PART 4. 클라우드 네이티브 스프링
스프링 클라우드, 마이크로서비스(microservice) 개발을 소개하면서 단일 애플리케이션을 MSA로 분리하여 개발하는 방법을 알아본다.
13장에서는 MSA의 개요를 알아보고 서비스 발견(discovery)를 알아볼 것이다.
이 때, 스프링 기반의 MSA를 등록하고 발견하기 위해 넷플릭스의 유레카 서비스 레지스트리를 사용한다.
14장에서는 스프링 클라우드의 구성 서버를 사용해서 중앙 집중식 구성을 살펴본다.
구성 서버는 애플리케이션의 모든 서비스에 대한 중앙 집중식 구성을 제공한다.
15장에서는 Netflix의 Hystrix를 통하여 서비스를 보다 장애에 탄력적이도록 만드는 서킷 브레이커 패턴을 적용하는 방법을 알아본다.
- 이 장에서 배우는 내용
마이크로서비스 알아보기
서비스 레지스트리 생성하기
서비스 등록 및 발견하기
13.1 마이크로서비스 이해하기
단일 어플리케이션
배포 가능한 하나의 JAR 나 WAR 파일로 개발된 어플리케이션을 단일 어플리케이션이라고 한다.
단일 애플리케이션 문제점
-
전체를 파악하기 어렵다
: 코드가 점점 더 많아질수록 애플리케이션에 있는 각 컴포넌트의 역할을 알기 어려워진다. -
테스트가 더 어렵다
: 애플리케이션이 커지면서 통합과 테스트가 더 복잡해진다. -
라이브러리 간의 충돌이 생기기 쉽다
: 애플리케이션의 한 기능에서 필요한 라이브러리 의존성이 다른 기능에서 필요한 라이브러리 의존성과 호환되지 않을 수 있다. -
확장 시에 비효율적이다
: 시스템 확장을 목적으로 더 많은 서버에 애플리케이션을 배포해야 할 때는 애플리케이션의 일부가 아닌 전체를 배포해야 한다. 애플리케이션 기능의 일부만 확장하더라도 마찬가지다. -
적용할 테크놀로지를 결정할 때도 애플리케이션 전체를 고려해야 한다
: 애플리케이션에 사용할 프로그래밍 언어, 런타임 플랫폼, 프레임워크, 라이브러리를 선택할 때 애플리케이션 전체를 고려하여 선택해야 한다. -
프로덕션으로 이양하기 위해 많은 노력이 필요하다 (= 프로덕션으로 출시!)
: 애플리케이션을 한 덩어리로 배포하므로 프로덕션으로 이양하는 것이 더 쉬운 것처럼 보일 수 있다.
그러나 일반적으로 단일 애플리케이션은 크기와 복잡도 때문에 더 엄격한 개발 프로세스와 더욱 철두철미한 테스트가 필요하다.
