8. 인덱싱과 쿼리 최적화
8.1 인덱싱의 이론적 고찰
8.1.1 개념 실현
두꺼운 요리책이 5000페이지로 이루어져 있으며 요리법에는 특별한 순서가 없다. 3,475페이지에는 호주의 오리 찜 요리가 있으며, 2페이지에는 자카테칸 타코가 있다.
인덱스가 없이 요리책에서 로즈메리 감자 요리법을 찾을 수 있을까?
유일한 방법은 그 요리법이 나올 때까지 처음부터 훑어 나가는 것이다.
이에 대한 해결책이 인덱스를 생성하는 것이다.
- 단순 인덱스(simple index)
요리법을 찾기 위해서는 여러 가지 방법을 생각해 낼 수 있지만, 가장 좋은 방법은 요리법의 이름으로 찾는 것이다.
티벳 야크 수페:45
구운 소금 덤플링 : 4,011
터키 알 라 킹 : 943
요리법의 이름을 알거나 혹은 그 이름의 처음 몇 글자만이라도 안다면 이 인덱스를 이용해서 요리법을 신속하게 찾을 수 있다. 요리법은 이름으로만 찾는다면 이 인덱스로 충분하다.
재료나 지역에 따른 요리법을 찾을 수도 있는데, 이런 경우에는 좀 더 많은 인덱스가 필요하다.
단순인덱스는 유용할까?
( 음..명확하게 요리법 이름을 알면 괜찮은데 재료만 알고 요리법을 찾기에는 어렵다. 즉, 한계가 있다고 생각! )
- 복합 인덱스 (compound index)
명확한 요리법 이름을 기억할 수 없는 경우, 해결책은 복합 인덱스를 사용하는 것이다.
인덱스에 대한 한 가지의 데이터 아이템만 사용하지 않고 두 가지의 데이터를 사용할 것이다.
이렇게 하나 이상의 키를 사용하는 인덱스를 복합 인덱스(compound index) 라고 부른다.
복합인덱스는 순서가 중요하다.
재료-이름 인덱스를 생성했다고 가정하면, 재료부터 찾고 해당 재료인덱스에 있는 이름을 찾기 때문이다.
이 복합 인덱스가 존재하면 재료에 대한 단일 키 인덱스는 삭제해도 문제가 없다.
재료로 검색 할 때 재료-이름의 복합 인덱스를 사용하면 되기 때문이다.
쿼리당 하나의 인덱스
두 필드에 대해 검색할 떄 각 필드에 대한 두 개의 인덱스를 별도로 만들면 검색이 용이해질 것이라고 일반적으로 생각한다. 이것에 대한 알고리즘은 이렇다.
각각의 필드에 대한 인덱스에서 검색어와 일치하는 페이지 번호를 찾고 이 페이지 번호들의 교차 지점에 대한 리스트를 스캔하면서 두 검색어와 일치하는 요리법을 찾는다.
많은 페이지가 일치하지 않을 것이지만 찾아봐야 할 아이템의 총 개수를 줄일 수 있다.
(= 인덱스 교차, MongoDB 2.6부터 지원됨)
복합 인덱스의 사용이나 인덱스 교차의 사용이 더 효울적인지 아닌지는 특정 쿼리 및 시스템에 따라 달라진다. 쿼리당 하나의 인덱스를 사용할 수 있고 하나 이상의 필드를 질의하려고 한다면 그 필드들에 대한 복합 인덱스가 반드시 존재해야 한다.
- 인덱싱 규칙
-
인덱스는 도큐먼트를 가져오기 위해 필요한 작업량을 많이 줄인다. 적당한 인덱스가 없으면 질의 조건을 만족할 때 까지 모든 도큐먼트를 차례로 스캔해야만 하고, 이것은 종종 컬렉션 전체를 스캔하는 것을 뜻한다.
-
한 쿼리를 실행하기 위해서 하나의 단일 키 인덱스만 사용할 수 있다. 한 가지 예외는 $or 연산자를 사용해서 질의할 때다. 하지만 MongoDB에서는 이것이 불가능하고 바람직하지 않다.
