LightNorm: Area and Energy-Efficient Batch Normalization Hardware for On-Device DNN Training
IV. LightNorm: Low-precision Blocked Range Norm
A. Low-Precision Batch Normalization
1) Floating Point Format
- Table 1은 Data format과 sign bit, mantissa bits, expoent bits의 분배에 따른 dynamic range, representation range를 나타낸 표이다.
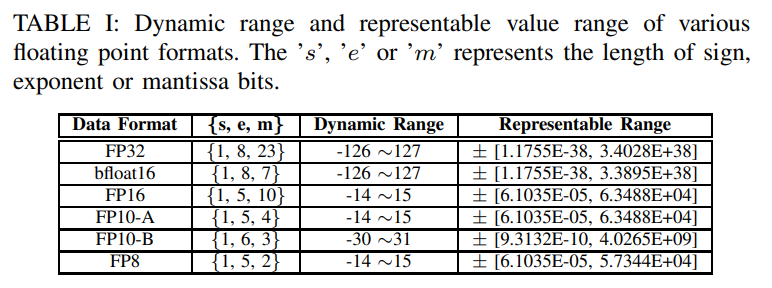
-
Precision(representation range)는 dynamic range보다 덜 중요하다. 따라서 FP10-A, FP8은 dynamic range가 너무 작으므로 어느정도 precision이 보장되는 FP10을 써야 한다.
-
Fig. 2를 보면 FP10이 가장 효율적이다.
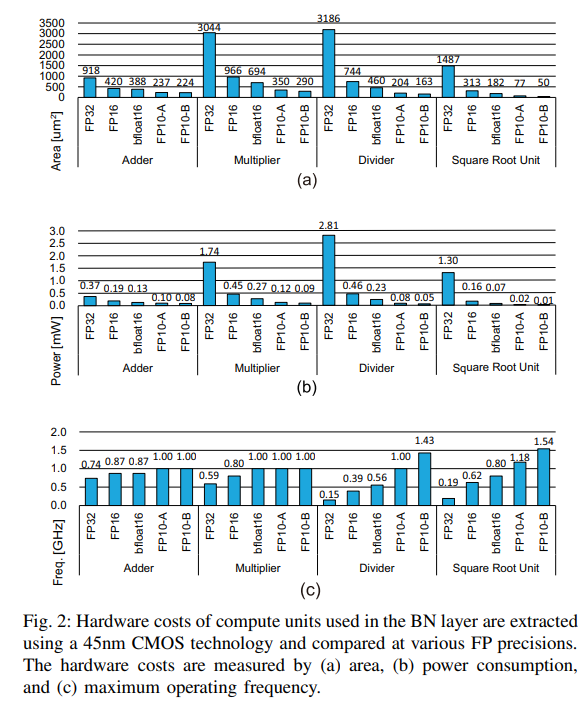
결론: FP10 중 고를 것임
2) Proper Length of Exponent Bits
- Representation range를 벗어나는 값은 0이 되며, 이는 현저한 정확도 감소를 일으킨다.
- 따라서 적절한 범위설정이 중요하다.
- Fig. 4는 feature maps(activations)와 gradient의 범위를 나타내었다. (ResNet-50에 CIFAR-100을 학습시켰을 때)
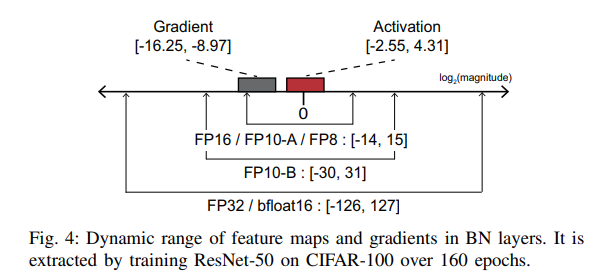
- Gradient 범위를 커버하려면 6-bit 이상의 exponent bits가 필요하다. (FP32, bfloat16, and FP10-B) (결론: 이 중 고를 것임)
3) Proper Length of Mantissa Bits
- Accumulation은 기댓값과 표준편차를 계산하는 데에 중요한 연산이다.