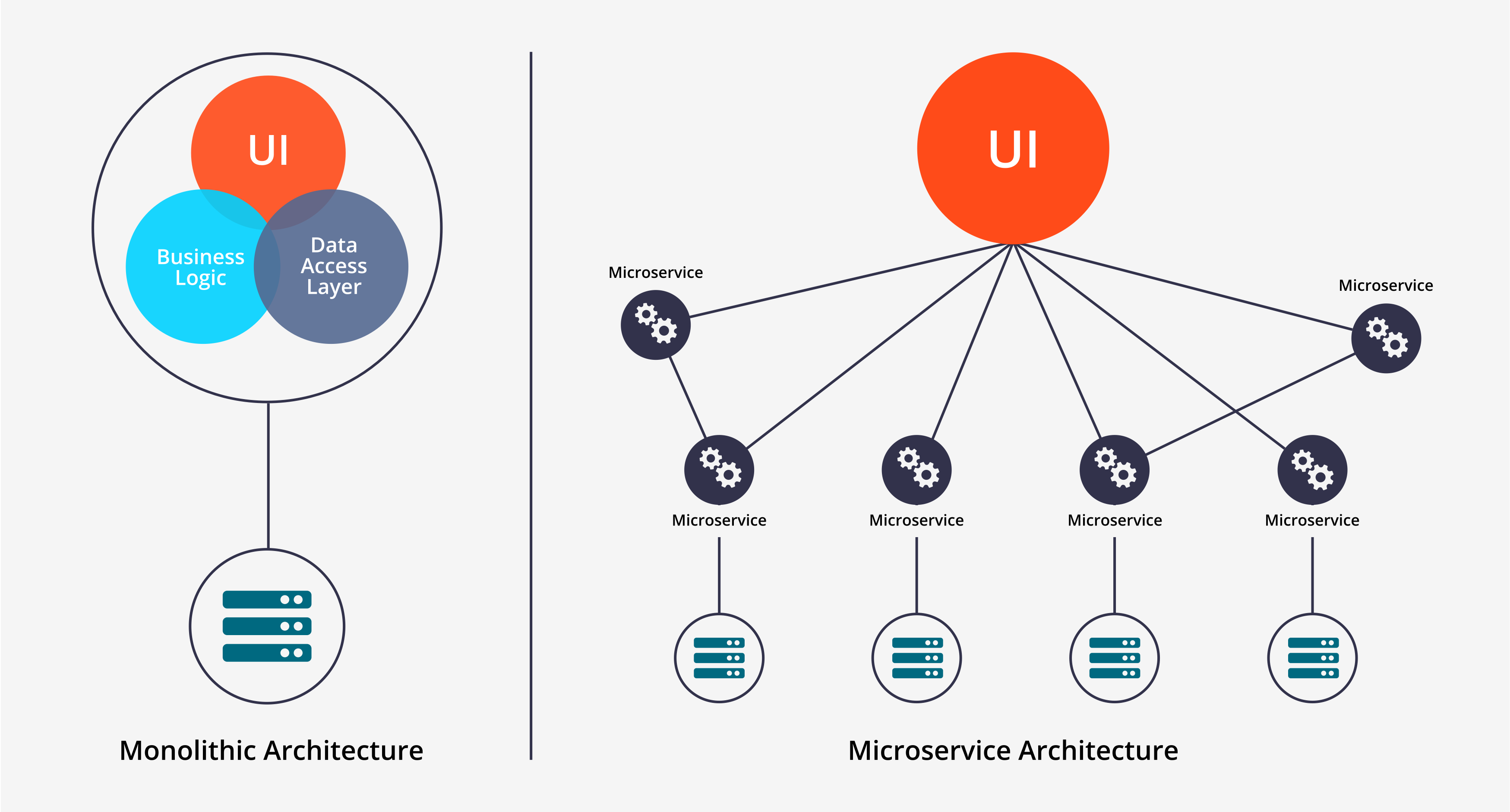
단일 애플리케이션의 문제를 해결하기 위해 지난 수년동안 마이크로서비스 아키텍처가 발전하였다.