복합 키를 사용하는 쿼리에 대해서는 복합키 인덱스가 적당하다. -
재료-이름 대한 인덱스(ingredient-name) 를 가지고 있다면 재료에 대한 인덱스는 없앨 수 있고 또 없애야만 한다. 좀 더 일반적으로 표현해서 a-b에 대한 복합 인덱스를 가지고 있다면 a에 대한 인덱스는 중복이고, b에 대한 인덱스는 중복이 아니다.
( 복합 인덱스는 순서가 중요하기 때문! ) -
복합 인덱스에서 키의 순서는 매우 중요하다.
8.1.2 인덱싱 핵심 개념
- 단일 키 인덱스
단일 키 인덱스에서 인덱스 내의 각 엔트리는 인덱스되는 도큐먼트 내의 한 값과 일치한다.
_id에 대해 디폴트로 생성되는 인덱스가 좋은 예인데, 각 도큐먼트의 _id는 빠른 검색을 위해 인덱스에 저장된다.
- 복합 키 인덱스 (compound-key index)
하나 이상의 속성으로 질의해야 할 경우가 자주 있고, 그러한 질의를 가능한 한 효율적으로 수행해야 한다.
현재 MongoDB는 아래와 같은 방식을 지원하지 않는다.
각 인덱스를 따로 탐색해서 일치하는 디스크 위치의 리스트를 합쳐 교차점을 계산하는 방식
그 이유 중 하나는 복합 인덱스를 사용하는 것이 좀 더 효율적이기 때문이다.
복합 인덱스는 각 엔트리가 하나 이상의 키로 구성된 인덱스다.
제조사와 가격에 대한 복합키(compound-key)를 생성하면 아래 그림과 같은 순서를 갖게 된다.
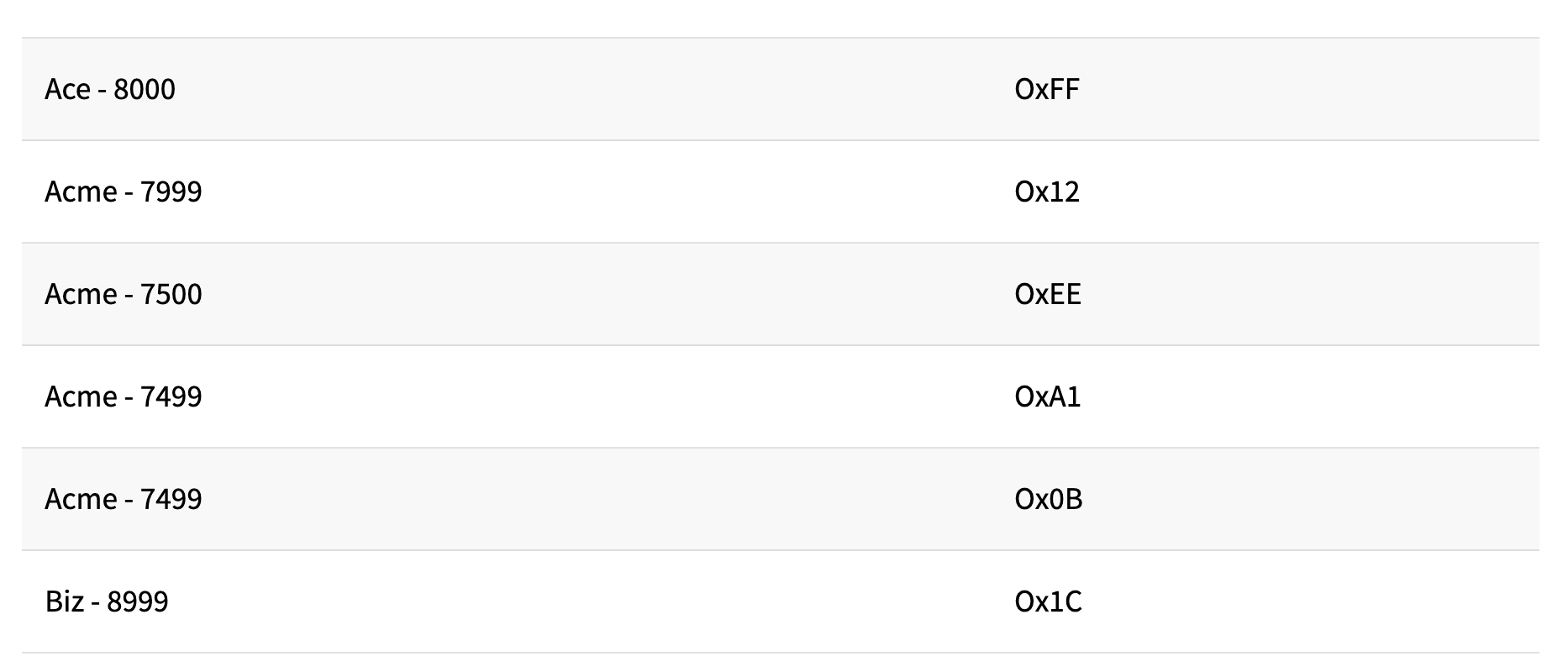
쿼리를 수행하기 위해 쿼리 옵티마이저는 인덱스 내에서 제조사가 ‘Acme’이고 가격이 75불인 첫 번째 엔트리를 찾아야 한다. 맨 위에서 부터 시작해서 제조사 값이 Acme가 아닌 엔트리를 발견할 때까지 인덱스 내의 엔트리를 스캔 함으로써 결과를 얻을 수 있다.