- Floating point 덧셈 시 지수부가 큰 수를 먼저 가려내고, 지수부가 작은 수를 두 수의 지수부 차이만큼 오른쪽으로 shift 하여 자릿수를 맞춰야 한다. 이때 shift하는 자릿수보다 mantissa bit 수가 작으면 zero setting error(ZSE)가 발생한다.
- ZSE를 피하기 위해 mantissa bits 길이를 적절히 지정해야 한다.
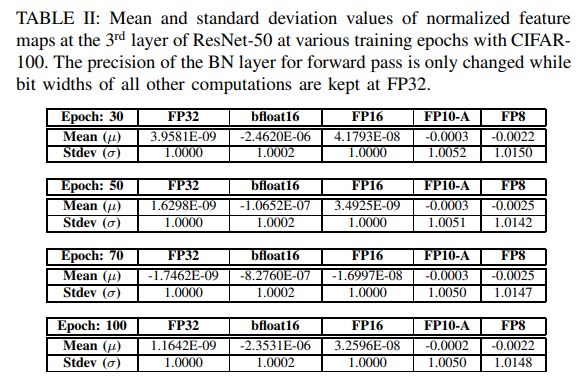
- Table 2는 epoch에 따른 mean과 SD값을 나타낸 표이다.
- Mantissa bit가 2-bit인 FP8은 왜곡이 심하지만 2비트를 더 쓰는 FP10-A만 해도 오류가 훨씬 덜 하다.
4) Principle Behind Selection of BN Precision For DNN Training
- FW는 mantissa bits 길이가, BW는 exponent bits 길이가 중요하다.

- Fig. 5를 보면 (FW/BW)가 (FP32/FP32)인 경우를 baseline으로 두고 비교하였을 때, FW의 m bits 길이 변동과 BW의 e bits 길이 변동이 정확도에 영향을 미치고 있음을 알 수 있다.
B. Blocked Range Normalization
1) Utilizing Range Normalization
-
BN(Batch Normalization)에 비해 RN(Range Normalization)이 얻는 두 가지 장점이 있다.
-
첫 번째는 32.7%의 energy saving 효과이다.
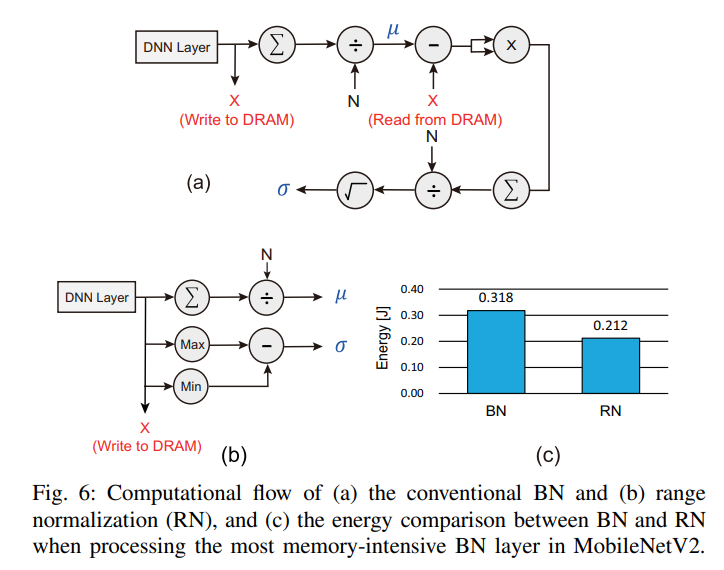
-
Fig. 6은 BN과 RN의 계산 순서이다. BN은 기댓값을 얻기 위해 feature map 전체를 DRAM에 불러와야 하지만, RN은 feature map의 최댓값과 최솟값만을 monitoring하면 된다.
-
두 번째 장점은 square, root 계산을 하지 않는 것이다. 이 두 연산은 넓은 dynamic range가 필요하고, ZSEs를 유발한다. 따라서 높은 FP 정확도를 요구하게 되지만 RN은 FP 정확도가 상대적으로 덜 요구된다.