마이크로서비스 아키텍처
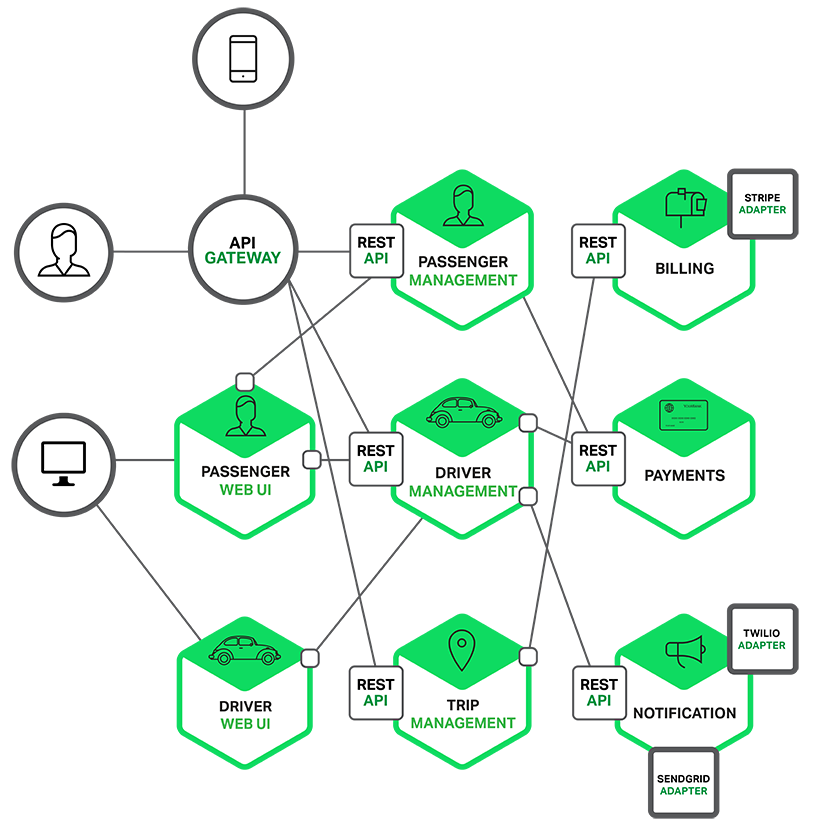
개별적으로 개발되고 배포되는 소규모의 작은 애플리케이션들로 애플리케이션을 만드는 방법이다.
마이크로서비스는 상호 협력하여 더 큰 애플리케이션의 기능을 제공한다.
마이크로서비스 아키텍처 특성
-
마이크로서비스는 쉽게 이해할 수 있다
: 다른 마이크로서비스와 협력할 때 각 마이크로서비스는 작으면서 한정된 처리를 수행한다.
따라서 마이크로서비스는 자신의 목적에만 집중하므로 더 이해하기 쉽다. -
마이크로서비스는 테스트가 쉽다
: 크기가 작을수록 테스트가 쉬어지는 것은 분명한 사실이다. -
마이크로서비스는 라이브러리 비호환성 문제가 생기지 않는다
: 각 마이크로서비스는 다른 마이크로서비스와 공유되지 않는 빌드 의존성을 가지므로 라이브러리 충돌 문제가 생기지 않는다. -
마이크로서비스는 독자적으로 규모를 조정할 수 있다
: 만일 특정 마이크로서비스의 규모가 더 커야 한다면, 애플리케이션의 다른 마이크로서비스에 영향을 주지 않고 메모리 할당이나 인스턴스의 수를 더 크게 조정할 수 있다. -
각 마이크로서비스에 적용할 테크놀러지를 다르게 선택할 수 있다
: 각 마이크로서비스에 사용할 프로그래밍 언어, 플랫폼, 프레임워크, 라이브러리를 서로 다른게 선택할 수 있다.
실제로 자바로 개발된 마이크로서비스가 C#으로 개발된 다른 마이크로서비스와 함께 동작하도록 할 수 있다. -
마이크로서비스는 언제든 프로덕션으로 이양할 수 있다
: 마이크로서비스 아키텍처 기반으로 개발된 애플리케이션이 여러 개의 마이크로서비스로 구성 되었더라도 각 마이크로서비스를 따로 배포할 수 있다.
그리고 마이크로서비스는 작으면서 특정 목적에만 집중되어 있고 테스트하기 쉬우므로, 마이크로서비스를 프로덕션으로 이양하는 데 따른 노력이 거의 들지 않는다.
또한, 프로덕션으로 이양하는 데 필요한 시간도 수개월이나 수주 대신 수시간이나 수분이면 된다.
모든 어플리케이션이 마이크로서비스 아키텍처에 적합한 것은 아니다.
마이크로서비스 아키텍처는 분산 아키텍처이므로 네트워크 지연과 같은 문제들이 발생할 수 있다.
