6. 집계 (aggregation)
(실무에서 제일 많이 사용할 것 같다...)
MongoDB 집계 프레임워크(aggregation framework)를 사용하여 보다 복잡한 쿼리를 포함할 수 있도록 주제를 확장할 것이다. 집계 프레임워크는 MongoDB의 고급 쿼리언어로, 여러 도큐먼트의 데이터를 변환하고 결합하여 단일 도큐먼트에서 사용할 수 없는 새로운 정보를 생성할 수 있다.
예) 전자 상거래 데이터의 월별 매출, 제품별 매출 또는 사용자별 주문 합계
관계형 데이터베이스에 익숙한 사용자는 집계 프레임워크를 SQL의 GROUP BY 절과 동일하다고 생각할 수 있을 것이다. 이전에 MongoDB의 map reduce 기능이나 프로그램 코드를 사용하여 이 정보를 계산할 수 있었지만, 집계 프레임워크는 한번의 호출로 일련의 도큐먼트 작업을 정의한 다음 MongoDB에 배열의 형태로 보낼 수 있으므로 작업을 훨씬 쉽고 효율적으로 수행할 수 있다.
6.1 집계 프레임워크 개요
집계 프레임워크에 대한 호출은 파이프라인의 각 단계에서의 출력이 다음 단계로의 입력으로 제공되는 파이프라인.
즉, 집계 파이프라인(aggregation pipeline)을 정의한다.

- $project : 출력 도큐먼트 상에 배치할 필드를 지정한다. (projected)
- $match : 처리될 도큐먼트를 선택하는 것. find()와 비슷한 역할을 수행한다.
- $limit : 다음 단계에 전달될 도큐먼트의 수를 제한한다.
- $skip : 지정된 수의 도큐먼트를 건너뛴다.
- $unwind : 배열을 확장하여 각 배열 항목에 대해 하나의 출력 도큐먼트를 생성한다.
- $group : 지정된 키로 도큐먼트를 그룹화한다.
- $sort : 도큐먼트를 정렬한다.
- $geoNear : 지리 공간위치 근처의 도큐먼트를 선택한다.
- $out : 파이프라인의 결과(출력)을 컬렉션에 쓴다.
- $redact : 특정 데이터에 대한 접근을 제어한다.
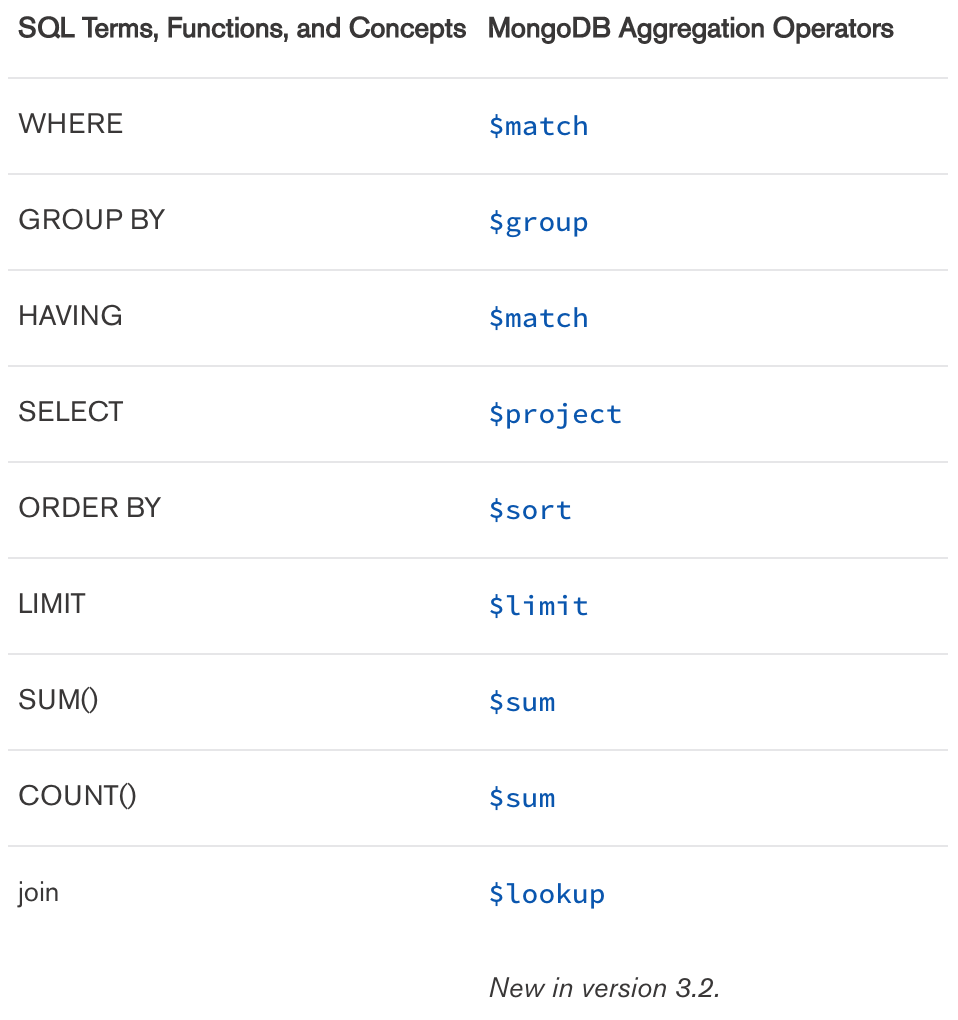
SQL vs 집계 프레임워크 비교
6.3 집계 파이프라인 연산자
집계 프레임워크는 10개의 연산자를 지원한다.
(아마 지금은 더 많은 연산자가 존재하지 않을까?..했는데 아닌거 같음.)