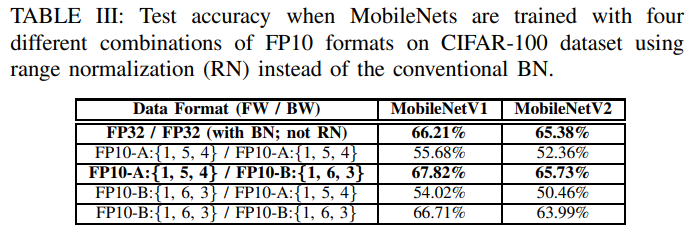
-
Table 3은 BN을 사용하여 (FW/BW)가 (FP32/FP32)일 때를 baseline으로, RN을 사용하여 FP10-A, FP10-b를 FW, BW에 사용한 4가지 경우의 정확도를 비교한 표이다.
-
(FP10-A/FP10-B)일 때의 정확도가 baseline에 비해 높게 나타났다.
-
남은 논문에서는 이 조합을 사용한다.
2) Exponent Sharing (Block Floating Point)
- Exponent를 공유하는 block을 형성하기 위해 숫자들을 모은다.
- 이것은 DRAM을 거치는 데이터 크기를 줄일 수 있다.
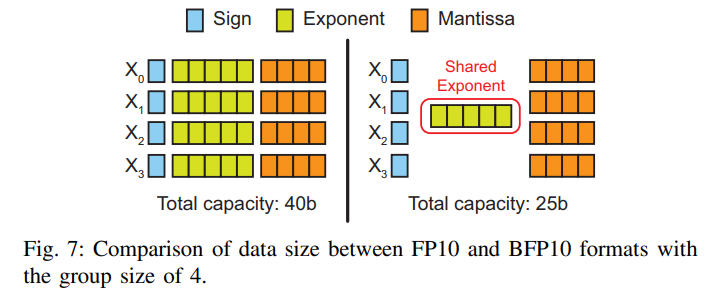
- Fig. 7을 보면 exponent sharing을 하지 않았을 때보다 했을 때 데이터 크기가 37.5% 감소하였음을 알 수 있다.
- 다만 group size가 너무 커지면 ZSEs가 발생할 수 있다. (sharing exponent는 그룹의 maximum exponent임을 유의하여)
- 따라서 학습 정확도를 해치지 않는 선에서 group size를 지정해야 한다.
C. Training Accuracy with LightNorm
- Pytorch framework에서 BN layers를 LightNorm layers로 바꾸고, 4가지의 CNN benchmarks에 대하여 group size를 달리하여 정확도를 측정했다.
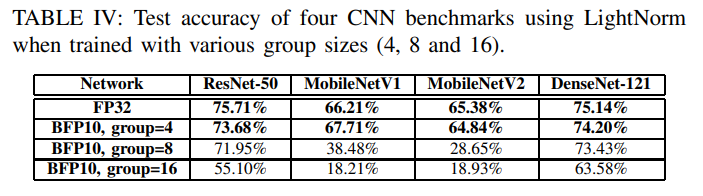
- Table 4를 보면 FP32를 사용한 baseline에 비해 group size가 4일 때가 가장 근접한 정확도를 보였으며 평균적으로 0.5% 밖에 떨어지지 않았다.
- 따라서 앞으로의 섹션에서는 BFP10(FW:{1,5,4}, BW:{1,6,3}), group size 4로 LightNorm hardware를 설계하였다.
V. DNN Training Accelerator with LightNorm
A. LightNorm Hardware
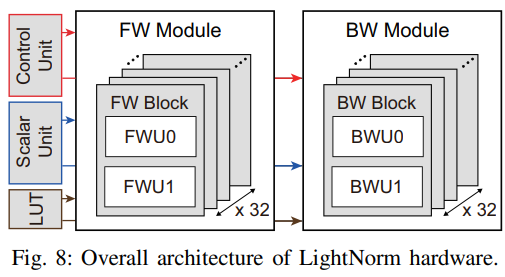
1) Forward Pass Module (LightNorm-FW)
- FP10-A 포맷을 사용한다.
- 32 FW blocks가 있다. 이것은 32 output channel에서 BN을 병렬 실행하기 위함이다.