애플리케이션이 상대적으로 작거나 간단하다면 일단 단일 애플리케이션으로 개발하는 것이 좋다.
그리고 점차 규모가 커질 때마이크로서비스 아키텍처로 변경하는 것을 고려할 수 있다.
13.2 서비스 레지스트리 설정하기
스프링 클라우드는 큰 프로젝트이며, 마이크로서비스 개발을 하는 데 필요한 여러 개의 부속 프로젝트로 구성된다.
이중 하나가 스프링 넷플릭스이며, 이것은 넷플릭스 오픈 소스로부터 다수의 컴포넌트를 제공한다.
이 컴포넌트 중에 넷플릭스 서비스 레지스트리인 유레카(Eureka)가 있다.
유레카(Eureka) 란?
마이크로서비스가 서로를 찾을 때 사용되는 서비스 레지스트리이다.
유레카는 마이크로서비스 애플리케이션에 있는 모든 서비스의 중앙 집중 레지스트리로 작동한다.
유레카 자체도 마이크로서비스로 생각할 수 있으며,
더 큰 애플리케이션에서 서로 다른 서비스들이 서로를 찾는 데 도움을 주는 것이 목적이다.
이러한 유레카의 역할 때문에 서비스를 등록하는 유레카 서비스 레지스트리를 가장 먼저 설정하는 것이 좋다.
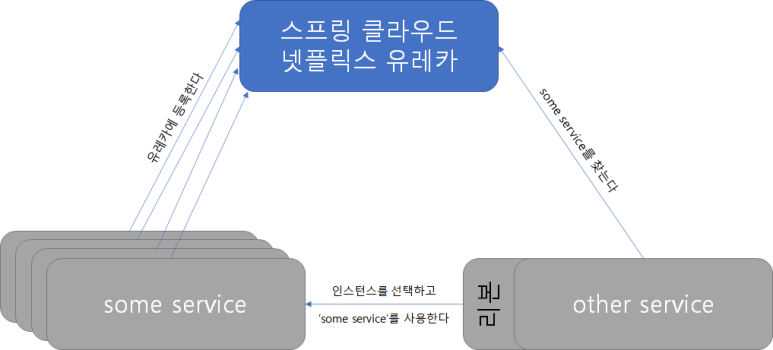
서비스 인스턴스가 시작될 때 해당 서비스는 자신의 이름을 유레카에 등록한다.
some service 의 인스턴스는 여러 개 생성될 수 있다.
그러나 이것들은 모두 같은 이름으로 유레카에 등록된다.
모든 마이크로서비스는 유레카에 자신을 30초에 한 번씩 등록한다.
other service가 유레카에서 'some service'란 이름으로 찾는다.
some service가 여러 개라면 리본이 인스턴스를 선택하고 해당 인스턴스를 사용한다.
클라이언트 측의 로드밸런서를 사용하는 이유 ( 리본을 사용하는 이유 )
- 리본 : 각 클라이언트에서 실행되는 클라이언트 측의 로드밸런서
클라이언트 측의 로드 밸런서인 리본은 중앙 집중화된 로드밸런서와 비교해 장점을 가진다.
- 클라이언트 수에 비례해 로드밸런서 크기가 조정된다.
- 각 클라이언트에 가장 적합한 로드 밸런싱 알고리즘을 사용하도록 수정할 수 있다.
유레카 프로젝트 생성하기
스프링 스타터 프로젝트 의존성 대화상자에 Spring Cloud Discovery를 확장한 후, Eureka Server를 선택하고 Finish를 클릭하여 프로젝트를 생성한다.
유레카 서버 스타터 의존성
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>스프링 클라우드 버전 의존성
<properties>
<spring-cloud.version>Hoxton.SR3</spring-cloud.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>ServiceRegistryApplication 클래스 변경하기
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootAppliation
@EnableEurekaServer
public class ServiceRegistryApplication {
@Test
public void contextLoads() {
}
}@EnableEurekaServer 애노테이션을 추가하여 유레카 서버를 활성화 시킨다.