- 인덱스 효율
쿼리 성능을 위해서는 인덱스가 반드시 필요하지만 각 인덱스는 유지 비용이 들어간다.
어떤 컬렉션에 도큐먼트를 추가할 때마다 그 컬렉션에 대해 생성된 인덱스도 그 새로운 도큐먼트를 포함시키도록 수정해야 한다.
따라서, 어떤 컬렉션이 10개의 인덱스를 가지고 있다면 삽입 연산을 한 번 수행할 때마다 10개의 인덱스를 수정해야 한다. 읽기 위주의 애플리케이션에서 인덱스 비용은 인덱스로 인해 얻을 수 있는 효과로 상쇄된다.
인덱스가 적합하게 만들어졌다고 해도 쿼리를 더 빠르게 처리하지 못할 가능성이 여전히 존재한다는 점이다.
이것은 인덱스와 현재 작업 중인 데이터를 램에서 다 처리하지 못할 때 발생한다.
MongoDB는 운영체제에게 mmap() 시스템 호출을 이용해 모든 데이터 파일을 메모리에 매핑하는데,
이 시점부터는 모든 도큐먼트, 컬렉션, 인덱스를 포함하는 데이터 파일이 페이지라고(page)라고 부르는 4KB의 청크로 운영체제에 의해 램으로 스왑된다.
해당 페이지에 대한 데이터가 요청 될 때마다 OS는 그 페이지가 램에 있는지 확인해야 한다.
만약 램에 없으면 페이지 폴트(page fault) 예외를 발생 시키고 메모리 관리자는 해당 페이지를 디스크로부터 램으로 불러들인다.
램이 충분하면 모든 데이터 파일이 램으로 로드가 된다. 모든 데이터를 램이 수용하지 못하는 경우 점점 페이지 폴트가 발생하고 모든 읽기와 쓰기에 대해서 디스크 액세스를 해야 하는 상환이 발생할 수도 있다.
이러한 현상을 스래싱(thrashing)이라고 하는데, 성능을 심각하게 저해한다.
이상적으로는 인덱스와 현재 작업 중인 데이터가 모두 램에 존재해야 한다.
하지만 램의 필요한 크기를 추정하는 것이 항상 쉬운 것만은 아니다.
작업 데이터는 애플리케이션마다 다르기 때문에 어느 정도의 크기를 갖는지 명확히 알기가 어렵기 때문이다.
8.1.3 B트리
MongoDB는 내부적으로 B트리(B-tree)로 인덱스를 생성한다.
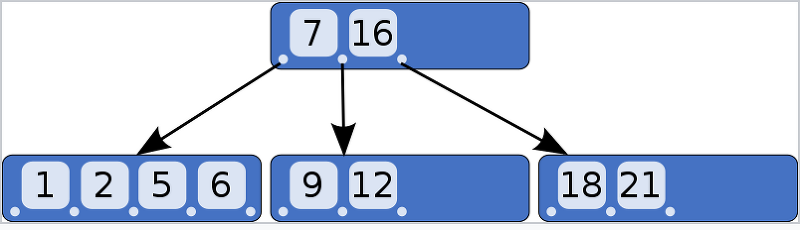
B트리는 데이터 베이스 인덱스에 이상적인 두 가지의 전반적인 특성을 가지고 있다.