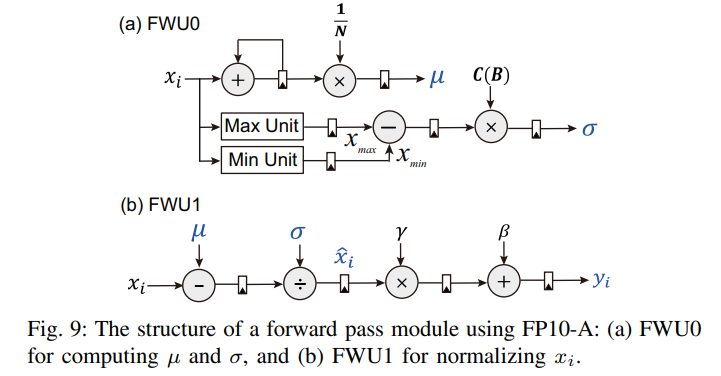
- Fig. 9와 같이 각 FW block은 FWU0, FW01로 구성되어 있다.
- FWU0은 mean과 SD를 계산하고 FWU1은 normalization을 수행한다.
- 이 두 유닛이 매 clock마다 pipeline으로 동작한다.
2) Backward Pass Module (LightNorm-BW)
- FP10-B 포맷을 사용한다.
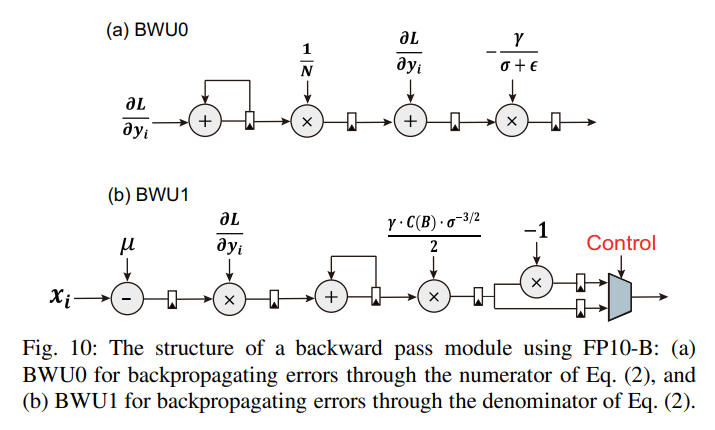
- Fig. 10과 같이 BWU0, BWU1로 구성되어 있다.
- 각 유닛은 local gradient를 계산한다.
- 자세히 이해 못해서 추후 보강
B. Evaluation of LightNorm Hardware
1) Methodology and Baselines
- Methodology: RTL(Register Transfer Level), 150MHz, Synopsys Design Compiler using 45nm
- Baselines: 2가지임. Conventional BN and reconstructed BN with FP32 compute unit, 다른건 모두 동일.
- Benchmarks: ResNet-50, MobileNetV1, MobileNetV2, DenseNet-121
- Dataset: CIFAR-100
2) Area and Power Consumption
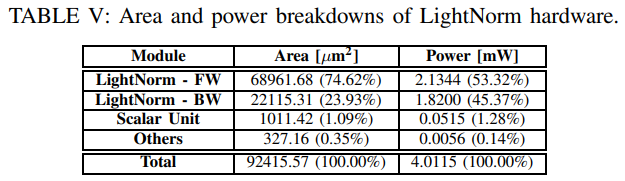
- Table 5는 LightNorm hardware의 면적과 전력 분석표이다.
- Fig. 8에 포함된 모든 모듈의 면적과 전력소비를 나타내었다.
- 'Others' 는 LUT와 control unit이다.
- Conventional BN: 1.44mm^2, 59.61mW
- Reconstructured BN: 1.54mm^2, 63.53mW
- LightNorm (FP10-A/FP10-B): 0.09mm^2, 4.01mW, (-> BN 평균에 비해 면적은 16.2배, 전력소모는 15.4배 감소함. reduced precision, range BN, exponent sharing 덕분)
- LightNorm with FP32: 0.99mm^2, 37.04mW (-> 동일한 정확도에서도 1.5배의 면적과 1.7배의 전력 소모가 감소됨. range BN 덕분)
3) Cycle Estimation
- Fig. 11은 BN layer의 clock cycle을 보여준다.
