Simple Baselines for Human Pose Estimation and Tracking 논문 정리
이상하게 내 기존 테마로는 2020년 이후의 글이 제대로 업로드가 되지 않아서 시형오빠꺼 블로그 테마를 훔쳐왔다. 그런데 저번주에 맥북 수리 맡기면서 simple baseline 정리해놓은게 사라져 버렸다..^^ 커밋해뒀었는데 레파지토리도 지워버리고 새걸로 올려버리고 icloud에도 예전 버전으로 올라가 버려서 다시 써야 한다 ,,, 이거 진짜 엄청 열심히 썼었는데 .. .
충 격 실 화
앞으로는 클라우드 서비스를 절 대 로 믿지 않을 것 ... . .
1. Introduction
최근(2018)에 pose estimation이나 pose tracking 분야에서 굉장히 논문들도 많이 나오고 성능도 좋은 모델들도 많이 나오는 추세이다. 그런데 이런 모델들은 complexity도 너무 크고 알고리즘도 너무 복잡해서, 알고리즘을 분석하기도 어렵고 각 모델의 성능을 비교하는 것도 어렵다고 한다. 너무나도 다른 구조를 가지고 있으면 비교할 수 있는게 최종 성능밖에 없으니 말이다.
그래서 이 논문에서는 pose estimation이나 pose tracking 분야에서 사용할 수 있는, 성능은 기존의 SOTA보다 비슷하거나 더 좋으면서, 매우 간단하고 효과적인 baseline method를 제안한다.
딥러닝의 도입 이후, 다른 컴퓨터 비전 분야와 마찬가지로 pose estimation 분야 역시 상당히 많이 발전되었고, 특히 요즘에는 뒷배경이 복잡해도 여러 사람들을 동시에 detect하고 tracking할 수 있는 모델을 연구하는 방향으로 많이 진행된다고 한다.
그런데, 이렇게 task가 점점 복잡해지다 보니 네트워크의 아키텍쳐 역시 점점 복잡해지고 커지고 있다. 예를 들어서 MPII benckmark나 COCO benchmark에서 좋은 성능을 거두고 있는 모델들을 보면 다 accuracy는 비슷비슷한데 네트워크는 너무 달라서 네트워크의 어떤 부분이 최종 성능에 얼마나 영향을 미치는지도 파악하기 힘들다.
Pose tracking의 경우에는 pose estimation보다 더 어려운 task이기 때문에, 아직 많이 연구는 되지 않았지만 앞으로 나오는 네트워크들이 더 복잡해지면 해졌지 더 간단해지지는 않을 것이다..
이런 한계를 극복하기 위해서 이 논문에서는 최종 목표를 완전히 비튼다. 다른 논문들이 "네트워크 구조를 어떻게 바꾸고 어떤 모듈을 추가해서 성능을 얼마나 올렸다" 에 주 목적을 둔다면, 이 논문에서는 "간단한 이 네트워크의 성능이 얼마나 좋아질 수 있게?" 를 주 연구 방향으로 둔다.
2. Simple Baselines for Human Pose Estimation and Tracking
이 논문에서 제안하는 simple method의 방향은 2개이다. 기존의 네트워크 아키텍쳐와 비교했을 때 엄청나게 간단한 네트워크와 이 네트워크를 이용해 사람을 tracking하는 알고리즘 두 가지를 제시한다.

왼쪽에 있는 두 가지의 네트워크는 COCO benchmark와 MPII benchmark에서 좋은 성능을 거두고 있는 네트워크 CPN과 hourglass 이다. 그리고 오른쪽에 있는 (c)가 여기에서 제안하는 simple baseline이다. 사실 딱 봐도 오른쪽에 있는 (c)가 훨씬 더 가볍고 간단해 보이기는 한다.
1) Using a Deconvolution Head Network
여기에서는 backbone으로 ResNet을 사용한다. 그리고 마지막으로 나온 convolution feature map에서 몇개의 deconvolution layer를 붙인다. 여기에서 deconvolution layer를 쓰는 이유는 기존의 연구에서 강조해왔던 high resolution을 가지고 rich semantic information을 가지고 있는 feature map을 뽑기 위해서이다.
