1. 최신 웹을 위한 도큐먼트 데이터베이스
1.1 MongoDB 란?
웹 애플리케이션과 인터넷 기반을 위해 설계된 데이터베이스 관리 시스템이다.
데이터 모델과 지속성 전략은 높은 읽기/쓰기 효율과 자동 장애조치(failover)를 통한 확장의 용이성을 염두에 두고 만들어졌다.
애플리케이션에서 필요한 데이터베이스 노드가 하나거나 혹은 그 이상이거나에 관계없이 MongoDB는 놀라울 정도로 좋은 성능을 보여준다.
개발자들이 MongoDB를 사용하는 이유는 아마도 확장성 때문이 아니라 직관적인 데이터 모델 때문일 것이다.
MongoDB는 그 정보를 행(row) 대신에 도큐먼트(document)에 저장한다.
예) 도큐먼트
{
_id : 10,
username : 'peter',
email : [
'pbbskkum@gmail.com',
'pbb7c@gmail.com'
]
}MongoDB의 도큐먼트 형식은 임의의 데이터 구조를 저장하는 스키마로 잘 알려진 JSON에 기반한다.
JSON은 JavaScript Object Notation의 약어다. 방금 본 것 처럼 JSON 구조는 키(key)와 키에 대한 값(value) 으로 이루어져 있고, 중첩에 제한이 없다. JSON은 프로그래밍 언어에서 사전(dictionary)이나 해시 맵(hash map)과 유사하다.
도큐먼트 기반의 데이터 모델은 풍부하고 계층적인 구조의 데이터를 표현할 수 있다. 따라서 관계 데이터베이스에서 필요한 여러 테이블 간의 복잡한 조인 연산이 없어도 된다.
1.2 MongoDB의 핵심 기능
MongoDB의 복제와 수평적 확장을 중심으로 한 데이터베이스 연산에 대해서도 살펴보겠다.
1.2.1 도큐먼트 데이터 모델
MongoDB는 도큐먼트 지향적인 데이터베이스다.

도큐먼트(document)는 본질적으로 속성의 이름과 값으로 이루어진 쌍의 집합이다.
속성의 값은 문자열이나 숫자, 날짜와 같이 간단한 데이터 타입이 될 수 있다.
하지만 이 값은 또한 배열이나 심지어 다른 JSON 도큐먼트가 될 수도 있다.
내부적으로 MongoDB는 Binary JSON 혹은 BSON의 형태로 도큐먼트를 저장한다.
다시 말하면 MongoDB가 도큐먼트의 모음과 같이 데이터를 컬렉션(collection)에 도큐먼트로 저장한다.
컬렉션은 MongoDB에서 중요한 개념이다. 컬렉션에 있는 데이터는 디스크로 저장되고, 대부분의 쿼리에서 여러분은 찾고자 하는 컬렉션이 무엇인지 명시해야 할 것이다.
스키마가 없는 모델의 장점
-
데이터베이스가 아닌 애플리케이션이 데이터 구조를 정한다.
데이터의 구조가 빈번히 변경되는 개발 초기 단계에서 개발 속도를 단축시켜 준다. -
스키마가 없는 데이터 모델을 통해 가변적인 속성을 갖는 데이터를 표현할 수 있다.
MongoDB 애플리케이션 개발을 할 때, 필요한 데이터 필드가 무엇인지에 대해서는 걱정할 필요가 없다.
1.2.2 애드혹 쿼리 (ad hoc query)
시스템이 애드혹 쿼리(ad hoc query)를 지원한다고 할 때, 이것이 뜻하는 바는 시스템이 받아들일 수 있는 질의를 미리 정의할 필요가 없다는 것이다.
미리 정의되지 않은 쿼리, 즉 동적으로 그때 그때 만들어 쓰는 쿼리를 애드혹 쿼리라고 한다.
예)
set sqlstr = 'select * from test where id =' + @id (SQL)
db.posts.find({'tags': 'politics', 'vote_count': {'$gt':10}}); (mongoDB)
사실 모든 데이터베이스가 이러한 동적 질의를 지원하는 것은 아니다.
예를 들어, 키-값 타입의 저장 시스템은 하나의 차원, 즉 하나의 키-값으로만 질의를 할 수 있다.
다른 많은 시스템에서와 같이 키-값 저장 시스템 역시 간단하고 확장성 높은 모델을 위해 풍부한 쿼리 기능을 포기한다.