- $project : 처리할 도큐먼트의 필드를 지정한다.
- $group : 지정된 키별로 도큐먼트를 그룹화한다.
- $match : 처리할 도큐먼트를 선택한다. find(...)와 비슷하다.
- $limit : 다음 단계에서 처리할 도큐먼트의 수를 제한한다.
- $skip : 지정된 수의 도큐먼트를 건너뛰고 이를 다음 단계로 전달하지 않는다.
- $unwind : 배열을 확장하여 각 배열 항목에 대해 하나의 출력 도큐먼트를 생성한다.
- $sort : 도큐먼트를 정렬한다.
- $geoNear : 지리학적 공간 위치 근처의 도큐먼트를 선택한다. (오호..감이 안오는데?)
- $out : 파이프라인의 결과를 컬렉션에 기록한다.
- $redact : 특정 데이터에 대한 접근을 제어한다.
6.3.1 $project
$project 연산자는 쿼리 프로젝션 옵션에서 사용할 수 있는 모든 기능을 포함한다.
db.user.find( ◀ collection
{ num: { $gt: 29} }, ◀ query criteria
{ val1: 1, val2: 1 } ◀ projection
).limit(10) ◀ cursor modifierdb.user.aggregate([ ◀ collection
{ $match: {num: { $gt: 29} }}, ◀ query criteria
{ $project: { val1: 1, val2: 1 }} ◀ projection
])쿼리 프로젝션 옵션에 대해 이전에 설명한 것과 동일한 기능을 사용하는 것 외에도 많은 수의 도큐먼트 재형성(reshaping) 기능을 사용할 수 있다. 이러한 기능들이 너무 많아서 $group 연산자의 _id를 정의하는 데에도 사용할 수 있다.
6.3.2 $group
$group 연산자는 대부분의 집계 파이프라인에서 사용되는 주 연산자다. 이는 여러 도큐먼트의 데이터 집계를 처리하는 연산자로서 min, max 및 average와 같은 함수를 사용하여 요약 통계를 제공한다.
SQL 에 익숙한 사용자의 경우 $group 함수는 SQL GROUP BY 절과 동일하다.
- $addToSet : 그룹에 고유한 값의 배열을 만든다.
- $first : 그룹의 첫번째 값, $sort를 선행해야만 의미가 있다.
- $last : 그룹의 마지막 값, $sort를 선행해야만 의미가 있다.