- deconvolution layer 특징
- 각 layer 뒤에
batch norm - 각 layer 뒤에
ReLu - 256 filter + 4x4 kernel + stride 2
- 제일 마지막에는 k key point에 대해서 heat map을 뽑기 위해서 1x1 convolution 붙임
- predicted heatmap과 targeted heatmap(joint 기준으로 가우시안 분포) 간의 loss를 구하기 위해서 MSE 사용
- 각 layer 뒤에
위에 있는 기존의 네트워크(CPN, hourglass)들과 비교해보면 가장 큰 차이는 high resolution feature map을 생성해내는 과정이다. 이전의 포스팅에 정리해뒀지만 CPN의 경우에는 U 모양의 아키텍쳐를 도입해 낮은 resolution의 feature map과 높은 resolution의 feature map 사이의 장점을 합치는 네트워크를 제안했고, hourglass의 경우에는 bottom-up processing과 top-down processing 작업을 하는 모듈 여러개를 쌓아 refine된 feature map을 얻어냈다. (각 모듈이 하는 일은 CPN이랑 비슷하다.. 약간 U 모양으로 connection 이루어져 있음)
하지만 simple baseline network는 기존의 모델과는 다르게 backbone에서 나온 feature map을 deconvolution layer을 이용해서 upsampling한다. 그래도 성능은 비슷하게 좋다.
그래서 이 논문에서 내린 최종 결론은 물론 좋은 high resolution feature map을 얻는것은 매우 중요하지만, 그 방법은 달라도 상관없고, 어떤 방법을 사용하던 크게 성능에 영향을 주지는 않는다는 것이다.
2) Pose Tracking Based on Optical Flow

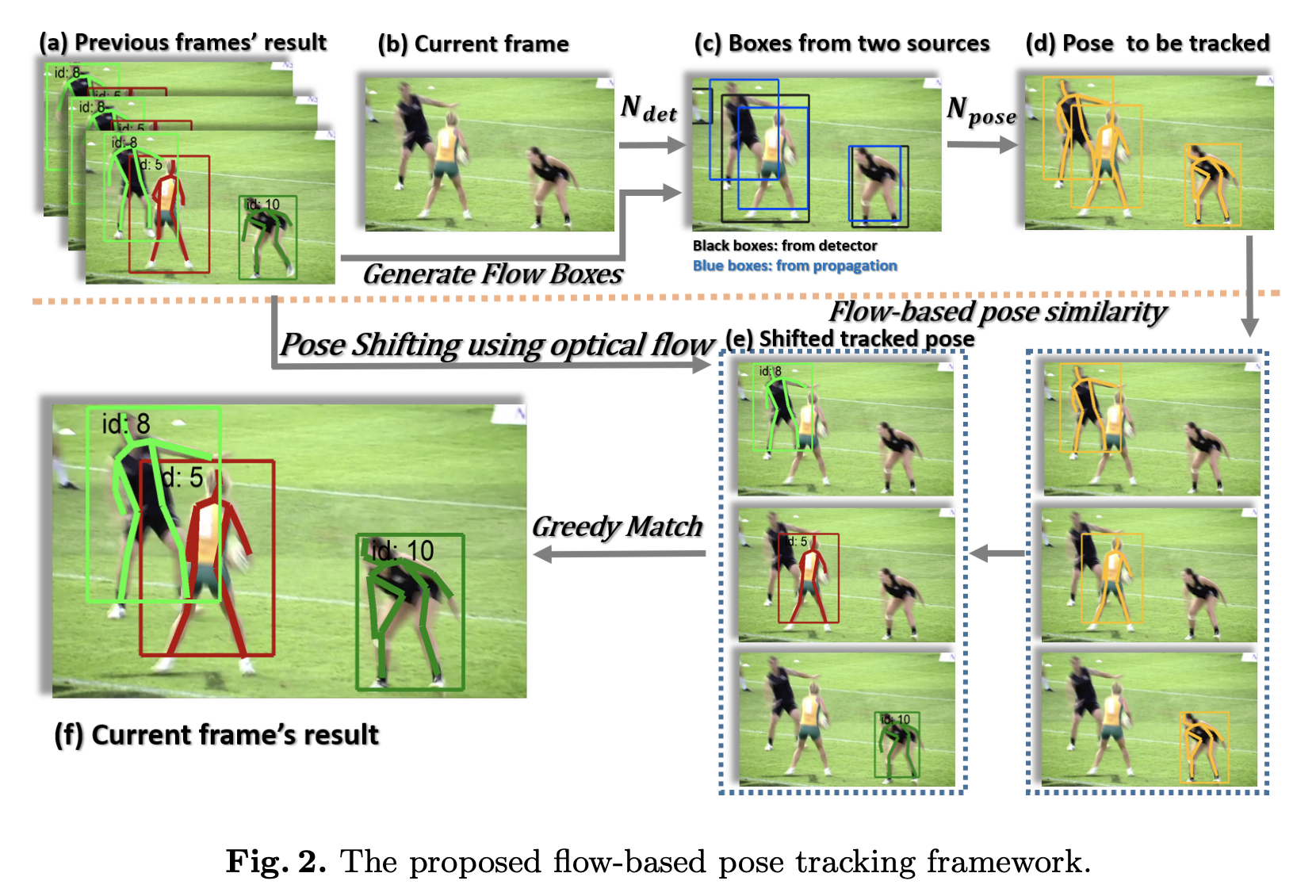
상단의 사진은 tracking을 할 때 이 simple baseline에서 사용하는 알고리즘을 그려놓은 것이다. 이 논문에서는 greedy 기반으로 joint들을 매칭한다.