MongoDB의 설계 목표 중 하나는 관계형 데이터베이스상에서 매우 필수적인 쿼리 언어 성능을 대부분 유지하는 것이다.
위의 두 쿼리 모두 여러 개의 속성을 임의로 조합하여 질의할 수 있는 능력을 보여주고 있는데, 이러한 것이 애드혹 쿼리의 본질적은 강점이다.
1.2.3 인덱스
애드훅 쿼리의 위험 요소는 여러분이 데이터베이스를 생성할 때 여러분이 모르는 값을 찾는 것이다.
점점 더 많은 도큐먼트를 데이터베이스에 더할수록 값을 찾는 비용 역시 점점 증가할 것이며, 이는 곧 계속 확장하는 건초 더미 속에 있는 바늘과 같을 것이다.
따라서, 효과적으로 데이터를 검색하는 방법이 필요하며 인덱스가 이에 대한 해답이 될 수 있다.
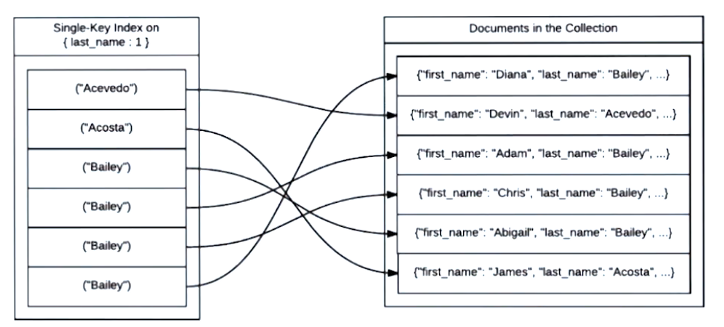
MongoDB에서 인덱스는 B-트리(b-tree, Balanced Binary search Tree)로 구현되어 있다.
Document의 필드(들) 에 index를 걸면, 데이터의 설정한 키 값을 가지고 document들을 가르키는 포인터값으로 이뤄진 B-Tree를 만든다.
B-Tree 에서 Binary Search를 통하여 쿼리 속도를 매우 빠르게 향상 시킬 수 있다.
대부분의 데이터베이스는 각 도큐먼트 또는 각 행에 기준을 위한 고유의 식별자로서 프라이머리 키를 부여한다.
프라이머리 키는 자동적으로 인덱스되어 각 기준은 유니크 키를 이용하여 효과적으로 기억되며, MongoDB 역시 이와 다르지 않다.
하지만 모든 데이터베이스가 행 또는 도큐먼트에 대한 인덱스 작업을 허용하는 것은 아니다.
이들을 세컨더리 인덱스(secondary index)라 부른다.
세컨더리 인덱스(secondary index) = 보조 인덱스
보조 인덱스의 생성시에는 데이터 페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스를 구성.
보조 인덱스의 인덱스 자체의 리프 페이지는 데이터가 아니라 데이터가 위치하는 주소값(RID)
클러스터형 보다 검색 속도는 더 느리지만 데이터의 입력/수정/삭제는 덜 느리다.
보조 인덱스는 여러 개 생성할 수 있다. 함부로 사용할 경우에는 오히려 성능을 떨어뜨릴 수 있다.
HBase와 같은 많은 NoSQL 데이터베이스는 키-값 저장소(key-value store)로 간주되는데, 이는 그 어떤 세컨더리 인덱스도 허용하지 않기 때문이다. 이는 MongoDB에서 매우 중요한 특징인데, 여러 개의 세컨더리 인덱스를 허용함으로써 MongoDB는 사용자가 넓은 범위의 쿼리를 최적화하도록 허용한다.
MongoDB에서는 한 컬렉션에 64개까지 세컨더리 인덱스를 만들 수 있다.
오름차순, 내림차순, 고유(unique), 복합 키(compound-key), 해시, 텍스트, 심지어 지리공간적 인덱스와 같이 관계 데이터베이스 시스템에서 볼 수 있는 모든 인덱스가 가능하다.
인덱스에 대해 MongoDB와 관계 데이터베이스는 같은 데이터 구조를 가지므로 어느 한쪽에서 인덱스를 관리하기 위한 권고사항은 다른 쪽에서도 적용할 수 있다.
