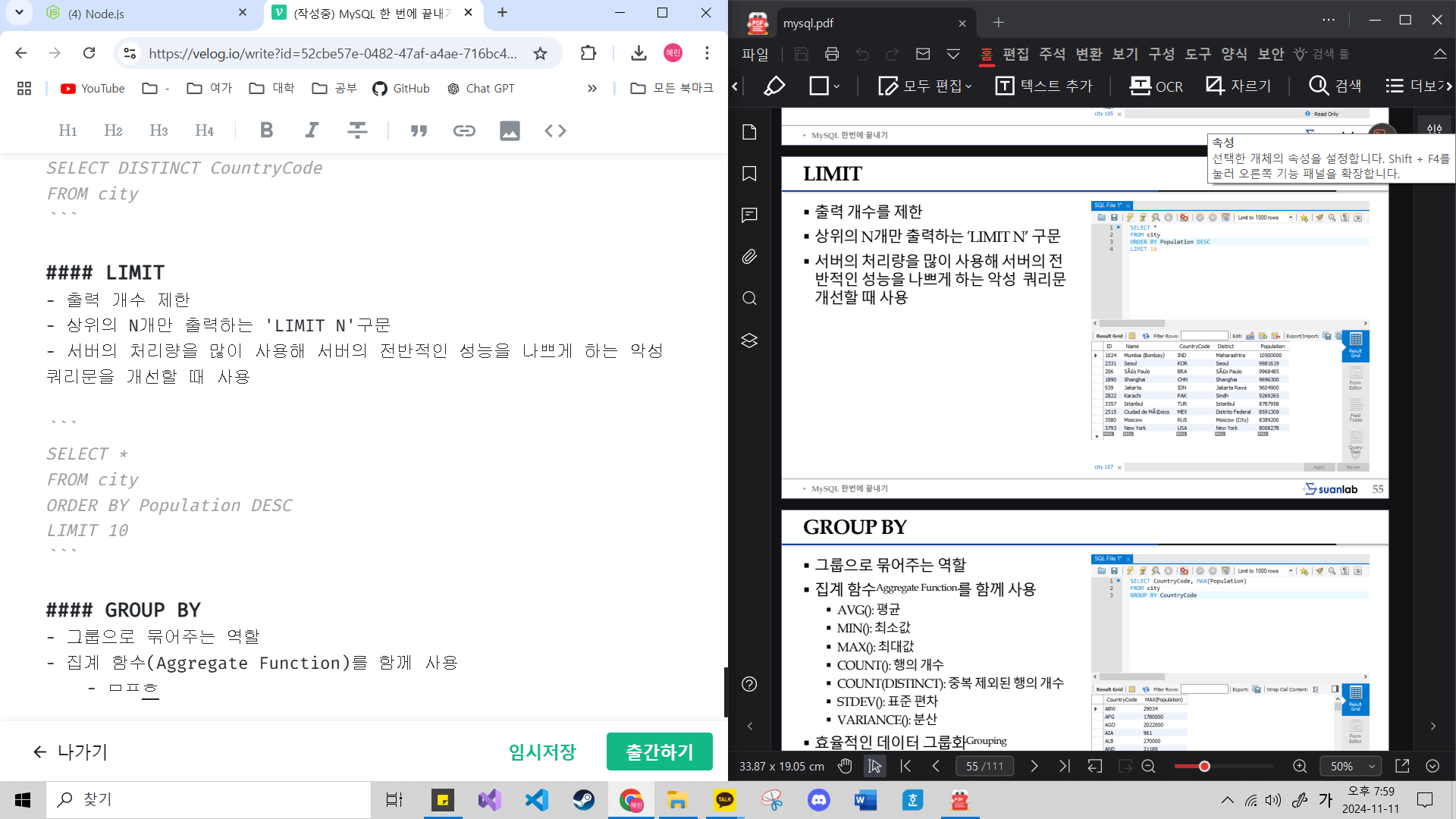
SELECT DISTINCT CountryCode
FROM cityLIMIT
- 출력 개수 제한
- 상위의 N개만 출력하는 'LIMIT N'구문
- 서버의 처리량을 많이 사용해 서버의 전반적인 성능을 나쁘게 하는 악성 쿼리문을 개선할 때 사용
SELECT *
FROM city
ORDER BY Population DESC
LIMIT 10GROUP BY
- 그룹으로 묶어주는 역할
- 집계 함수(Aggregate Function)를 함께 사용
- AVG() : 평균- MIN() : 최소값
- MAX() : 최대값
- COUNT() : 행의 개수
- COUNT(DISTINCT) : 중복 제외된 행의 개수
- STDEV() : 표준편차
- VARIANCE() : 분석
- 효율적인 데이터 그룹화(Grouping)
- 읽기 좋게 하기 위해 별칭(Alias) 사용
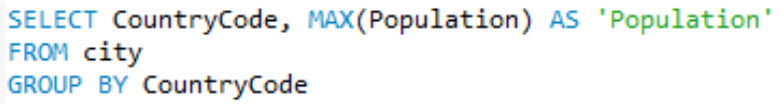
SELECT CountryCode, MAX(Population)
FROM city
GROUP BY CountryCode[Lab 05] 도시는 몇개인가?, 도시들의 평균 인구수는?