- 정확한 일치, 범위 조건, 정렬, 프리픽스 일치, 인덱스만의 쿼리 등 다양한 쿼리를 용이하게 처리하도록 해준다는 점이다.
- 키가 추가되거나 삭제되더라도 밸런스된 상태를 계속 유지한다는 점이다.
8.2 인덱싱의 실제
MongoDB의 인덱싱에 대해 좀 더 자세하게 살펴보자.
8.2.1 인덱스 타입
- 고유 인덱스
고유 인덱스 고유 인덱스를 생성하기 위해서는 unique 옵션을 지정한다.
db.users.ensureIndex({username:1},{unique:true})
고유 인덱스는 컬렉션에 데이터가 존재하지 않을 때 생성하는 것이 좋다.
데이터가 있는 경우 고유 인덱스를 만들면, 컬렉션 내에서 중복 키가 존재할 가능성이 있기 때문이다. 하지만 데이터가 그다지 중요하지 않다면 데이터 베이스로 하여금 dropDups옵션을 이용해 중복 키를 가지고 있는 도큐먼트를 자동으로 삭제하도록 명령을 내릴 수 있다.
db.users.ensureIndex({username:1},{unique:true, dropDups:true})
- 희소인덱스 (sparse index)
인덱스는 밀집(dense)하도록 기본 설정되어 있다. 밀집 인덱스란 컬렉션 내의 한 도큐먼트가 인덱스 키를 가지고 있지 않더라도 인덱스에는 해당 엔트리가 존재한다는 것을 의미한다.
하지만 밀집 인덱스가 바람직하지 않은 경우가 있다.
첫 번째는 모든 도큐먼트의 sku 필드에 대해 고유 인덱스를 만든다고 가정하자.
하지만 sku필드에 대해 입력없이 등록할 수 있는 시스템이 있다. sku 입력없이 여러개의 도큐먼트를 삽입하려고 할 때 sku가 null인 인덱스가 이미 존재하기 때문에 이 후 에러가 발생 할 수 있다.
이런 경우에 희소 인덱스(sparse index)가 필요하다.
즉, null 값을 가질 수 있는 엔트리가 존재하면 null이 아닌 도큐먼트를 대상으로 인덱스를 걸 수 있다.
예) 익명으로만 된 상품평에 대한 질의를 거의 하지 않는다면 user_id에 대해 희소 인덱스를 생성할 수 있다.
db.users.ensureIndex({sku:1},{unique:true, sparse:true})
- 다중키 인덱스
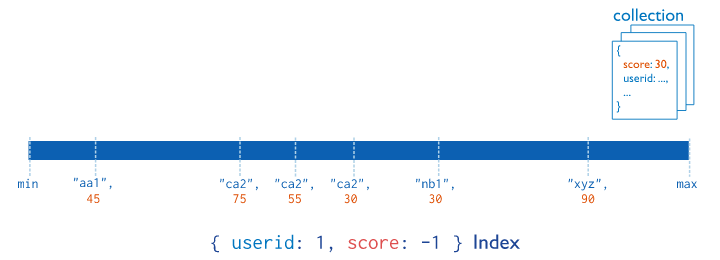
다중 키 인덱스 필드의 값이 배열인 경우 인덱스하는 것이 다중 키 인덱스인데, 인덱스 내의 여러 개의 엔트리가 동일한 도큐먼트를 지시하게 된다.
아래와 같은 형태의 도큐먼트들이 있다고 가정하자.
{
name:"Wheelbarrow",
tags: ["tools", "gardening", "soil"]
}tags에 대해 인덱스를 생성하면 이 도큐먼트의 태그 배열에 있는 각 값들은 인덱스에 나타난다.
이것은 이 배열의 값 중 어느 것으로도 도큐먼트를 찾을 수 있음을 의미한다.
- 해시 인덱스
db.collection.createIndex({recipe_name: 'hased'})
해시 된 샤드 키를 사용하여 샤딩 컬렉션을 지원한다.
필드의 해시 인덱스를 샤딩된 클러스터에서 데이터를 분할하기 위한 샤딩키로 사용한다는 의미이다.
해시 된 샤드 키를 사용해서 컬렉션을 샤딩하면 데이터를 더 고르게 분산시킬 수 있다.
다중 키 해시 인덱스는 허용되지 않는다.
(샤딩을 공부해야..이해할듯...?)