( MongoDB 와 MySQL 둘 다 똑같은 인덱스를 적용할 수 있다는 소리인가..? MongoDB가 NoSQL 이지만 세컨더리 인덱스를 허용하기 때문에? )
1.2.4 복제
MongoDB는 복제 세트(replica set)라고 부르는 구성을 통해 데이터베이스 복제(replication) 기능을 제공한다. 복제 세트는 서버와 네트워크 장애가 발생할 경우를 대비해 중복성과 장애조치 자동화를 위해 데이터를 여러 대의 서버에 분산한다.
복제는 데이터베이스 읽기에 대한 확장을 위해서도 사용된다.
웹에서와 같은 읽기 위주의 애플리케이션에서는 데이터베이스 읽기를 복제 세트 클러스터 내의 여러 서버에 분산할 수 있다.
복제 세트는 많은 MongoDB 서버로 구성되어 있는데, 보통 각각의 MongoDB 서버는 분리된 물리 장비에 별도로 존재하며, 이를 노드(Node)라 부른다.
어느 순간이든지 하나의 노드는 복제 세트의 프라이머리 노드(primary node)로 존재하며, 더불어 하나 또는 그 이상의 세컨더리 노드가 존재한다. 다른 데이터베이스에서 제공하므로 익숙할 수도 있는 마스터-슬레이브에서와 같이 복제 세트의 프라이머리 노드에 대해서는 읽기와 쓰기가 모두 가능하지만, 세컨더리 노드는 읽기만 가능하다.
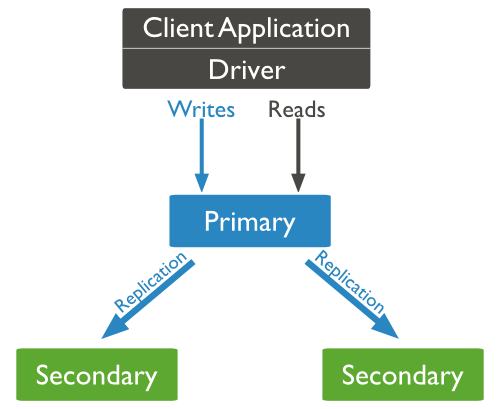
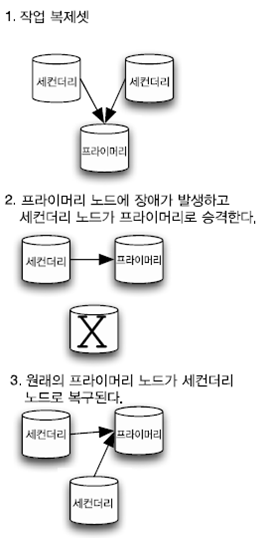
복제 세트의 고유한 기능은 자동 장애조치를 지원한다는 점이다. 만일 프라이머리 노드에 장애가 발생하면 클러스터는 자동으로 세컨더리 가운데 하나를 선택해서 프라이머리로 설정한다. 이전의 프라이머리 노드가 복구되면 세컨더리 노드로 작동한다.
1.2.5 속도와 내구성
쓰기 속도는 미리 정해진 시간 내에 데이터베이스가 얼마나 많은 수의 삽입, 수정, 삭제 명령을 처리할 수 있는가를 뜻한다.
내구성(durability)은 이 쓰기 연산이 디스크에 제대로 이루어졌다는 것을 확신할 수 있는 정도를 뜻한다.
데이터베이스를 설계할 때 속도와 내구성 사이에서 최적의 균형을 이루기 위해 포기할 것은 과감하게 포기해야 한다.
MongoDB의 경우에는 쓰기 시맨틱스(Write semantics)와 저널링(journaling)을 통해 속도와 내구성 사이에서 타협을 이룰 수 있다.
쓰기 시맨틱스(Write semantics)
(이거 뭔지..? 구글링 해도 정확하게 안나옴..쓰기 의미론..?)
저널링(journaling)
스토리지에 데이터를 저장하기 전에 Journal 영역에 데이터의 변경 이력을 저장하고, 스토리지에 데이터 변경 내역을 저장하는 활동을 의미한다.
저널링은 MongoDB v2.0에서 기본적으로 활성화되어 있다. 2012년 11월 이후에 배포된 MongoDB 드라이버에서는 비록 설정이 필요하긴 하지만, 사용자에게 응답을 주기 전에 쓰기를 램에 안전하게 쓰는 것을 보장해준다.