HAVING
- WHERE과 비슷한 개념으로 조건 제한
- 집계 함수에 대해서 조건 제한하는 편리한 개념
- HAVING절은 반드시 GROUP BY절 다음에 나와야 함
SELECT CountryCode, MAX(Population) 'MAX Population'
FROM city
GROUP BY CountryCode
HAVING MAX(Population) > 80000000ROLLUP
- 총합 또는 중간합계가 필요할 경우 사용
- GRUOP BY절과 함께 WITH ROLLUP문 사용
SELECT CountryCode, Name, SUM(Population)
FROM city
GROUP BY CountryCode, Name WITH ROLLUPJOIN
- JOIN은 데이터베이스 내의 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현
SELECT * FROM city
JOIN country
ON city.CountryCode = country.Code[Lab 06] city, country, countrylanguage 테이블 3개를 JOIN하기
MySQL 내장함수
- 사용자의 편의를 위해 다양한 기능의 내장 함수를 미리 정의하여 제공
- 대표적인 내장 함수의 종류
- 문자열 함수- 수학 함수
- 날짜와 시간 함수
LENGTH()
- 전달받은 문자열의 길이를 반환
SELECT LENGTH('123456789');CONCAT()
- 전달받은 문자열을 모두 결합하여 하나의 문자열로 반환
- 전달받은 문자열 중 하나라도 NULL이 존재하면 NULL을 반환
SELECT CONCAT('My', 'sql Op', 'en Source'),
CONCAT('MySQL', NULL, 'OpenSource');LOCATE()
- 문자열 내에서 찾는 문자열이 처음으로 나타나는 위치를 찾아서 해당 위치를 반환
- 찾는 문자열이 문자열 내에 존재하지 않으면 0을 반환
- MySQL에서는 문자열의 시작 인덱스를 1부터 계산
SELECT LOCATE('abc', 'abababcbacdABC'),