- $max : 그룹의 필드 최댓값
- $min : 그룹의 필드 최솟값
- $avg : 필드의 평균값
- $push : 그룹의 모든 값의 배열을 반환한다. (중복값을 제거하지 않는다)
- $sum : 그룹의 모든 값의 합계
$addToSet vs $push
$push는 요소의 중복 허용 / $addToSet는 요소의 중복 비허용
6.3.3 $match / $sort / $skip / $limit
이 연산자를 사용하면 특정 도큐먼트를 선택하고 정렬하며 지정된 수의 도큐먼트를 건너뛰고 처리되는 도큐먼트의 수의 크기를 제한할 수 있다.
6.3.4 $unwind
배열의 모든 항목에 대해 하나의 출력 도큐먼트를 생성하여 배열을 확장한다.
각 배열 항목의 필드뿐만 아니라 주 도큐먼트의 필드도 출력 도큐먼트에 저장된다.
6.3.5 $out
파이프라인의 최종 출력물을 $out 연산자를 사용하여 지정 컬렉션에 저장한다.
$out 연산자는 파이프라인의 마지막 연산자여야 한다.
파이프라인의 결과로 새 컬렉션이 만들어지거나 컬렉션이 이미 존재하는 경우 컬렉션의 내용을 완전히 대체하여 기존 인덱스를 유지한다.
로드된 결과는 컬렉션에 있는 모든 제한 조건을 준수해야 한다. 예를 들어, 모든 컬렉션 도큐먼트는 고유한 _id를 가져야 한다. 몇몇 이유로 $out 연산 전이나 도중에 실패하는 등 파이프라인이 실패하면 기존 컬렉션은 변경되지 않는다.
6.4 도큐먼트 재구성
MongoDB 집계 파이프라인은 도큐먼트를 변형하여 출력 도큐먼트를 생성하는데 사용할 수 있는 많은 함수를 포함하고 있는데, 이때 출력 도큐먼트는 원본 입력 도큐먼트에는 존재하지 않는 필드를 포함한다.
가장 간단한 재형성 기능은 필드의 이름을 변경하여 새 필드를 작성하는 것이지만, 기존 도큐먼트 구조를 변경한거나 새로운 구조를 생성하여 도큐먼트의 모양을 바꿀 수도 있다.
6.4.1 문자열 함수
$concat 연산자
$concat 연산자는 두 개 이상의 문자열을 하나의 문자열로 연결한다.
예) { concat : { "ltem", "-", "$description"] }
$indexOfBytes 연산자
$indexOfBytes 연산자는 바이트 수로 인덱스를 반환한다.
예){ Desk", "-"] }
$indexOfCP 연산자
$indexOfCP 연산자는 문자열에서 특정 문자가 처음 생겼을 때 인덱스 코드 포인트( CP )에서 찾아내면
필드내의 문자열을 분석하는 데 도움이 된다.
예) { Desk", "-" ] }
위 쿼리에서 처음 등장하는 하이픈 문자를 검색해보면
문자열 인코딩이 다르면 사용하는 연산자가 달라지는데, 뒤에 CP를 붙인 것은 UTF-8 문자열에서 작동한다.
$split 연산자
문자열로 특정 인덱스를 찾는 것은 지정된 연산자에 유용하지만,
구분 기호를 기준으로 문자열을 배열 분할하는 것도 도움이 될 수 있다.
쿼리를 복잡하게 작성해 각 구분 기호를 찾을 수도 있다.
문자열로 특정 인덱스를 찾는 데 단일 명령으로 $split을 사용할 수 있다.
아래 쿼리에서 필드의 위치의 각 구성요소를 배열로 구분한다.
예) { Desk", "-" ] }
$strLenBytes 연산자
$strLenBytes 연산자를 사용해 문자열 길이를 바이트 단위로 알아낼 수 있다.
예) { Desk" }
$strLenCP 연산자
UTF-8 문자열의 길이를 반환한다.
예) { name" }
$strcasecmp 연산자
$strcasecmp 연산자는 두 개의 문자열의 대소를 비교하여 크면 1을 반환하고 작으면 -1, 같으면 0을 반환한다.
예) { quarter", "13q4" ] }
$substr 연산자
$substr 연산자는 ASCII 문자열의 일부분을 잘라서 반환한다.
값에 문자열, 시작문자 위치, 문자길이 순으로 넣는다.