- Batch size는 256
- FW에서 recontructured BN은 conv BN에 비해 clock cycle이 33.3% 감소했다. mean과 SD가 순차적으로 처리되는 conv BN과 다르게 rec BN은 병렬처리 되기 때문.
- BW에서는 conv, rec BN이 동일하게 처리되기 때문에 clock cycle 차이가 거의 없었다.
- 모든 benchmarks에서 LightNorm은 conv BN의 평균에 비해 FW는 1.5배, BW는 2배의 clock cycle 감소를 보였다. (eq5, eq9를 비교하면 이유를 알 수 있음)
4) Energy Analysis
- 1 epoch당 소모하는 에너지
- Conv BN: 14.8mJ
- Rec BN: 12.4mJ (rec BN은 conv BN보다 전력소모는 크지만 에너지 소비는 작다, FW의 clock cycle이 작기 때문)
- LightNorm with FP32: conv BN에 비해 2.8배, rec BN에 비해 2.4배의 에너지 소모가 감소되었다.
- LightNorm with FP10: 에너지 소모는 0.6mJ로 cBN에 비해 23.5배, rBN에 비해 19.6배 감소했다.
C. Training Accelerator with LightNorm
1) Methodology
- Training accelerator는 data buffers, systolic array, LightNorm H/W with BFP converters로 구성되어있다.
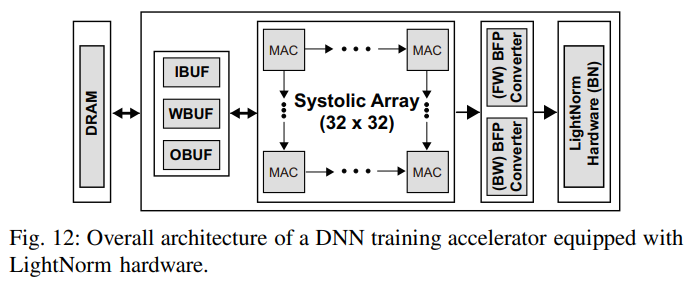
- A system level analysis를 진행하기 위해서 DRAM, SRAM 접근도 고려했다. DRAM은 16Gb LPDDR3, SRAM은 CACTI-6.0을 사용하였다.

- On-chip buffers는 precision level에 따라 다른 크기로 선택했다. Table 6에 나타내었다. Systolic array를 최대한 다 활용할 수 있도록 DRAM 접근 지연을 상쇄할 수 있는 버퍼 사이즈로 선택했다.
- Systolic array에서 잡아먹는 clock cycle을 추정하기 위해 Scale-Sim이라는 open-source cycle-level simulator를 사용했다. (사용하는 SRAM과 DRAM configurations를 고려하여 선정.)
- LightNorm hardware에서 소모하는 clock cycle은 ImageNet-scale images로 가정한 RTL simulation으로 측정했다.
- 모든 RTLs는 Synopsys Design Compiler에서 150MHz로 합성했고, 45nm CMOS 공정을 이용했다.
2) Hardware Configurations
- 면적과 전력 비교를 위해 다양한 hardware configurations를 가져왔다.
- Systolic array(SA)의 bit-precision도 그 중 하나.
- SA는 Conv/FC layer를 처리하고 32x32의 MAC units를 가진다.
- 각 MAC unit의 multiplier의 정확도는 변할 수 있다.
- 정확도를 유지하기 위해 여기서는 FP32 adder를 썼다.
- 다른 hardware configurations로는 BN layer과 이것의 precision level이 있다. (LightNorm에서는 BFP10) Table 6에서 HW1~3은 높은 성능을 위해 FP32를, HW4~6은 에너지 효율성을 위해 bfloat16을 사용했다.
- Fig. 12의 BFP converter는 HW4~6에서 FP32 outputs를 bfloat16으로 바꾸기 위해 사용되었다.
- HW7은 이 논문에서 제안한 것이다. LightNorm hardware에 low-precision systolic array를 사용했다.(* BFP10은 LightNorm의 BN layer에서 사용되며, BFP converter는 outputs를 FP10으로 변환하기 위해 사용된다.