LOCATE('abc', 'abababcbacdABC', 7);LEFT(), RIGHT()
- LEFT(): 문자열의 왼쪽부터 지정한 개수만큼의 문자를 반환
- RIGHT(): 문자열의 오른쪽부터 지정한 개수만큼의 문자를 반환
SELECT
LEFT('MySQL is an open source relational database management system', 5), RIGHT('MySQL is an open source relational database management system', 6);LOWER(), UPPER()
- LOWER(): 문자열의 문자를 모두 소문자로 변경
- UPPER(): 문자열의 문자를 모두 대문자로 변경
SELECT
LOWER('MySQL is an open source relational database management system'), UPPER('MySQL is an open source relational database management system');REPLACE()
- 문자열에서 특정 무나열을 대체 문자열로 교체
SELECT REPLACE('MSSQL', 'MS', 'My');TRIM()
- 문자열의 앞이나 뒤, 또는 양쪽 모두에 있는 특정 문자를 제거
- TRIM() 함수에서 사용할 수 있는 지정자
- BOTH: 전달받은 문자열의 양 끝에 존재하는 특정 문자를 제거(기본 설정)- LEADING: 전달받은 문자열 앞에 존재하는 특정 문자를 제거
- TRAILING: 전달받은 문자열 뒤에 존재하는 특정 문자를 제거
- 만약 지정자를 명시하지 않으면 자동으로 BOTH로 설정
- 제거할 문자를 명시하지 않으면 자동으로 공백을 제거
SELECT TRIM(' ##My SQL## '),
TRIM(LEADING '#' FROM '##MySQL##'),
TRIM(TRAILING '#' FROM '##MySQL##');FORMAT()
- 숫자 타입의 데이터를 세 자리마다 쉼표(,)를 사용하는 '#, ###, ###.##'형식으로 변환