예) { quarter", 2, 1 ] }
$substrBytes 연산자
문자열의 일부분을 잘라서 바이트로 반환한다.
예) { snum", "$$z", 1 ] }
$substrCP 연산자
UTF-8 문자열의 일부분을 잘라서 반환한다.
값에 문자열, 시작문자 위치, 문자길이 순으로 넣는다.
예) { quarter", 2, 1 ] }
$toLower 연산자
문자열의 모든 문자를 소문자로 만든다.
예) { item" }
$toUpper 연산자
문자열의 모든 문자를 대문자로 만든다.
예) { item" }
6.4.2 산술 함수
$add : 배열 번호를 추가한다.
$divide : 첫 번째 숫자를 두 번째 숫자로 나눈다.
$mod : 첫 번째 숫자의 나머지를 두 번째 숫자로 나눈다.
$multiply : 숫자 배열을 곱한다.
$subtract : 첫 번째 숫자에서 두 번째 숫자를 뺀다.
6.4.3 날짜/시간 함수
$dayOfYear : 연 중의 일로서 1에서 366까지다.
$dayOfMonth : 월 중의 일로서 1에서 31까지다.
$dayOfWeek : 주 중의 일로서 1에서 7까지이며, 1은 일요일을 의미한다.
$year : 날짜의 연 부분이다.
$month : 날짜의 월 부분으로 1 에서 12 까지다.
$week : 연 중의 주로서, 0 에서 53 까지다.
$hour : 시간을 뜻하고, 0 에서 23 까지다.
$minute : 분을 뜻하고, 0 에서 59 까지다.
$second : 초를 뜻하고, 0 에서 59 까지다.
$millisecond : 시간 중 밀리초를 뜻하며, 0 에서 999 까지다.
6.4.4 논리 함수
find 쿼리 연산자와 비슷하다.
$and : 배열 내의 모든 값이 true 인 경우 true
$cmp : 두 개 값을 비교하여 결괏값을 반환해 주며, 두 값이 동일하면 0 을 반환한다.
$cond : if ... then ... else 조건부 논리
$eq : 두 값이 동일한지의 여부 확인
$gt : 하나의 값이 다른 하나의 값보다 큰지의 여부 확인
$gte : 하나의 값이 다른 하나의 값보다 크거나 같은지의 여부 확인
$ifNull : null 값 / 표현식을 지정된 값으로 변환한다 .
$lt : 하나의 값이 다른 하나의 값보다 작은지의 여부 확인
$lte : 하나의 값이 다른 하나의 값보다 작거나 같은지의 여부 확인
$ne : 두 값이 동일하지 않은지에 대한 여부 확인
$not : 주어진 값의 반대 조건을 반환한다. 값이 true이면 false를 반환하고 false 이면 true 를 반환한다 .
$or : 배열의 값 중 그 어떤 하나라도 true 인 경우는 true
6.4.5 집합 함수
집합(set) 연산자를 사용하여 두 배열의 내용을 비교한다.
$setEquals : 두 개의 집합이 완전히 같은 요소를 가지는 경우 true
$setIntersection : 두 개의 집합에서 공통적으로 존재하는 요소의 배열을 반환한다.
$setDifference : 두 번째 집합에 없는 첫 번째 집합의 요소를 반환한다.
$setUnion : 두 집합의 합집합을 반환한다.
$setInSubset : 두 번째 집합이 첫 번째 집합의 부분집합이면 true
$anyElementTrue : 집합의 요소 중 그 어느 하나라도 true 이면 true
$allElementTrue : 집합의 모든 요소가 true 일 경우에만 true
6.4.6 기타 함수
$meta : 텍스트 검색 관련 정보에 접근한다.
$size : 배열의 크기를 반환한다.
배열에 요소가 포함되어 있거나, 비어 있는지 여부를 확인하려는 경우에 유용하다.
$size 함수를 사용하면 필드값을 0, 1 또는 $로 초기화할 때 발생하는 문제를 피할 수 있다.
$map : 배열의 각 멤버에 표현식 ( expression )을 적용한다.
$map 함수를 사용하면 배열의 각 요소에 하나 또는 그 이상의 기능을 수행하여 배열을 처리하고, 새로운 배열을 생성할 수 있게 해준다.