3) Area Analysis
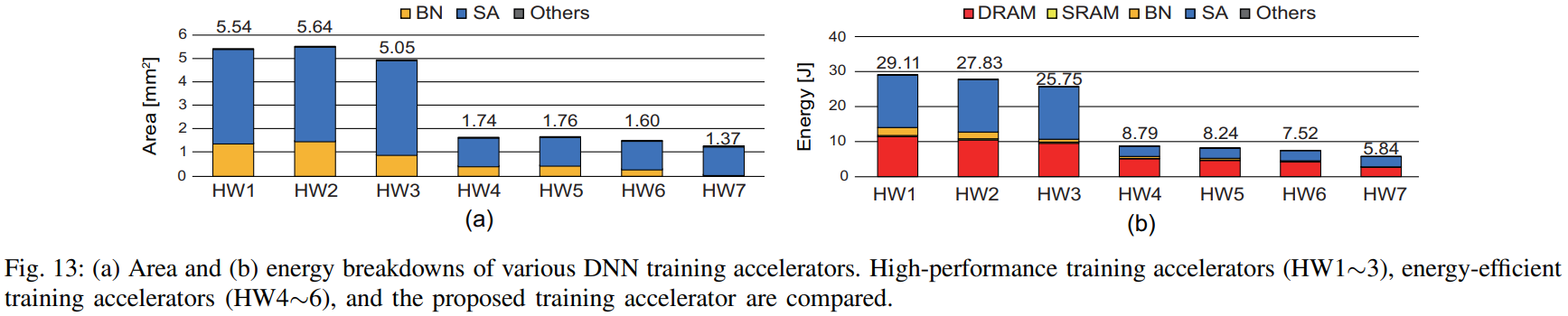
- HW1~3: FP32 MAC units, FP32 BN modules
- 많은 면적을 차지한다.
- HW1: 동일한 BN을 사용하는 HW4보다 3.2배 더 큼.
- HW1~3 모두 동일 precision level을 사용하지만 BN 종류가 달라 면적도 다르다. 예시로 RN을 사용하는 HW3은 rec BN을 쓰는 HW2보다 10.4% 작다.
- HW4~6: SA, BN 모두 lower precision 사용.
- HW1~3보다 68.6% 작은 면적 차지
- BN layers는 아직 FP32를 사용하고 있어서 이 부분에서 면적 감소는 작다.
- HW7: Low-precision SA, LightNorm 사용.
- 가장 작은 면적 차지. HW1~3보다 4배, HW4~6보다 1.2배의 면적이 감소했다.
4) Energy Analysis
- 에너지 소모량은 1 epoch당 분석했다.
- HW1~3: RN 기반의 HW3이 가장 나은 에너지 효율성을 보였다.(HW1보다 11.6% 개선)
- HW4~6: HW1~3의 평균보다 3.4배 개선되었다. (SA, BN 둘다 low-precision multiplier 사용, 데이터 접근 에너지 감축으로 인해)
-HW7: 다른 하드웨어에 비해 1.3배~5배 에너지가 감소하여 최소 에너지 소모량을 보였다. HW1~3에 비해 78.8%, HW4~6에 비해 28.6%의 에너지를 절약했다. BN 처리와 메모리 접근 에너지를 모두 최소화한 LightNorm의 효과이다.
VI. Conclusion
- LightNorm은 memory- and energy-efficient한 BN 처리를 보인다.
- 이 두 가지를 위해 세 개의 approximation techniques를 융합했다.(low bit-precision, range batch normalization, and block floating point)
- 이것들은 BN layers의 complexity를 줄이고 DNN training accuracy 감소 없이 hardware efficiency를 개선하기 위해 선택되었다.
- Hardware efficiency를 증명하기 위해 customized LightNorm hardware를 설계했고 기존의 BN hardware design과 비교했다.
- 마지막으로 LightNorm hardware를 실제 DNN accelerator과 합쳐 검증함으로써, 다양한 DNN training accelerators의 configurations에 대해 1.3~5.0배의 energy-efficiency 개선을 하였다.