- 반환되는 데이터의 형식은 문자열 타입
- 두 번째 인수는 반올림할 소수 부분의 자릿수
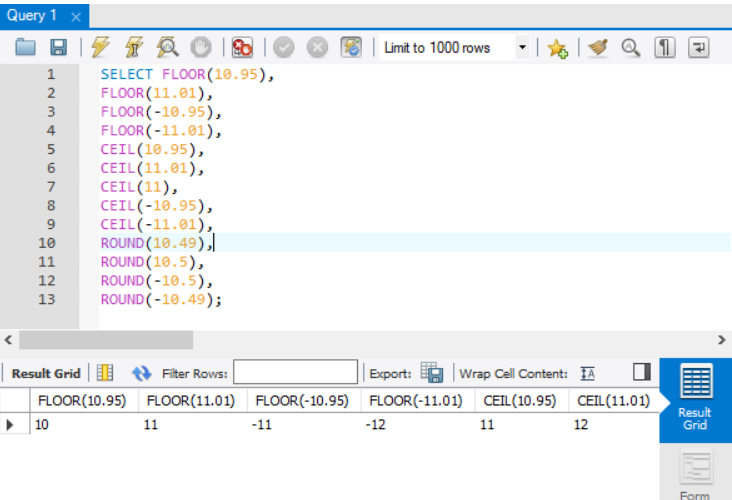
SELECT FORMAT(123456789.123456, 3);FLOOR(), CEIL(), ROUNT()
- FLOOR(): 내림
- CEIL(): 올림
- ROUND(): 반올림
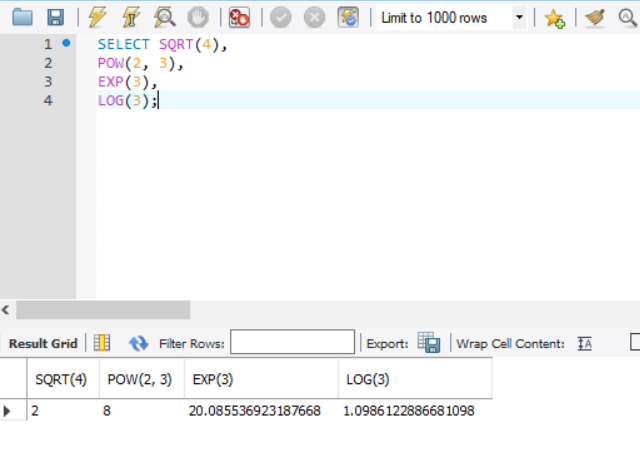
SQRT(), POW(), EXP(), LOG()
- SQRT(): 양의 제곱근
- POW(): 첫 번째 인수로 밑수를 전달하고, 두 번째 인수로 지수를 전달하여 거듭제곱 계산
- EXP(): 인수로 지수를 전달받아, e의 거듭제곱을 계산
- LOG(): 자연로그 값을 계산
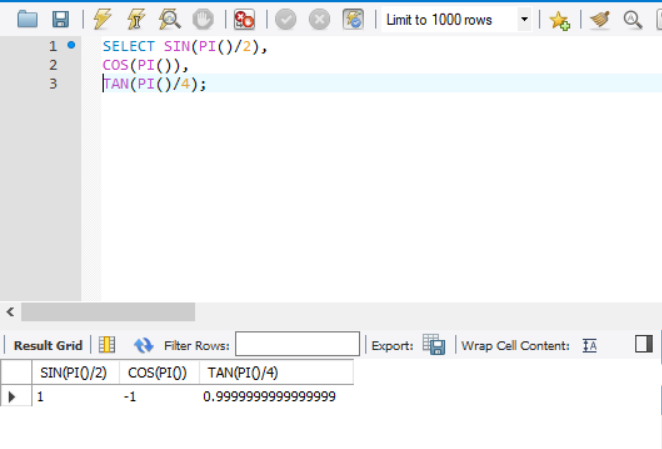
SIN(), COS(), TAN()
- SIN(): 사인값 반환
- COS(): 코사인값 반환
- TAN(): 탄젠트값 반환
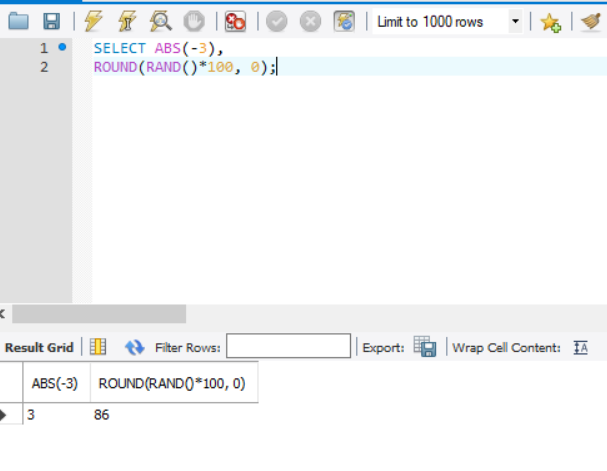
ABS(), RAND()
- ABS(X): 절대값 반환
- RAND(): 0.0보다 크거나 같고 1.0보타 작은 하나의 실수를 무작위로 생성
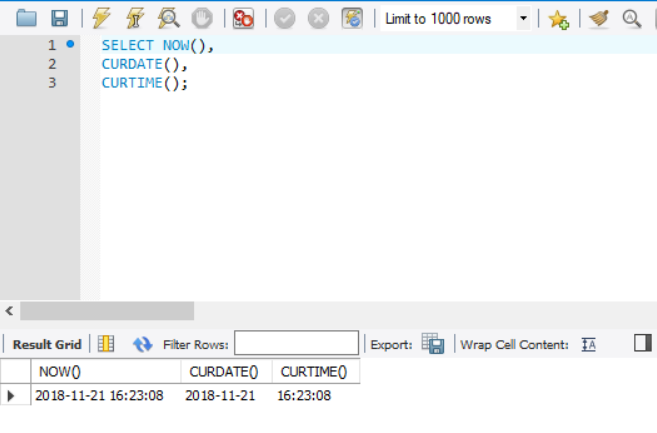
NOW(), CURDATE(), CURTIME()
- NOW(): 현재 날짜와 시간을 반환, 반환되는 값은 'YYYY-MM-DD HH:MM:SS' OR YYYYMMDDHHMMSS 형태로 반환
- CURDATE(): 현재 날짜를 반환, 이때 반환되는 값은 'YYYY-MM-DD'OR YYYYMMDD 형태로 반환
- CURTIME(): 현재 시각을 반환, 이때 반환되는 값은 'HH:MM:SS' OR HHMMSS 형태로 반환
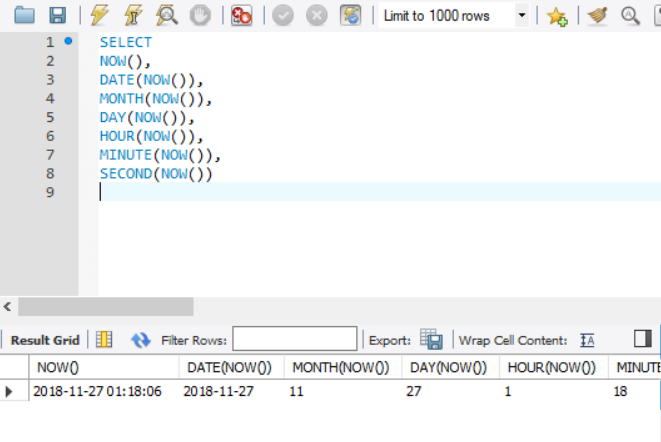
DATE(), MONTH(), DAY(), HOUR(), MINUTE(), SECOND()
- DATE(): 전달받은 값에 해당하는 날짜 정보를 반환