- 지리공간적 인덱스
각 도큐먼트에 저장된 위도값과 경도값에 따라 도큐먼트를 특정 위치에 '가까이' 배치하는 쿼리 기능이 있다. 특정 위치를 찾는 쿼리를 수행할 때, 지리 공간적 인덱스를 사용하여 효울적으로 계산할 수 있다.
(쓸 일이 없다..)
8.2.2 인덱스 관리
- 인덱스 생성과 삭제
일반적으로 인덱스를 생성하는데 헬퍼 메소드를 사용하는 것이 쉽지만 인덱스 규격을 직접 삽입(인덱스 헬퍼 메소드가 하는일)할 수도 있는데 ns, key, name 이렇게 최소한의 키를 지정하기만 하면 된다.
spec = {ns:"green.users", key:{'addresses.zip':1}, name:'zip'}
db.system.indexes.insert(spec, true)인덱스를 삭제하기 위해서 system.indexes에서 인덱스 도큐먼트를 삭제하면 될 것이라고 생각할지도 모르지만 이런 연산은 금지되어 있으며 deleteIndexes를 수행해서 인덱스를 삭제하면 된다.
- 인덱스 구축
인덱스 구축은 두 단계로 이루어진다.
- 인덱스 값을 정렬한다.
- 정렬된 값들이 인덱스로 삽입된다.
인덱스 선언 시 주의사항
인덱스를 선언하는 것이 너무 쉽기 때문에 의도치 않게 인덱스를 구축하는 것도 역시 아주 쉽다.
데이터가 대량일 경우 인덱스 구축은 오랜 시간이 걸린다. 실제 서비스 상황에서는 이것은 악몽과도 같다.
왜냐하면 인덱스 구축을 중지시키기가 쉽지 않기 때문이다.
만일 이런 일이 발생한다면, 세컨더리 노드가 있는 경우 이 노드로 서비스를 해야 할 것이다. 하지만 인덱스 구축을 일종의 데이터베이스 마이그레이션으로 취급하고 애플리케이션에서 인덱스 선언이 자동으로 되지 않도록 하는 것이 현명하다.
- 백그라운드 인덱싱
데이터베이스가 실제 서비스되고 있고 데이터베이스에 대한 액세스를 중지시킬 수 없을 경우 사용하는 방법.
어플리케이션의 트래픽이 최소화되는 시간 내에 인덱스를 구축할 수 있다면 좋은 방법이 될 수 있다.
- 오프라인 인덱싱
실제 서비스되괴 있는 데이터가 인덱스를 생성하는데 몇 시간으로는 부족할 정도로 큰 규모라면 다른 방법이 필요하다.
일반적으로 한 복제 노드를 오프라인 상태로 바꾸고, 그 노드에 대해 인덱스를 구축한 다음에 마스터 노드로부터 업데이트를 받는다. 업데이트를 완료하고 나면 이 노드를 프라이머리 노드로 변경하고, 다른 센컨더리 노드들은 오프라인 상태로 바꾼 후에 각자 인덱스를 구축한다.
이것은 오프라인 노드에서 인덱스를 구축하는 동안 데이터가 손상되는 것을 막을 정도로 복제 oplog가 충분히 크다는 가정을 전제로 한다.
(이해가 잘안되는데...10장에서 제대로 이해..)
- 백업
인덱스는 구축하기 어렵기 때문에 백업을 해놓아야 한다.
백업이 인덱스를 포함하길 원한다면 MongoDB의 데이터 파일 자체를 백업해야 한다.
자세한 내용과 일반적인 백업 명령은 10장에서 다룬다.
- DEFRAGMENTING(압축)
어플리케이션에서 기존 데이터의 업데이트나 대량의 데이터 삭제가 자주 발생한다면 인덱스가 심각하게 단편화된다. B트리는 어느 정도 스스로 재구성하지만 대량의 삭제를 상쇄시킬 만큼 충분치는 않다.
단편화된 인덱스의 일차적인 징후는 주어진 데이터의 크기보다 인덱스의 크기가 훨씬 더 큰 것이고, 이로인해 인덱스가 램을 필요이상으로 많이 사용할 수 있다. 이런 경우에 하나 혹은 그 이상의 인덱스를 재구축하는 것을 고려해야 한다. reIndex() 명령을 수행하여 개별 인덱스를 삭제하고 재생성함으로써 가능하다.