MongoDB를 명령하고 잊기(fire-and-forgot)모드로 설정하면 확인을 기다릴 필요 없이 서버에 write 작업을 전송할 수 있다. 또한 commit이 되었는지 확인하기 전에 다수의 복제 서버들에 대한 write를 보장하도록 설정할 수도 있다.
단위데이터는 작지만 양은 방대한 데이터(clickstream이나 log와 같이)에 대해서는 fire-and-forgot 타입의 write가 적합하고, 중요한 데이터의 경우 안전모드 설정을 권장한다.
1.2.6 확장
일반적으로 애플리케이션이 하나의 데이터베이스 노드만을 가질 때, 일반적인 경우는 디스크나 메모리 혹은 CPU를 추가해서 데이터베이스 병목 현상을 완화시킬 수 있으며 이를 수직적 확장 이라고 합니다.(vertical scalling)
그와 반대로 수평적 확장은 하나의 노드를 업그레이드 하는 것이 아닌, 데이터베이스를 여러 대의 서버에 분산시키는 것을 의미 합니다.(scaling horizontally)
수평적 확장 구조는 기존의 하드웨어를 재 사용할 수도 있으므로 비용이 절감 할 수 있으며, 시스템 장애가 발생해도 분산된 서버로 인해 장애에 따른 피해가 감소 하게 됩니다.
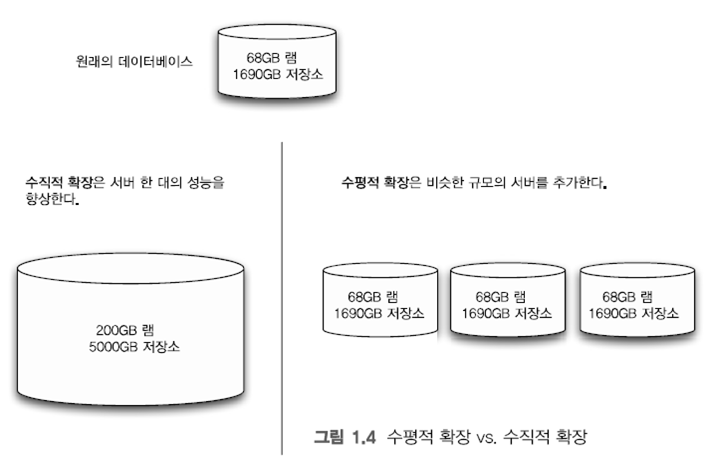
몽고DB는 수평적 확장이 용이하도록 설계되어 있습니다
샤딩(sharding)으로 알려진 번위 기반(range-based) 파티션 메커니즘을 통해 데이터를 여러 노드에 걸쳐 분산하는 것을 자동으로 관리해줍니다.
샤딩 시스템은 샤드 노드를 추가해서 용량을 필요한 만큼 늘리고 자동 장애조치 기능도 제공합니다.
각각의 샤드는 최소한 두 개의 노드로 구성된 복제 세트로 이루어져 있으며 어느 한 노드에서 장애가 발생 발생 하게 되면 자동으로 복구되도록 보장 합니다.
애플리케이션에서는 하나의 노드에 연결된 것처럼 샤드 클러스터에 연결을 하면 됩니다.