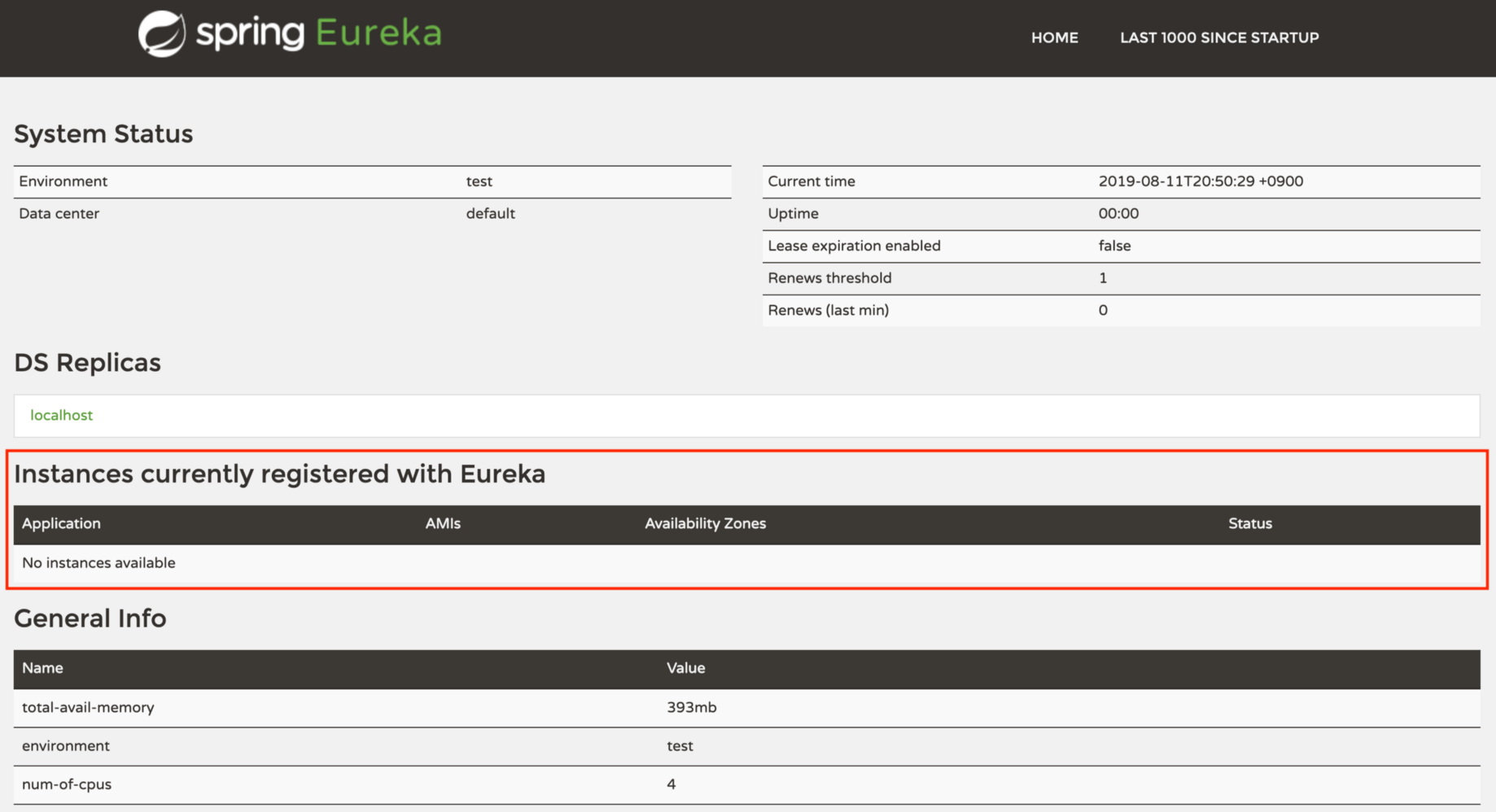
애플리케이션을 시작시키면 웹브라우저에서 유레카 대시보드가 나타난다.
