- What is Replication?
복제는 데이터의 여러 복사본을 유지 관리하는 개념입니다.
- 유효성
- 복제 세트
- 기본 노드
- 보조 노드
- 장애 조치
- 선거/투표
- 데이터 동기화
- Repilca Set
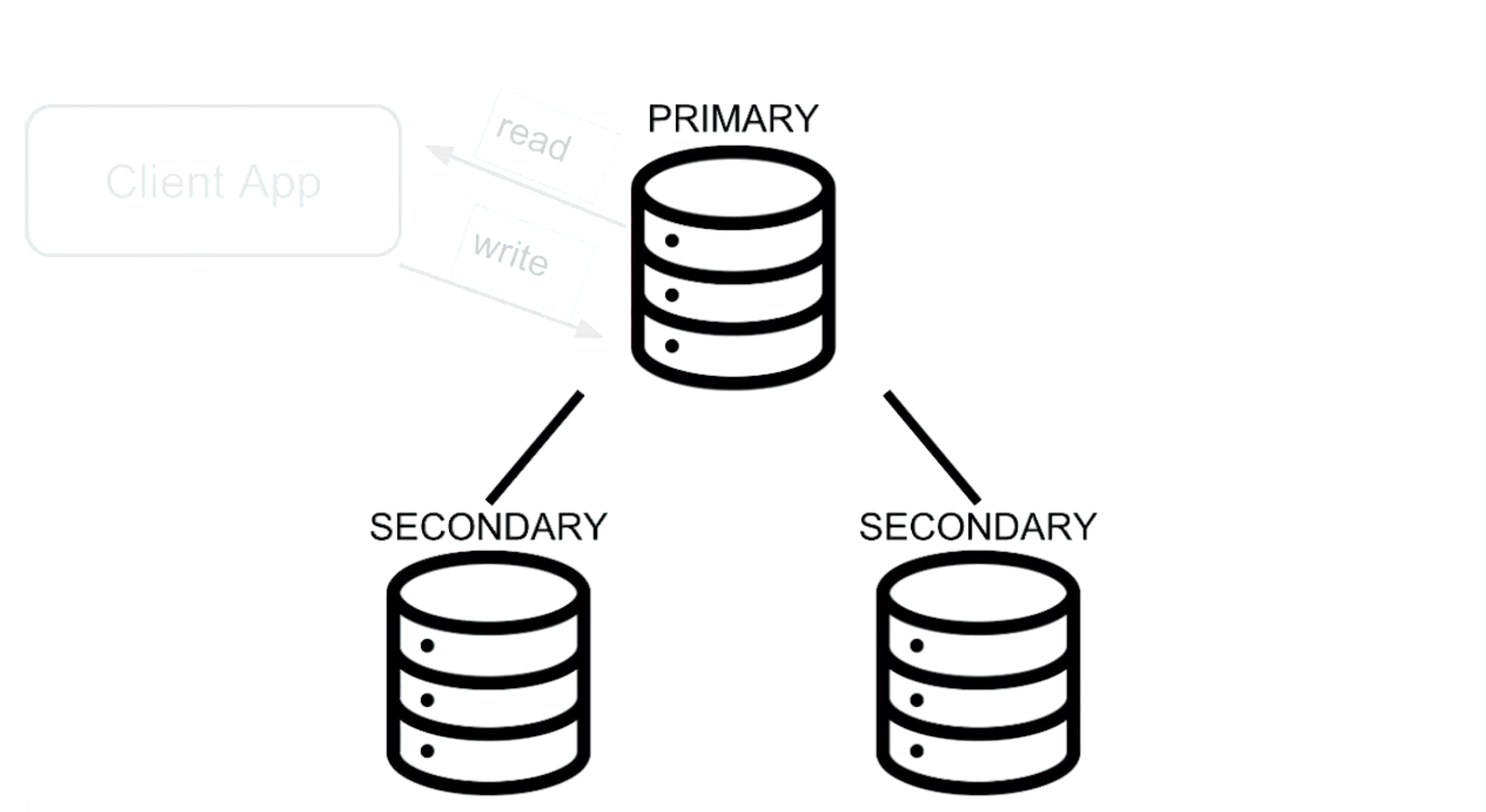
- Primary: 클라이언트에서 DB로 읽기 및 쓰기 작업을 한다.
- Secondary: 프라이머리로부터 데이터를 동기화 한다. Primary에 장애가 발생한 경우, 투표를 통해 Primary가 될 수 있다. 클라이언트 단에서 read preference 설정을 하면 secondary도 read operation을 수행할 수 있다.
- Arbiter: 데이터를 동기화하지는 않으며 primary 선정을 위한 투표권만 주어진다.