1.4 MongoDB를 사용하는 이유
- 용도관점 : 웹 애플리케이션 분석과 로깅 애플리케이셔 중간 정도의 캐시를 필요로 하는 애플리케이션에서 일차 데이터저장 시스템에 적합
- 스키마가 존재하지 않는 데이터를 저장하기에 용이하여 미리 구조가 알려지지 않은 데이터를 저장하는데 유용
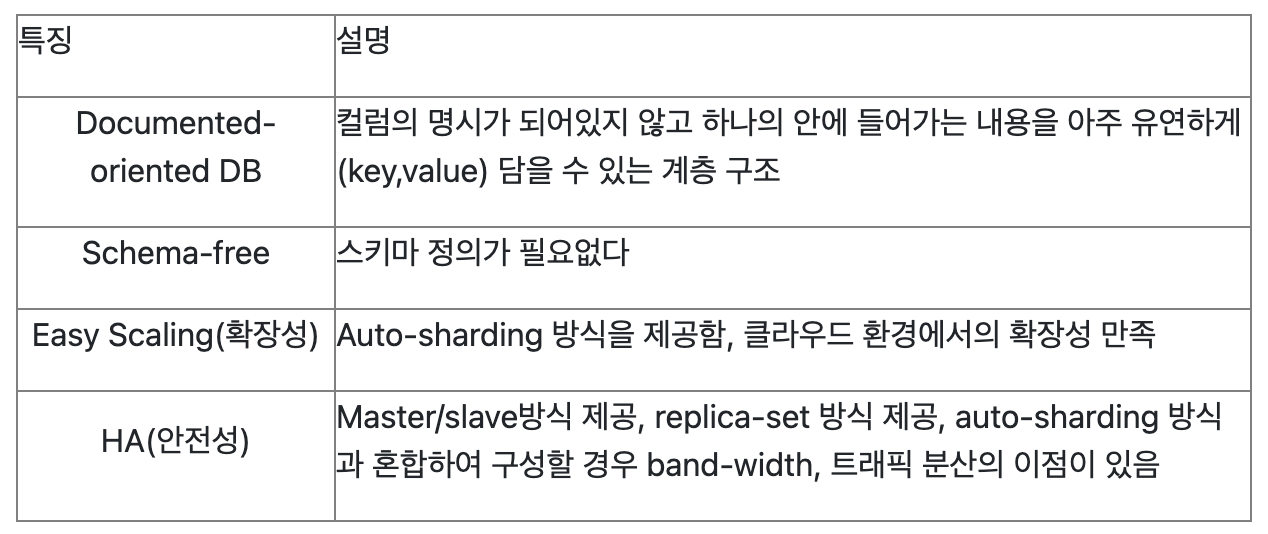
MongoDB 특징
MongoDB와 다른 데이터베이스 비교
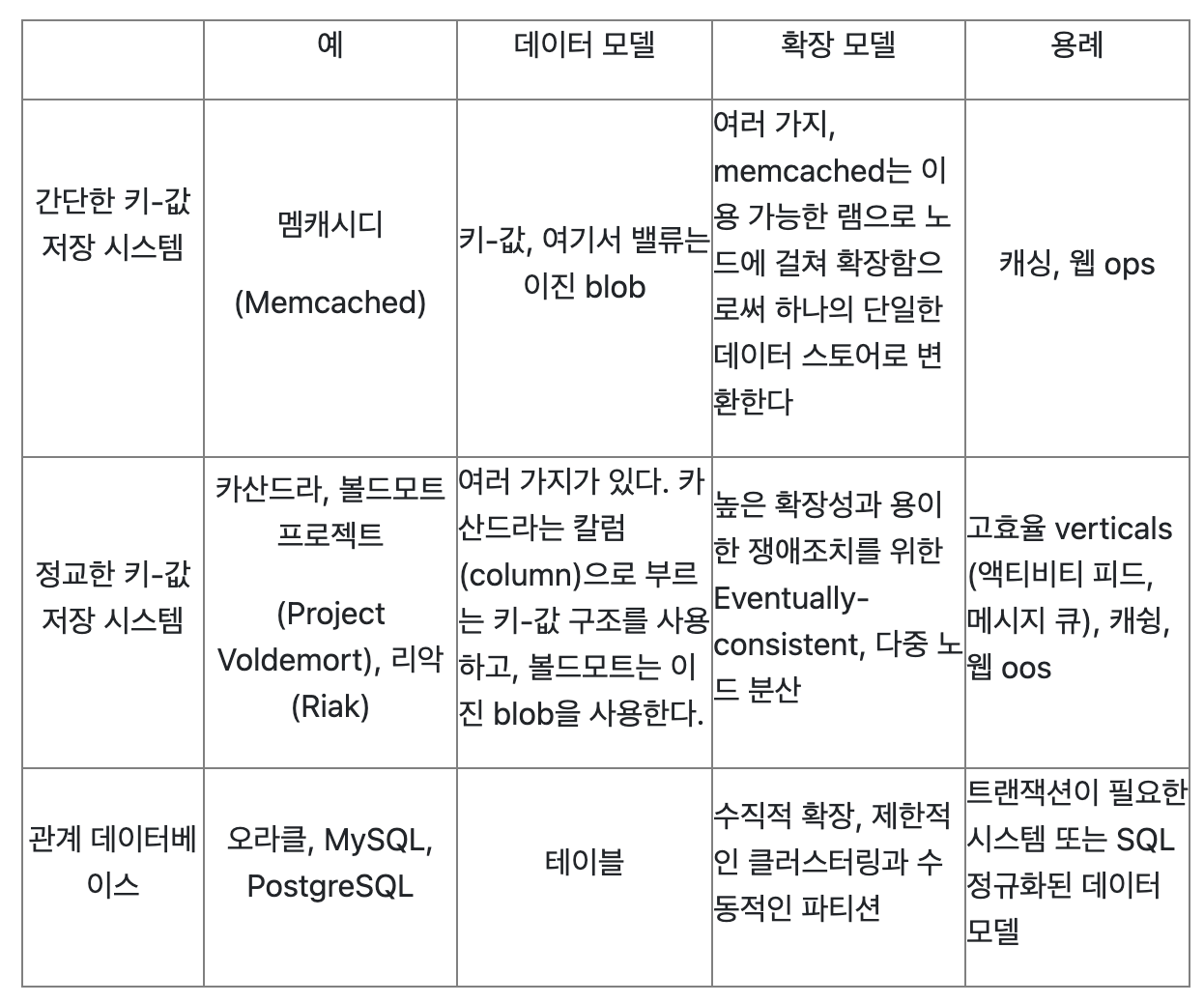
사용 예

( 우리는 애자일 개발 및 앱/웹 애플리케이션에 포함되는건가..? )
한계
- 보통 64 비트 시스템에서 실행 되어야 함
- 필요할 경우 메모리 자동 할당 : 공유 환경에서 실행이 어려움
- 데이터 구조가 데이터 크기 관점에서는 그렇게 효율적이지 않음
- 쿼리가 SQL 만큼 친숙하거나 쉽지않다..(극공감..)
- 복제와 저널링을 사용 : 셧다운 시 데이터가 손상 될 수 있음, 장애 조치를 위해 복제된 백업 서버를 가지고 있어야 함
1.8 요약
MongoDB는 오픈 소스, 도큐먼트 기반 데이터베이스 관리 시스템이다.
오늘날의 인터넷 애플리케이션에서 필요한 데이터와 확장을 위해 설계된 MongoDB는 동적 쿼리 언어와 세컨더리 인덱스가 특징이다. 그 외에도 빠른 원자적 업데이트와 복잡한 집계, 자동 장애조치와 복제, 수평적 확장을 위한 샤딩 등이 있다.
샤딩 개념이 복제랑 헷갈리는 건.. 나뿐인가?
-
