LESSON 2: MODELING FOR MONGODB
모델링 전에 알아두어야 할 것
-
document 모델을 사용하면 하나의 단일 문서 내에서 함께 사용되는 정보를 유지할 수 있다.
-
원자성, 일관성, 격리 및 내구성(ACID)은 선호되는 문서 모델을 활용하거나 MongoDB 트랜잭션을 사용하여 구현할 수 있다.
-
매우 큰 데이터 세트에 대한 조기 결정 및 타협은 데이터를 보다 쉽게 관리하는 데 도움이 된다.
예를 들어 일정 기간이 지난 문서를 삭제하거나 보관하면 프로젝트에 필요한 리소스가 줄어들 수 있다. -
MongoDB와 같은 분산 시스템을 사용한다는 것은 전 세계 서버에서 데이터를 쓰고 읽을 수 있다는 것을 의미한다.
서버 위치를 신중하게 계획하면 애플리케이션의 성능과 복원력이 향상된다.RDBMS VS MongoDB 모델링 비교

-
ER diagram VS Workload
RDBMS는 ER 다이어그램에 중점을 둔다면, MongoDB는 워크로드에 중점을 두어 모델링한다.
-> ER 다이어그램 : 데이터(Entity)들의 관계(Relationship)을 나타낸 도표(Diagram)
-> 워크로드 : 애플리케이션이나 백엔드 프로세스 같이 비즈니스 가치를 창출하는 리소스 및 코드 모음즉, RDBMS 는 개념 / 객체에 MongoDB는 성능에 중점을 둔다고 이해했다.
-
One VS Workload
RDBMS 는 고유한 정규화된 솔루션, MongoDB는 워크로드에 따른 여러 솔루션 (=샤딩?)
-
정규화 VS 단순화, 성능
모델링 시, 결정을 내리는 기준.
MongoDB 스키마 모델링 하는 방법
-
워크로드를 분석한다.
-> 데이터 관련 작업 목록들을 정리하여, 워크로드가 읽기/쓰기 작업에 지배되는지 여부를 체크한다. -
서로 다른 엔터티 간의 관계를 모델링한다.