대시보드에서 어떤 서비스 인스턴스가 유레카에 등록되었는지 알려준다.
서비스를 등록할 때 기대한 대로 잘 되었는지 확인하기 위해 유레카 대시보드를 자주 보게 될 것이다.
애플리케이션을 시작시키면 유레카가 30초 정도에 한 번씩 각종 예외 메시지를 출력하는 것을 볼 수 있다.
아직 레지스트리를 완전하게 구성하지 않았기 때문에 예외가 발생하는 것이다.
그런 예외가 나타나지 않도록 몇 가지 구성 속성을 추가할 것이다.
장애에 대비하기 위해 여러 개의 유레카 서버가 함께 동작하도록 하는 것이 안전하다.
따라서 기본적으로 유레카는 다른 유레카 서버로부터 서비스 레지스트리를 가져오거나 다른 유레카 서버의 서비스로 자신을 등록하기도 한다.
때문에 프로덕션 설정에서는 유레카를 두 대 이상 동작하게 된다. 그러나 개발 목적으로는 하나의 유레카 서버면 충분하다.
이 때 유레카 서버를 올바르게 구성하지 않으면 30초마다 예외 메시지를 출력한다. 유레카는 30초마다 다른 유레카 서버와 통신하면서 자신이 작동 중임을 알리고 레지스트리 정보를 공유하기 때문이다.
유레카 서버가 혼자임을 알도록 구성할 필요가 있다.
13.2.1 유레카 구성하기
하나보다는 여러 개의 유레카 서버가 함께 동작하는 것이 안전하므로 유레카 서버들이 클러스터로 구성되는 것이 좋다.
왜냐하면 여러 개의 유레카 서버가 있을 경우 그중 하나에 문제가 발생하더라도 단일 장애점은 생기지 않기 때문이다.
따라서 기본적으로 유레카는 다른 유레카 서버로부터 서비스 레지스트리를 가져오거나 다른 유레카 서버의 서비스로 자신을 등록하기도 한다.
개발 시에는 두 개 이상의 유레카 서버를 실행하는 것은 불편하기도 하고 불필요하다.
그러나 유레카 서버를 올바르게 구성하지 않으면 30초마다 예외의 형태로 로그 메시지를 출력한다.
왜냐하면 유레카는 30초마다 다른 유레카 서버와 통신하면서 자신이 작동 중임을 알리고 레지스트리 정보를 공유하기 때문이다.
따라서 유레카 서버가 혼자임을 알도록 구성이 필요하다.
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: <http://$>{eureka.instance.hostname}:${server.port}/eureka/eureka.client.fetchRegistry와 eureka.client.registerWithEureka는 유레카와 상호 작용하는 방법을 알려주기 위해 다른 마이크로서비스에 설정할 수 있는 속성들이다.
두 속성을 false로 설정하면 연결되는 다른 마이크로 서비스가 없다는 의미이다.
마지막으로 eureka.client.serviceUrl 속성은 영역(zone) 이름과 이 영역에 해당하는 하나 이상의 유레카 서버 URL을 포함하며, 이 값은 Map에 저장된다.
Map의 키인 defaultZone은 클라이언트가 자신이 원하는 영역을 지정하지 않았을 때 사용된다.
유레카 기본 포트는 8080 이나, server.port 로 지정할 수 있다.
자체-보존 모드를 비활성화시키기
eureka:
...
server:
enable-self-preservation: false일반적으로 세 번의 갱신 기간(또는 90초) 동안 서비스 인스턴스로부터 등록 갱신 요청을 받지 못하면 해당 서비스 인스턴스의 등록을 취소하게 된다.