기존 복제 시나리오에서 기본 노드는 대량의 쓰기 작업을 처리하는 반면 보조 서버는 읽기 전용 작업 또는 데이터 세트의 백업 유지로 제한된다. 그러나 샤딩은 복제본 세트가 있는 샤드를 활용하므로 모든 쿼리가 클러스터의 모든 노드에 분산된다. (즉..쓰기도 master 말고 slave 서버에도 이뤄진다는 말인가? )
-
각 샤드는 전체 데이터 세트의 하위 집합으로 구성되므로 샤드를 추가하기 만하면 복잡한 하드웨어 재구성을 수행할 필요 없이 클러스터의 스토리지 용량이 늘어난다.
-
복제에는 대규모 데이터 세트를 처리할 때 수직 확장이 필요합니다. 이러한 요구 사항은 수평 적 확장 방식에 비해 하드웨어 제한과 엄청난 비용으로 이어질 수 있다. 그러나 MongoDB는 수평 확장을 사용하기 때문에 워크로드가 분산된다. 필요한 경우 추가 서버를 클러스터에 추가할 수 있다.
-
샤딩에서 읽기 및 쓰기 성능은 클러스터의 서버 노드 수와 직접적으로 관련된다. 이 프로세스는 단순히 노드를 추가하여 클러스터의 성능을 향상하는 빠른 방법을 제공한다.
-
샤딩 된 클러스터는 단일 또는 여러 샤드를 사용할 수 없는 경우에도 계속 작동할 수 있다. 이러한 샤드의 데이터는 사용할 수 없지만 클라이언트 애플리케이션은 다운 타임 없이 클러스터 내에서 사용 가능한 다른 모든 샤드에 계속 액세스 할 수 있다. 프로덕션 환경에서는 모든 개별 샤드가 복제본 세트로 배포되어 클러스터의 가용성이 더욱 향상된다. (서버는 죽어도 클러스터는 계속 클라이언트에서 엑세스 할 수 있다는 말인가..?)
즉, 복제는 master만 쓰기가 가능하고 샤딩 처리가 되면 master, slave 가 다 쓰기가 가능하다? 로 이해하면 되나..?