$map 함수는 $unwind를 사용하지 않고 배열의 내용을 바꾸고 싶을 때 유용할 수 있다.
$let : 표현식의 범위 내에서 사용되는 변수를 정의한다.
$let 함수를 사용하면 여러 개의 $project 단계를 사용하지 않고도 임시 정의된 변수를 사용할 수 있다.
이 함수는 복잡한 일련의 기능이나 계산이 필요한 경우 유용할 수 있다.
$literal : 표현식의 값을 평가하지 않고 반환한다.
6.5 집계 파이프라인 성능에 대한 이해
집계 파이프라인의 성능에 중요한 영향을 미칠 수 있는 몇 가지 주요 고려사항은 다음과 같다.
- 파이프라인에서 가능한 한 빨리 도큐먼트의 수와 크기를 줄인다.
- 인덱스는 $match와 $sort 작업에서만 사용할 수 있고, 이러한 작업을 크게 가속화할 수 있다.
- $match 또는 $sort 이외의 연산자를 파이프라인에서 사용한 후에는 인덱스를 사용할 수 없다.
- sharding을 사용하는 경우(매우 큰 컬렉션을 사용하는 경우 일반적인 방법) $match 및 $project 연산자는 개별 샤드에서 실행된다. 다른 연산자를 사용하면 남아 있는 파이프라인이 프라이머리 샤드에서 실행된다.
6.5.1 집계 파이프라인 옵션
aggregate() 함수에 전달할 수 있는 두 번째 매개변수가 있다.
- explain : 파이프라인을 실행하고 오직 파이프라인 프로세스 세부 정보만 반환한다.
- allowDiskUse : 중간 결과를 위해 디스크를 사용한다.
- cursor : 초기 배치 크기를 지정한다.
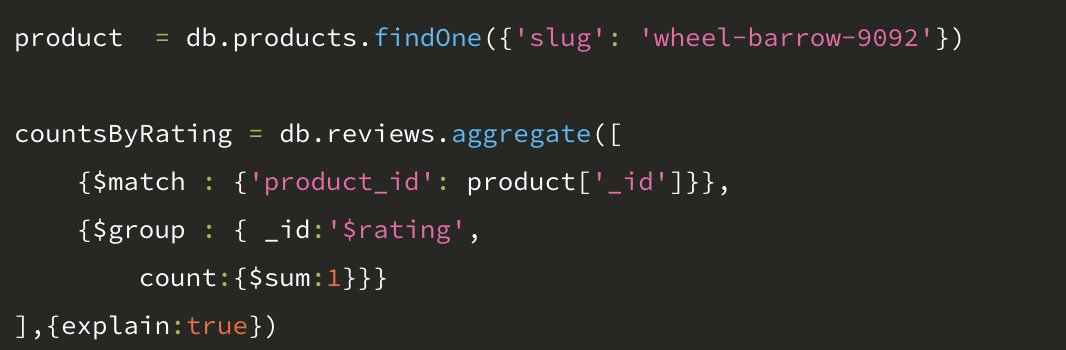
6.5.2 집계 파이프라인의 explain() 함수
MongoDB explain() 함수는 쿼리 경로를 설명하고 개발자가 쿼리에서 사용한 인덱스를 밝혀 냄으로써 느린 연산을 할 수 있도록 한다.