- MONTH(): 월에 해당하는 값을 반환하며, 0-12사이의 값
- DAY(): 일에 해당하는 값을 반환하며, 0-31사이의 값
- HOUR(): 시간에 해당하는 값을 반환, 0-23사이의 값
- MINUTE(): 분에 해당하는 값을 반환, 0-59사이의 값
- SECOND(): 초에 해당하는 값을 반환, 0-59사이의 값
MONTHNAME(), DAYNAME()
- MONTHNAME(): 월에 해당하는 이름을 반환
- DAYNAME(): 요일에 해당하는 이름을 반환
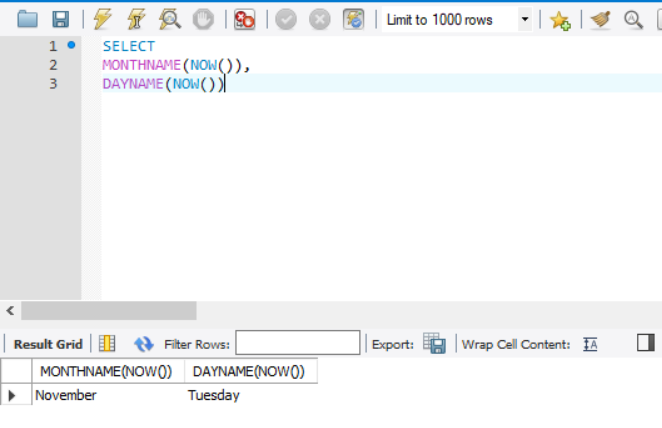
DAYOFWEEK(), DAYOFMONTH(), DAYOFYEAR()
- DAYOFWEEK(): 일자가 해당 주에서 몇 번째 날인지를 반환, 1부터 7 사이의 값 반환 (일요일 = 1, 토요일 = 7)
- DAYOFMONTH(): 일자가 해당 월에서 몇 번째 날인지를 반환, 0부터 31 사이의 값 반환
- DAYOFYEAR(): 일자가 해당 연도에서 몇 번째 날인지를 반환, 1부터 366 사이의 값 반환
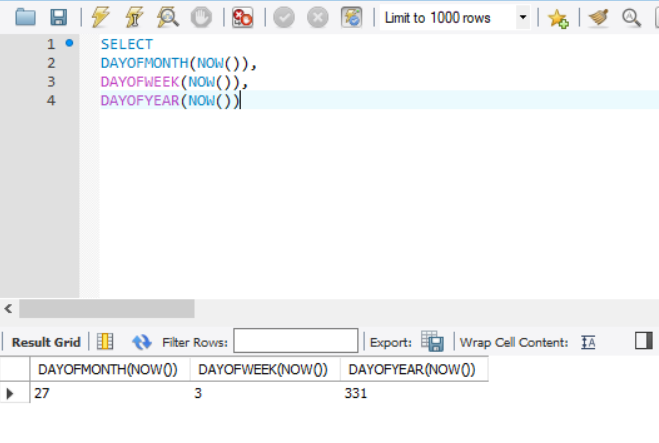
DATE_FORMAT()
- 전달받은 형식에 맞춰 날짜와 시간 정보를 문자열로 반환
- [MySQL Date and Time Function](https://dev.mysql.com/doc/refman/8.0 /en/date-and-time-functions.html )
SQL 고급
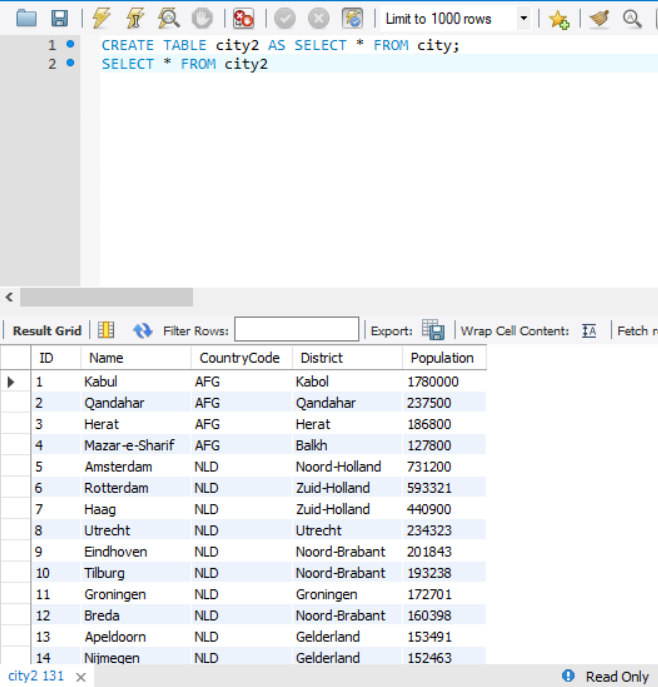
CREATE TABLE AS SELECT
- city 테이블과 똑같은 city2 테이블 생성
CREATE DATBASE
- CREATE DATBASE문은 새로운 데이터베이스 생성
- USE문으로 새 데이터베이스 사용
CREATE TABLE (MySQL Workbench)
- [데이터 타입](https://dev.mysql.com/doc/refman/8.0 /en/data-types.html)
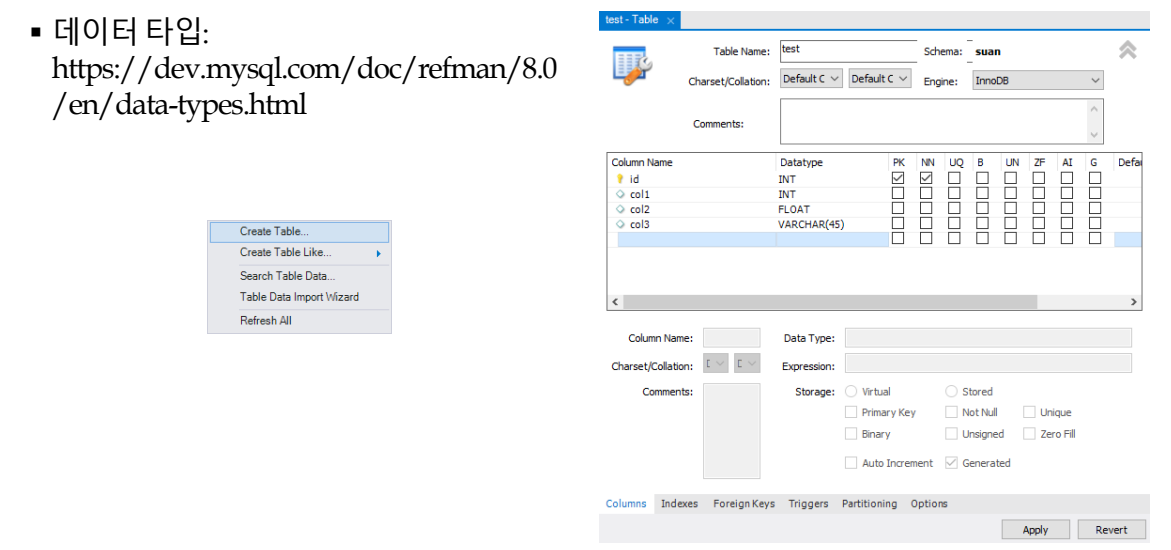