-
Replication Commands
rs.status() : 설정 내역이 아닌 Replica set 과 구성 멤버들의 상태 정보를 확인한다.
rs.isMaster() : 어떤 노드가 Primary가 되었는지 확인한다.
db.serverStatus()['repl'] : replicat set 서버 상태를 확인한다.
rs.printReplicationInfo() : OPlog Size 및 보관 기간 확인한다. -
Local DB
oplog(operation log) : 마스터 노드에 요청되는 연산들이 로그로 기록되는 파일이며,
local이라는 이름의 db 내의 oplog.rs(rs는 Replica Set의 이름)이라는 이름의 컬렉션 내에 저장된다. -
Read Concern
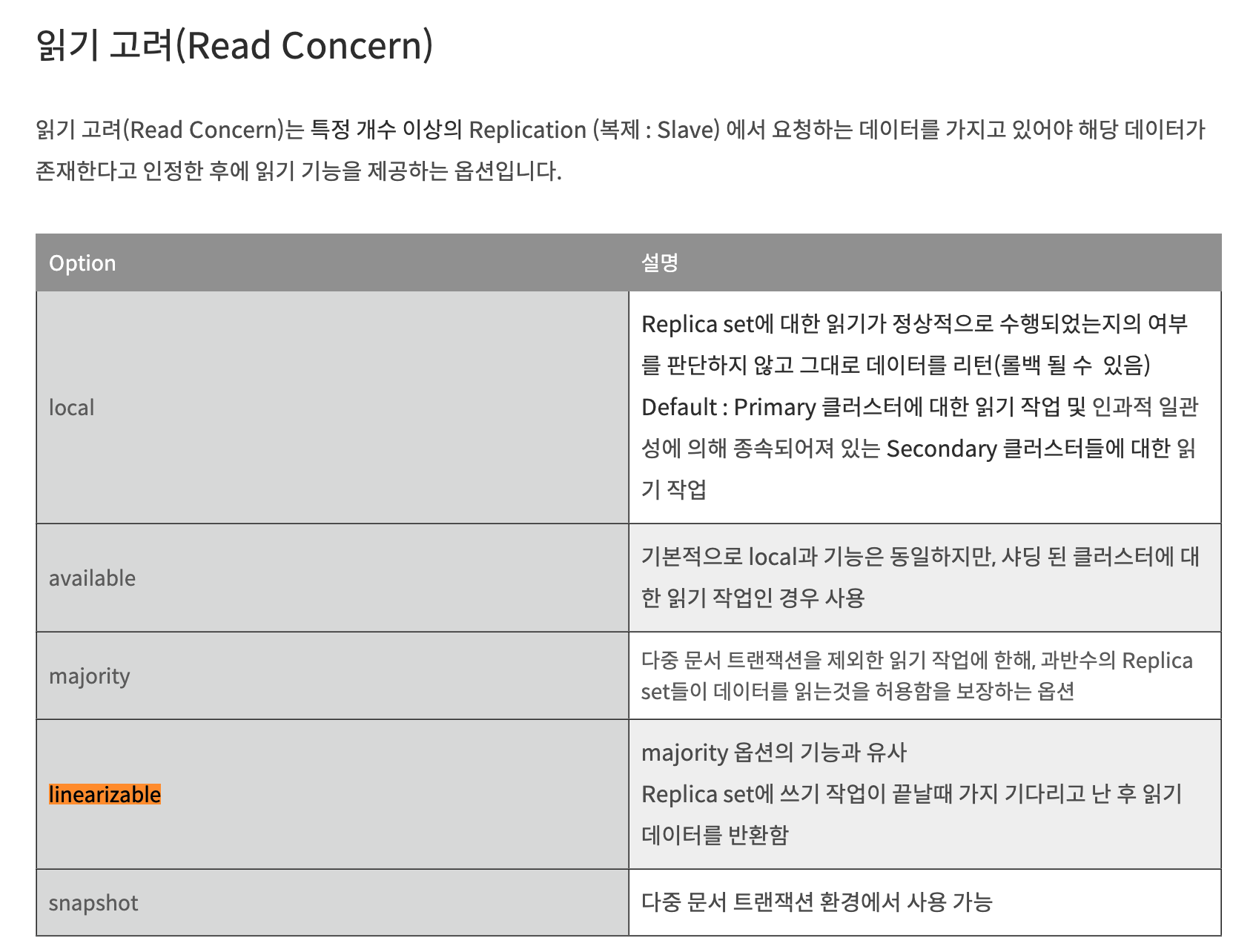
참고 : https://dlaudtjr03.tistory.com/17
-
Read Preference
-
primary: 기본값이며, Primary 구성원으로부터 값을 읽고 오며, 딜레이 없이 데이터 수정 및 삽입 작업이 가능.
-
primaryPreferred: Primary 구성원으로부터 우선적으로 데이터를 읽어옵니다. 특별히 Primary 쪽의 읽기 작업이 밀려있지 않으면 Primaey에서 데이터를 가져오기 때문에 변경사항을 바로 확인하다. 읽기가 밀려 있는 상태라면 Secondary에서 데이터를 읽는다.
-
secondary: 모든 읽기 작업을 Secondary 에서 처리한다.
-
secondaryPreferred: 우선적으로 읽기 작업이 발생하면 Secondary에 작업을 요청한다. 하지만 모든 Secondary에서 작업이 밀려 있는 경우 Primary에 읽기 작업을 요청한다.
-
nearest: 해당 구성원이 Primary인지 Secondary인지에 관계없이 네트워크 대기 시간이 가장 짧은 복제본 세트의 구성원에서 읽기 작업을 한다.