-> 일대일, 일대다, 다대다 관계를 분석한 후, 하위 문서를 사용하여 그룹화 하거나 문서간의 엔터티를 연결한다. -
스키마 디자인 패턴을 적용한다.
-> MongoDB 모델링 패턴을 통해, 더 나은 모델링을 할 수 있으며 선택사항이다.
-> 참고 : https://rachyoo.tistory.com/29
워크로드 분석
- 쿼리 및 읽기/쓰기 작업에 대한 수치 및 자격을 분석하여 정리한다.
- 가장 빈번하고 중요한 쿼리에 대해 더 집중하여 모델링을 한다.
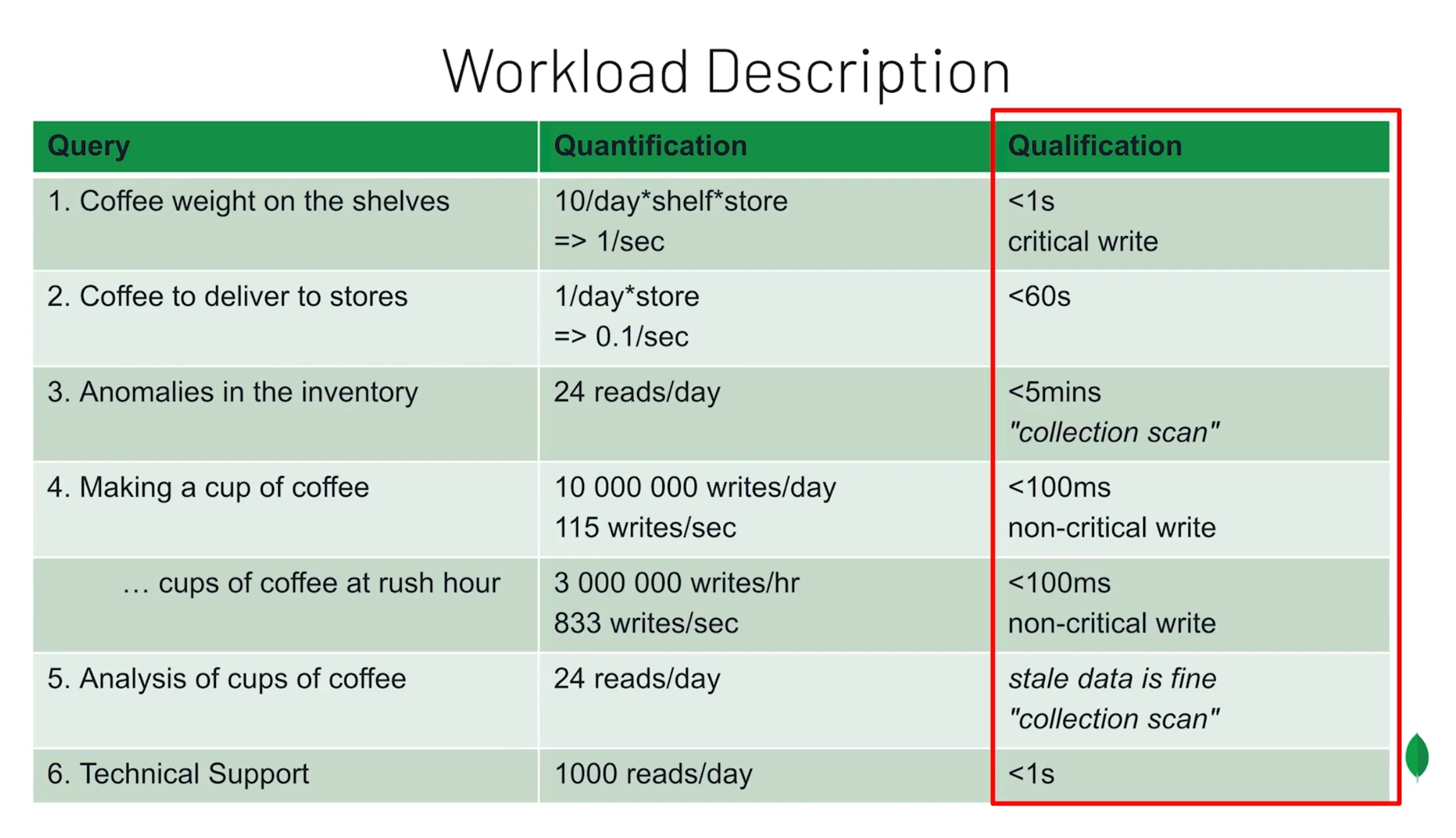
-
Data Staleness
-> 데이터에 대해 어느정도의 부실성을 수용할 수 있느냐에 따라 모델링을 한다.
-> 사용자의 계정 정보는 가장 최신화 된 데이터를 읽어야 하지만, 레스토랑 리뷰 같은 경우는 몇분 동안 최신 리뷰를 읽어오지 않아도 괜찮다. -
Sizing
-> 데이터 셋트의 예상 크기는 샤딩의 여부를 결정한다.
-> 데이터 셋트의 크기가 거대하지 않으면 샤딩을 할 필요성이 적으나, 큰 경우에는 관리하기 쉬운 크기로 줄이도록 샤딩을 하면 된다.
서로 다른 엔터티 간의 관계를 모델링
- 서로 다른 엔터티 간의 관계에 대해 하위 문서로 포함할지, 문서들끼리 연결할지 결정해야 한다.
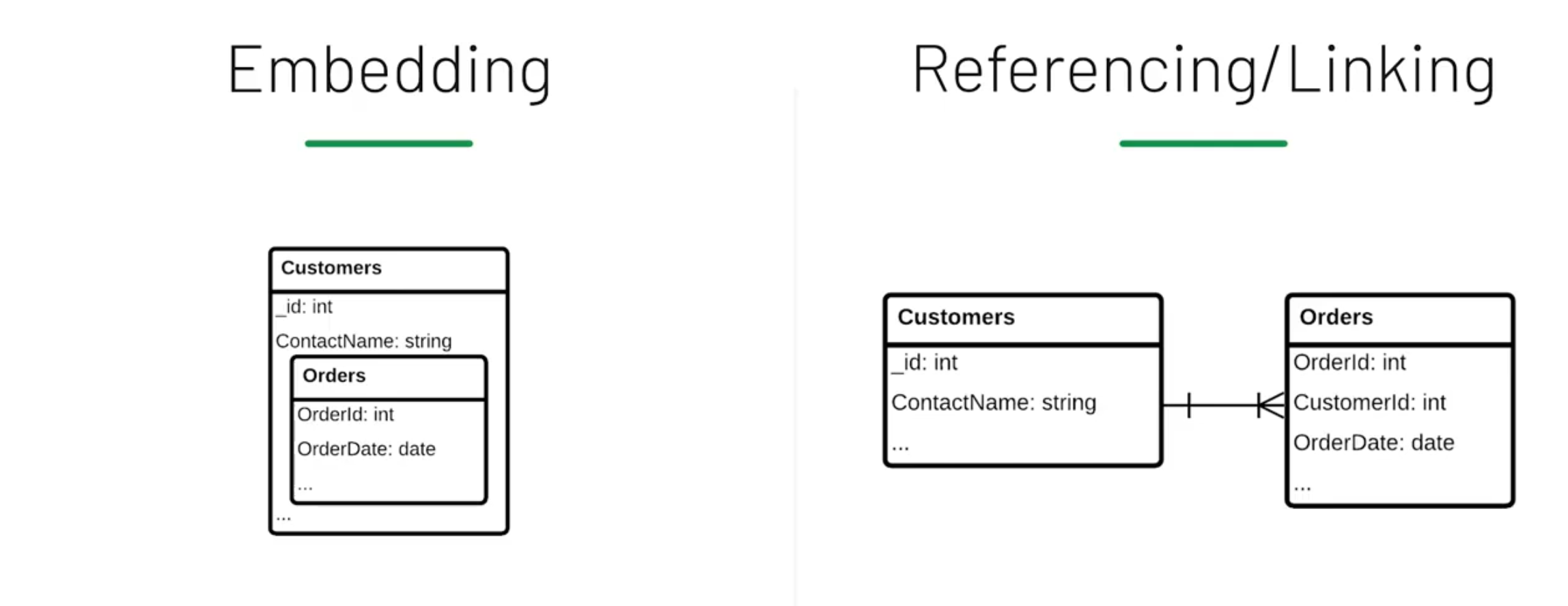
- 포함
- 부모 엔터티에 외래키가 필요없다.
- 상위 항목이 있는지 확인할 필요가 없다.
- 삭제 시 암시적 계단식 삭제가 발생한다.
- 연결 (= 참조)
- 쿼리에서 $lookup 을 사용하여 서로 다른 컬렉션의 두 문서를 결합하거나, 후속 쿼리를 사용하여 두번째 컬렉션에서 문서를 가져온다.
MongoDB 스키마 유효성 검사
- MongoDB 는 문서기반의 유연한 스키마를 제공하므로, 모든 값에 모든 유형의 데이터를 넣을 수 있다는 잘못된 개념이 있다.