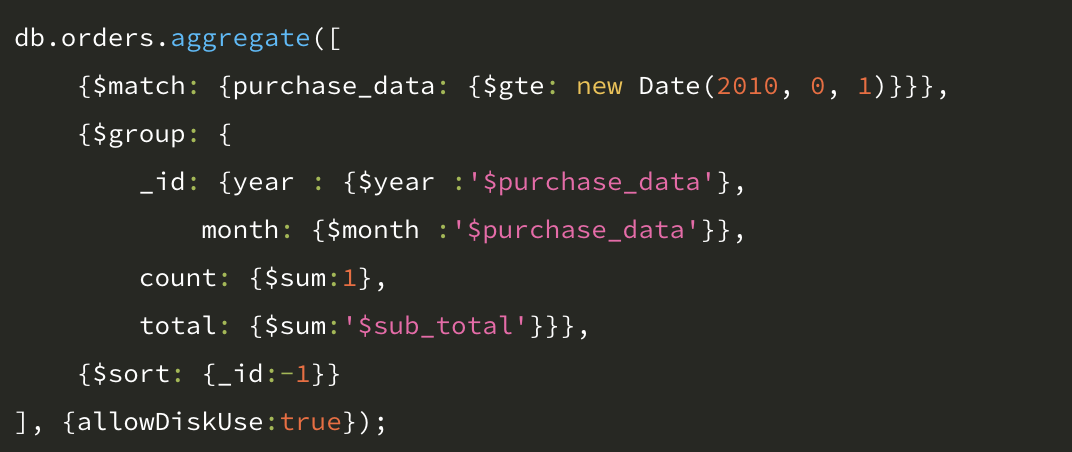
6.5.3 allowDiskUse 옵션
allowDiskUse 옵션을 사용하면 파이프라인 속도가 느려질 수 있으므로 필요할 때만 사용하는 것이 좋다.
allowDiskUse 옵션이 true 라면, 집계 함수 실행 중에 용량이 필요한 경우 디스크를 확장 시킨다.
6.5.4 집계 커서 옵션
cursor.hasNest() : 결과에 다음 도큐먼트가 존재하는지 확인한다.
cursor.next() : 결과에서 다음 도큐먼트를 반환한다.
cursor.toArray() : 전체 결과를 배열로 반환한다.
cursor.forEach() : 결과의 각 행에 대해 함수를 실행한다.
cursor.map() : 결과의 각 행에 대해 함수를 실행하고,함수 반환 값의 배열을 반환한다.
cursor.itcount() : 항목 수를 반환한다(테스트전용).
cursor.pretty() : 형식을 갖춘 결과의 배열을 표시한다.
6.6 기타 집계 기능
집계 파이프라인은 이제 MongoDB에서 데이터를 집계하는 데 많이 선호하는 방법으로 간주되지만, 몇 가지 대안 역시 가능하다. 일부는 .count() 함수와 같이 훨씬 간단하다. 또 다른 보다 복잡한 대안은 오래된 MongoDB map-reduce 함수다.
6.6.1 .count()와 .distinct()
count() : 개수 구하는 함수
review_count = db.reviews.count({'product_id' : product['_id']})
distinct() : 중복 제거 함수
db.orders.distinct('stripping_address.zip')
6.6.2 맵리듀스
맵리듀스는 유연한 집계 기능을 제공하려는 MongoDB의 첫 번째 시도였다.
(집계 프레임워크 생성 전, 집계기능을 제공하던 초기 버전 인가..?)
맵리듀스를 사용하면 전체 프로세스를 정의할 때 자바스크립트를 사용할 수 있다.
이는 많은 유연성을 제공하지만, 일반적으로 집계 프레임워크보다 훨씬 느리다.
또한, 맵리듀스 프로세스를 코딩하는 것은 우리가 구축한 집계 파이프라인보다 훨씬 복잡하고 직관적이지 않다.
map-reduce 메서드는 map 함수와 reduce 함수를 인자로 요구한다.
- map : 그룹화 중인 키를 정의하고, 계산에 필요한 모든 데이터를 패키지화한다.
- reduce : 값을 줄인다.
예) 월 단위로 그룹화하고 각 주문의 소계 및 항목수를 줄인다.
맵리듀스는 자바스크립트의 유연성을 제공하지만, 단일 스레드 및 해석이 제한적이다.
한편, 집계 프레임워크는 네이티브 C++ 및 멀티 스레드로 실행된다.
( 맵리듀스는 집계 프레임워크 보다 성능이 별로로 보이는데 최근에 쓰이는 경우가 있을까? )
6.7 요약
$group 연산자는 집계 프레임워크의 핵심 기능인 여러 도큐먼트의 데이터를 단일 도큐먼트로 집계하는 기능을 제공한다. $unwind 및 $project와 함께 집계 프레임워크는 분당 최대 요약 데이터를 생성하거나 대량의 데이터를 오프라인으로 처리할 수 있는 가능을 제공하며, $out 명령을 사용하여 결과를 새 컬렉션으로 저장할 수도 있다.
(오프라인으로 처리한다는게 뭘까?..)