8.3 쿼리 최적화
쿼리 최적화는 느린 쿼리를 찾아서 원인을 발견하고, 속도를 개선하기 위한 조치를 취하는 과정이다. 애플리케이션의 잘못된 설계, 적합하지 않은 데이터 모델, 부족한 하드웨어는 모두 공통적인 원인이고, 이런 문제점을 해결하기 위해서는 많은 시간이 요구된다.
따라서, 쿼리를 재구성하고 좀 더 유용한 인덱스를 구축하여 쿼리 최적화를 해야한다.
8.3.1 느린 쿼리 탐지
요구사항이 애플리케이션마다 다르지만, 대부분 애플리케이션에서 쿼리가 100밀리초 이내에 실행되어야 한다고 가정하면 안전하다. MongoDB 로거는 이 가정에 근거, 질의를 포함해서 어떠한 연산이라도 100밀리초를 넘어서면 경고 메시지를 프린트한다.
느린 쿼리를 확인하기 위해서 MongoDB의 로그를 사용할 수 있지만, 이러한 절차가 정교하지 못하기 때문에 개발이나 서비스 환경에서 시도해볼 수 있는 일종의 점검 장치로 생각해야한다.
문제가 발생하기 전에 느린 쿼리를 찾기 위해서는 정확한 툴이 필요한데, MongoDB에 내장된 쿼리 프로파일러가 바로 그것이다.
- 프로파일러 사용
프로파일링은 디폴트로 사용 불가능 상태이므로 사용 가능 상태로 바꿔야한다.
use stocks
db.setProfilingLevel(2) 먼저 프로파일하려는 데이터베이스를 선택해야 한다.
프로파일링은 항상 특정 데이터베이스에 국한된다.
프로파일링 수준을 2는 출력이 가장 많이 되는 수준인데, 프로파일러가 모든 읽기와 쓰기를 로그에 기록한다.
프로파일링 결과는 system.profile이라고 부르는 특수한 캡드(capped)컬렉션에 저장된다.
캡드 컬렉션은 크기가 고정되어 있고 데이터는 회전되는 방식으로 쓰여지기 때문에 컬렉션이 허용된 크기에 도달하면 새로운 도큐먼트는 가장 오래된 도큐먼트를 덮어쓰게 된다.
이 컬렉션은 128KB가 할당되는데, 이로인해 프로파일러가 리소스를 많이 사용하지 못한다.
150밀리초 이상이 소요된 모든 쿼리를 찾고 싶으면 다음과 같이 한다.
db.system.profile.find({millis:{$gt:150}})
8.3.2 느린 쿼리 분석
- EXPLAIN()의 사용과 이해
explain 명령은 주어진 쿼리의 경로에 대한 자세한 정보를 제공한다.
(인덱싱 처리 후, explain() 명령으로 개선되는 예제 생략.. explain() 명령 시 출력 값 생략..이미 전 장에서 정리)
- MongoDB의 쿼리 옵티마이저
해당 쿼리를 가장 효율적으로 실행하기 위해 어떤 인덱스를 사용할 지 결정하는 소프트웨어다.
쿼리에 가장 이상적인 인덱스를 선택하기 위해 쿼리 옵티마이저는 다음과 같이 아주 간단한 규칙을 사용한다.
-
scanAndOrder를 피한다. 즉, 쿼리가 정렬을 포함하고 있으면 인덱스를 사용한 정렬을 시도한다.
-
유용한 인덱스 제한 조건으로 모든 필드를 만족시킨다. 즉, 쿼리 실렉터에 지정된 필드에 대한 인덱스를 사용하도록 노력한다.
-
쿼리가 범위를 내포하거나 정렬을 포함하면 마지막 키에 대해 범위나 정렬에 도움이 되는 인덱스를 선택하라
- HINT()
HINT()는 쿼리 옵티마이저로 하여금 강제로 특정 인덱스를 사용하도록 만드는 것이다.
특정 인덱스를 선택하지 않은 경우가 명확하지 않을 경우 사용하면 된다.
db.values.find({"stock_symbol":"GOOG"}).sort({data:-1}).limit(1).hint({stock_symbol:1}).explain()
쿼리를 프로파일하고 explain을 실행하는 것을 습관화해야한다.