- MongoDB 는 JSON 스키마를 사용하여, 완전하고 엄격한 유효성 검사를 수행하는 방법을 제공한다.

샤딩
- 대부분의 워크로드는 서버가 처리할 수 있는 양의 데이터를 저장하므로 샤딩이 필요하지 않다.
- 쓰기/읽기 작업에 따른 샤딩이 필요한지 파악하고, 우선순위를 정해야한다.
- 데이터 양이 증가함에 따라 성능이 가장 좋은 샤딩키는 무엇인지 고려해야한다.
데이터 무결성
-
엔터티 무결성 : 고유한 기본 키를 갖도록 보장된다.
-> 따로 무결성 고유키를 설정하지 않은 경우, 몽고 서버가 문서에 고유한 값을 _id 필드에 추가한다.
-> 더 많은 필드를 기준으로 복합 인덱스를 제공하여 고유성을 보장한다.
-> 인덱스와 문서 변경사항은 자동으로 커밋되어 가능한 빨리 무결성을 보장한다. -
외래 키 무결성 : MongoDB 컬렉션 간에 자동으로 이뤄지지 않는다.
-> 자식 관계를 임베딩하여 관계를 모델링하는 경우, 외래 키 개념도 적용되지 않는다.
-> 문서 모델에서는 상위 엔티티를 삭제하면 포함된 하위 엔티티가 자동으로 삭제되는 계단식 삭제를 만족한다. -
도메인 무결성 : 데이터가 유형 및 값 집합으로 제한되는 도메인 무결성은 두가지 방법으로 달성할 수 있다.
-> 문서 유효성 검사를 사용한다. (JSON 스키마)
-> 컬렉션을 사용하여 값 목록을 저장하고 이러한 값을 조회 연산자와 결합할 수 있다. -
사용자 정의 무결성 : 저장 프로시저 및 관계형 데이터베이스로 자주 구현되는 사용자 정의 무결성은 변경 스트림으로 달성할 수 있다.
-> 변경 스트림은 문서가 삽입,수정 또는 삭제 시 이벤트가 발생한다. 이를 통해 변경사항을 수신하여 무결성 검사를 실행할 수 있다.
-> Atlas Triggers을 사용하여, 무결성 검사를 수행하는 코드를 추가할 수 있다.