그리고 만일 이렇게 중단되는 서비스의 수가 임계값을 초과하면 유레카 서버는 네트워크 문제가 생긴 것으로 간주하고 레지스트리에 등록된 나머지 서비스 데이터를 보존하기 위해 자체-보존 모드가 된다.
따라서 추가적인 서비스 인스턴스의 등록 취소가 방지된다.
개발 환경에서는 자체-보존 모드를 활성화하면 중단된 서비스의 등록이 계속 유지되어 다른서비스가 해당 서비스를 사용하려고 할 때 문제를 발생시킬 수 있기 때문에 false 로 설정한다.
13.3 서비스 등록하고 찾기
유레카 클라이언트 스타터 의존성 추가하기
애플리케이션을 서비스 레지스트리 클라이언트로 활성화하기 위해서는
해당 서비스 애플리케이션의 pom.xml 파일에 유레카 클라이언트 스타터 의존성을 추가해야 한다.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>
spring-cloud-starter-netflix-eureka-client
</artifactId>
</dependency>13.3.1 유레카 클라이언트 속성 구성하기
서비스의 기본 이름인 UNKNOWN을 그대로 두면 유레카 서버에 등록되는 모든 서비스 이름이 같게 되므로 변경해보자.
spring:
application:
name: ingredient-service이제 유레카 대시보드에 ingredient-service 라는 이름으로 서비스가 나타난다.
server:
port: 0서비스 포트의 충돌을 막기위해 포트를 0으로 설정한다.
서버 포트를 0으로 설정하면 각 서비스 애플리케이션이 시작될 때 포트 번호가 무작위로 선택된다.
(포트가 무작위로 설정이 되어도 해당 설정 정보를 유레카에서 관리되므로 서비스 통신 간의 문제는 없다.)
eureka:
client:
service-url:
defaultZone: http://eureka1.tacocloud.com:8761/eureka/,
http://eureka2.tacocloud.com:8762/eureka/위 url의 포트로 리스닝하는 유레카 서버에 등록되도록 클라이언트가 구성된다.
장애 대비를 위해 두 개의 유레카 서버를 사용하도록 구성했다.
이렇게 되면 첫 번째 유레카 서버에 등록을 시도하고, 실패하면 두번째에 피어(peer)로 지정된 유레카 서버의 레지스트리에 등록을 시도하게 된다. 실패했던 유레카 서버가 온라인이 되면 해당 서비스의 등록 정보가 포함된 피어 서버 레지스트리가 복제된다.
13.3.2 서비스 사용하기
스프링 클라우드의 유레카 클라이언트 지원에 포함된 리본 클라이언트 로드 밸런서를 사용하여 서비스 인스턴스를 쉽게 찾아 선택하고 사용할 수 있다.
유레카 서버에서 찾은 서비스를 선택 및 사용하는 방법에는 다음 두 가지가 있다.
- 로드 밸런싱된 RestTemplate
- Feign에서 생성된 클라이언트 인터페이스
RestTemplate 사용해서 서비스 사용하기
RestTemplate이 생성되거나 주입되면 HTTP 요청을 수행하여 원하는 응답을 받을 수 있다.
public Ingredient getIngredientById(String ingredientId) {
return rest.getForObject("<http://localhost:8080/ingredients/{id}>",
Ingredient.class, ingredientId);
}위 코드에는 한 가지 문제점이 있다.
getForObject()의 인자로 전달되는 URL이 특정 호스트와 포트로 하드코딩되었다는 것이다.
일단 유레카 클라이언트로 애플리케이션을 활성화했다면 로드 밸런싱된 RestTemplate 빈을 선언할 수있다. 이때는 기존대로 RestTemplate 빈을 선언하되, @Bean과 @LoadBalanced 애노테이션을 메서드에 같이 지정하면 된다.
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}@LoadBalanced 애노테이션은 두 가지 목적을 갖는다.
RestTemplate이 리본을 통해서만 서비스를 찾는다는 것을 스프링 클라우드에 알려준다.