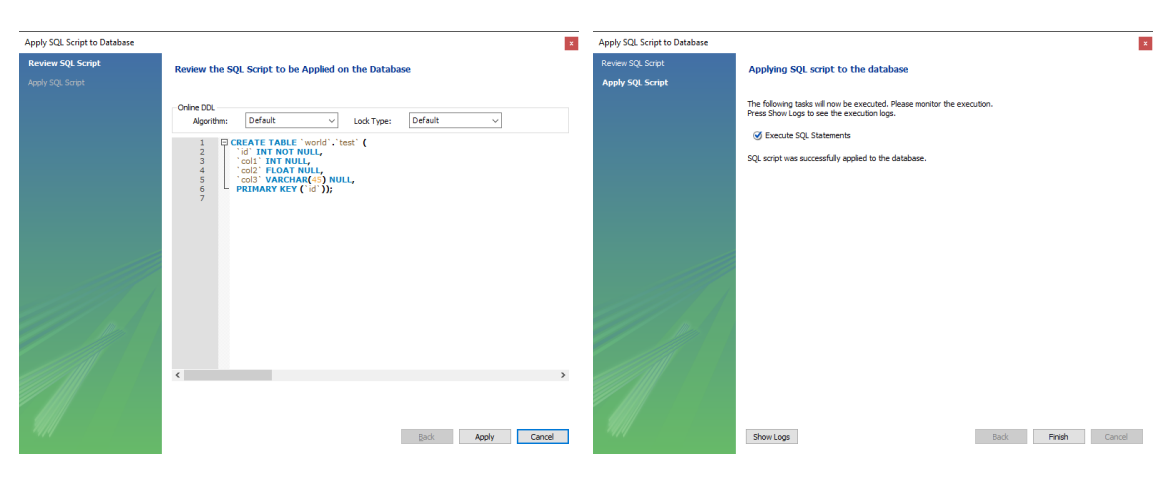
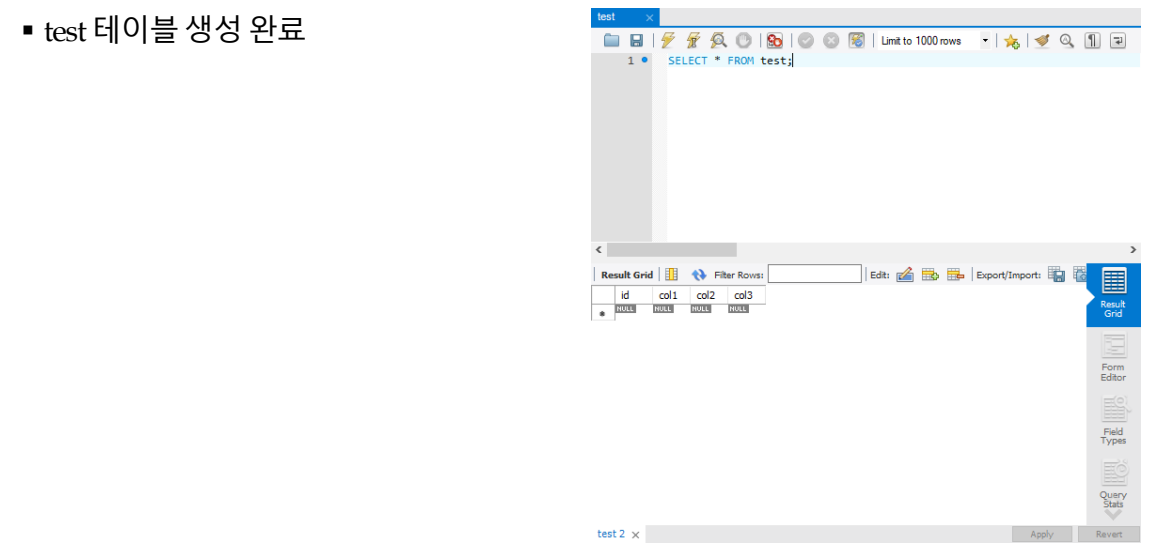
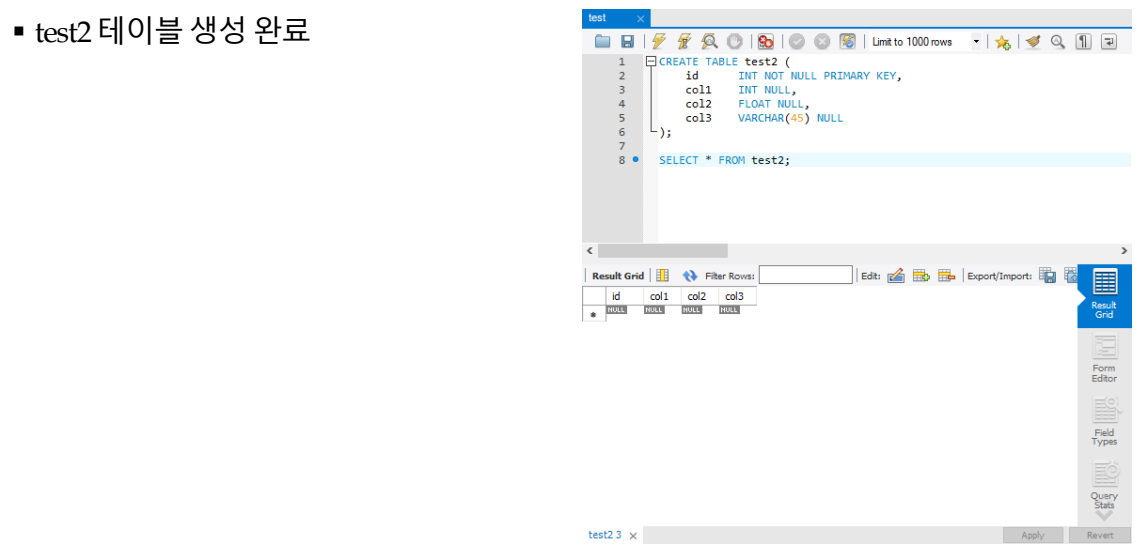
ALTER TABLE
-
ALTER TABLE문과 함께 MODIFY문을 사용하면, 테이블의 컬럼 타입을 변경할 수 있음
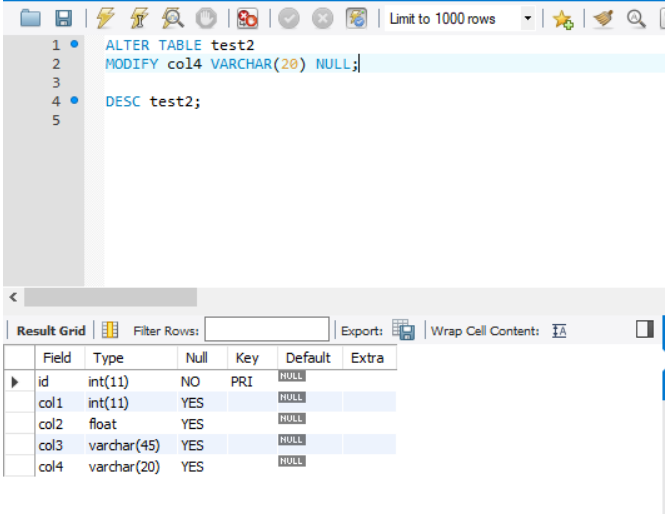
-
ALTER TABLE문과 함께 DROP문을 사용하면, 테이블에 열을 제거 가능
인덱스(Index)
- 테이블에서 원하는 데이터를 빠르게 찾기 위해 사용
- 일반적으로 데이터를 검색할 때 순서대로 테이블 전체를 검색하므오 데이터가 많으면 많을수록 탐색하는 시간이 늘어남
- 검색과 질의를 할 때 테이블 전체를 읽지 않기 때문에 빠름
- 설정된 열의 값을 포함한 데이터의 삽입, 삭제, 수정 작업이 원본 테이블에서 이루어질 경우, 인덱스도 함께 수정되어야 함
- 인덱스가 있는 테이블은 처리 속도가 느려질 수 있으므로 수정보다는 검색이 자주 사용되는 테이블에서 사용하는 것이 좋음
CREATE INDEX
- CREATE INDEX문을 사용하여 인덱스를 생성
CREATE INDEX Col1Idx
ON test (col1);SHOW INDEX
- 인덱스 정보 보기
SHOW INDEX
FROM test;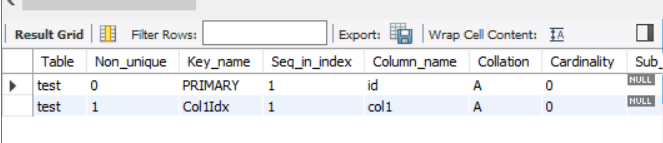
CREATE UNIQUE INDEX
- 중복 값을 허용하지 않는 인덱스
CREATE UNIQUE INDEX Col2Idx
ON test (col2);
SHOW INDEX FROM test;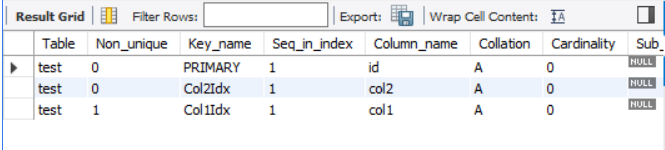
FULLTEXT INDEX
- FULLTEXT INDEX는 일반적인 인덱스와는 달리 매우 빠르게 테이블의 모든 텍스트 컬럼을 검색
ALTER TABLE test
ADD FULLTEXT Col3Idx(col3);