주입 식별자로 동작한다. 주입 식별자는 서비스 이름이며, getForObject() 메서드의 HTTP 요청에서 호스트와 포트 대신 사용할 수 있다.
public Ingredient getIngredientById(String ingredientId) {
return rest.getForObject(
"<http://ingredient-service/ingredients/{id}>",
Ingredient.class, ingredientId);
}이렇게 사용하면 내부적으로는 ingredient-service 라는 서비스 이름을 찾아 인스턴스를 선택하도록 RestTemplate이 리본에 요청한다. 그리고 선택된 서비스 인스턴스의 호스트와 포트 정보를 포함하도록 리본이 URL을 변경한 후 원래대로 RestTemplate이 사용된다.
WebClient로 서비스 사용하기
RestTemplate을 사용했던 것과 같은 방법으로 WebClient를 로드 밸런싱된클라이언트로 사용할 수 있다.
WebClientConfig.java
@Configuration
public class WebClientConfig {
@Bean
@LoadBalanced
public WebClient.Builder webClientBuilder() {
return WebClient.builder();
}
...
}IngredientServiceClient.java
@Service
@Profile("webclient")
public class IngredientServiceClient {
private WebClient.Builder wcBuilder;
public IngredientServiceClient(@LoadBalanced WebClient.Builder wcBuilder) {
this.wcBuilder = wcBuilder;
}
public Mono<Ingredient> getIngredientById(String ingredientId) {
return wcBuilder.build()
.get()
.uri("http://ingredient-service/ingredients/{id}", ingredientId)
.retrieve().bodyToMono(Ingredient.class);
}
Feign 클라이언트 인터페이스 정의하기
Feign은 REST 클라이언트 라이브러리이며, 인터페이스를 기반으로 하는 방법을 사용해서 REST 클라이언트를 정의한다. 마치 스프링 데이터가 리퍼지터리 인터페이스를 자동으로 구현하는 것과 유사한 방법을 사용한다.
구성 클래스 중 하나에 @EnableFeignClients 애노테이션을 추가해야 한다.
@Configuration
@Profile("feign")
@Slf4j
@EnableFeignClients
public class FeignClientConfig {
@Bean
public CommandLineRunner startup() {
return args -> {
log.info("**************************************");
log.info(" Configuring with Feign");
log.info("**************************************");
};
}
}이제는 Feign을 사용할 때가 되었다. 이때는 다음과 같이 인터페이스만 정의하면 된다.
@FeignClient("ingredient-service")
public interface IngredientClient {
@GetMapping("/ingredients/{id}")
Ingredient getIngredient(@PathVariable("id") String id);
@GetMapping("/ingredients")
Iterable<Ingredient> getAllIngredients();
}Feign이 자동으로 구현 클래스를 생성한 후 스프링 애플리케이션 컨텍스트에 빈으로 노출시킨다.
요약
- 스프링 클라우드 넷플릭스 자동-구성과 @EnableEurekaServer 애노테이션을 사용해서 넷플릭스 유레카 서비스 레지스트리를 쉽게 생성할 수 있다.
- 다른 서비스가 찾을 수 있도록 마이크로서비스는 이름을 사용해서 자신을 유레카 서버에 등록한다.
- 리본은 클라이언트 측의 로드 밸런서로 동작하면서 서비스 이름으로 서비스 인스턴스를 찾아 선택한다.
- 리본 로드 밸런싱으로 처리되는 RestTemplate 또는 Feign에 의해 자동으로 구현되는 인터페이스를 사용해서 클라이언트 코드는 자신의 REST 클라이언트를 정의할 수 있다.
- 로드 밸런싱된 RestTemplate, WebClient 또는 Feign 클라이언트 인터페이스 중 어느 것을 사용하더라도 서비스의 위치(호스트 이름과 포트)가 클라이언트 코드에 하드 코딩되지 않는다. (유레카에서 관리된다!)