SHOW INDEX FROM test;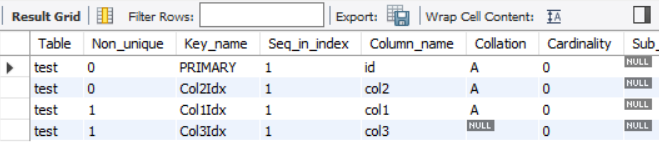
INDEX 삭제 (ALTER)
- ALTER 문을 사용하여 테이블에 추가된 인덱스 삭제
ALTER TABLE test
DROP INDEX Col3Idx;
SHOW INDEX FROM test;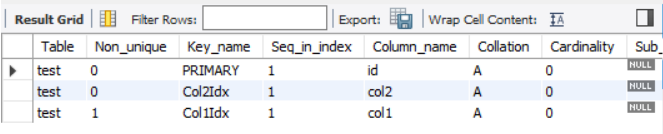
INDEX 삭제 (DROP INDEX)
- DROP 문을 사용하여 해당 테이블에서 명시된 인덱스를 삭제
- DROP 문은 내부적으로 ALTER 문으로 자동 변환되어 명시된 이름의 인덱스를 삭제
DROP INDEX Col2Idx ON test;
SHOW INDEX FROM test;
VIEW
- 뷰(view)는 데이터베이스에 존재하는 일종의 가상 테이블
- 실제 테이블처럼 행과 열을 가지고 있지만, 실제로 데이터를 저장하지 X
- MySQL에서 뷰는 다른 테이블이나 다른 뷰에 저장되어 있는 데이터를 보여주는 역할만 수행
- 뷰를 사용하면 여러 테이블이나 뷰를 하나의 테이블처럼 볼 수 있음
[view의 장점]
- 특정 사용자에게 테이블 전체가 아닌 필요한 컬럼만 보여줄 수 있음
- 복잡한 쿼리를 단순화해서 사용
- 쿼리 재사용 가능
[view의 단점]
- 한 번 정의된 뷰는 변경 x
- 삽입, 삭제, 갱신 작업에 많은 제한 사항을 가짐
- 자신만의 인덱스를 가질 수 x
CREATE VIEW
- CREATE VIEW문을 사용하여 뷰 생성
CREATE VIEW testView AS
SELECT Col1, Col2
FROM test
SELECT * FROM testView;
ALTER VIEW
- ALTER VIEW문을 사용하여 뷰를 수정
ALTER VIEW testView AS
SELECT Col1, Col2, Col3
FROM test;
SELECT * FROM testView;
DROP VIEW
- DROP문을 사용하여 생성된 뷰를 삭제
DROP VIEW testView;[Lab 07] city, country, countrylanguage 테이블을 JOIN하고, 한국에 대한 정보만 뷰 생성하기
INSERT
- 테이블 이름 다음에 나오는 열 생략 가능
- 생략할 경우에 VALUE 다음에 나오는 값들의 순서 및 개수가 테이블이 정의된 열 순서 및 개수와 동일해야 함
INSERT INTO test
VALUE(1, 123, 1.1, "Test");
SELECT *
FROM test;INSERT (MySQL Workbench)
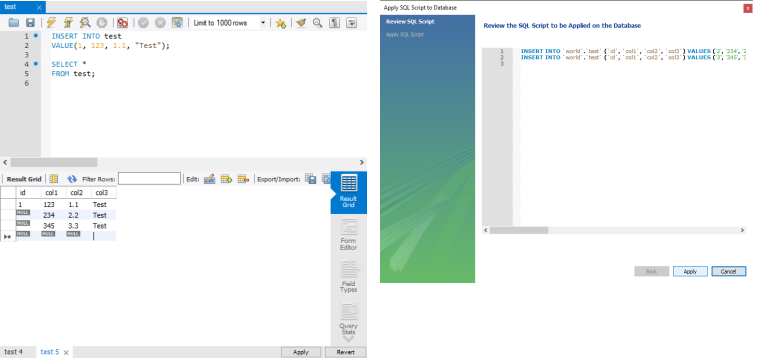
INSERT INTO SELECT
- test 테이블에 있는 내용을 test2 테이블에 삽입
INSERT INTO test2 SELECT * FROM test;
SELECT * FROM test2;UPDATE
- 기존에 입력되어 있는 값 변경하는 구문
- WHERE절 생략 가능하지만 테이블 전체 행의 내용 변경
UPDATE test
SET col1 = 1, col2 = 1.0, col3 = 'test'
WHERE id = 1;
SELECT * FROM test;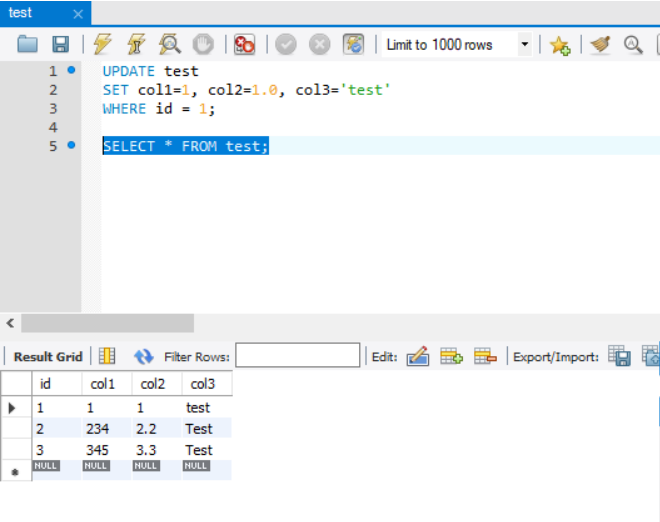
DELETE
- 행 단위로 데이터 삭제하는 구문
- DELETE FROM 테이블 이름 WHERE 조건;
- 데이터는 지워지지만 테이블 용량은 줄어들지 x
- 원하는 데이터만 지울 수 있음
- 삭제 후 잘못 삭제한 것을 되돌릴 수 있음
DELETE FROM test
WHERE id = 1;
SELECT * FROM test;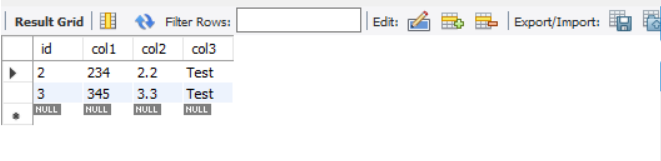
TRUNCATE
- 용량이 줄어 들고, 인덱스 등도 모두 삭제
- 테이블은 삭제하지 않고, 데이터만 삭제
- 한꺼번에 다 지워야 함
- 삭제 후 절대 되돌릴 수 없음
TRUNCATE TABLE test;
SELECT * FROM test;
DROP TABLE
- 테이블 전체를 삭제, 공간, 객체를 삭제
- 삭제 후 절대 되돌릴 수 없음
DROP TABLE test;DROP DATABASE
- DROP DATABASE문은 데이터베이스를 삭제
DROP DATABASE suan;