여기에서는 선행연구인 detect-and-track에서 사용했던 tracking 알고리즘을 약간 수정하고 사용한다.
- 단순히 한 종류의 human box만을 사용하는 것이 아니라 human detector에서 나온 box와 이전 frame에서 optical flow를 통해 생성된 box를 모두 합쳐서 얘네를 기반으로 tracking을 진행한다.
- greedy matching할 때 사용하는 similarity metric을 변경했다.
단순히 매 프레임 사람들을 detect하고 연결하는 방식으로는 tracking을 원만하게 하기 힘든 경우가 있다. object들이 겹쳐서 일시적으로 특정한 사람이 보이지 않는 경우라던지, 빠르게 피사체가 이동해 흐릿하게 나온다던지, 하는 경우에는 detector가 사람을 잘 탐지하지 못할 수 있다.
이런 경우를 해결하기 위해서 temporal information을 사용하는 것이 tracking 성능을 많이 상승시킬 수 있다.
(1) Joint Propagation using Optical Flow
그래서 temporal 정보를 이용해 human box를 만들어 내기 위해서 joint propagation을 이용한다. 만약에 주어진 특정 프레임 과 그 프레임의 joint set , optical flow 가 있을 때 optical flow를 이용해서 프레임 의 joint set 을 추정할 수 있다.
그러면 해당 프레임에서 detector를 이용해 찾아낸 joint들과, optical flow를 이용해 propagate한 joint들을 합쳐서 사용할 수 있다. 이런식으로 candidate joint set을 설정하면 흐릿하게 나온 피사체나 겹쳐있는 피사체들도 상대적으로 잘 찾아내는 네트워크를 구성할 수 있다. (아래 알고리즘에서 나오지만 중복되는 joint가 나올 수 있으니까 Non-Maximum Suppression을 사용해서 중복되는 joint를 합친다.)
(2) Flow-based Pose Similarity
지금까지는 bounding box의 IoU(Intersection over Union)를 similarity metric으로 사용해왔다. 하지만 이런 metric은 피사체가 빨라서 box 간의 오버랩이 생기지 않는다던가, 너무 사람이 붐벼있는 영상에서는 제대로 사용할 수 없다는 한계가 있었다.
이러한 문제를 해결한 또 다른 metric이 OKS(Object Keypoint Similarity)였는데, 얘도 피사체의 포즈가 갑자기 확 바뀔 때는 문제가 될 수 있고, 앞서 제인한 optical flow에 기반한 joint를 충분히 반영하지 못한다는 한계가 있었다. 그래서 이 논문에서는 이러한 한계를 극복하기 위해서 flow-based pose similarity metric을 제안한다.
특정 frame 의 한 instance 와 다른 frame 의 한 instance 의 similarity는 다음과 같이 계산된다.
추가적으로 optical flow based로 계산할 때는 바로 이전 프레임만 보는게 아니라 여러 장의 frame을 보면서 확인한다고 한다. 그래서 예전에 나왔었던 object라고 해도 오래 전의 프레임도 같이 저장해서 보기 때문에 같은 object임을 확인할 수 있다.
(3) Flow-based Pose Tracking Algorithm

이 알고리즘은 tracking pseudo code이다.
사실 다 앞에서 설명한 내용이라서 굳이 다시 설명할 필요는 없을 것 같지만, 와 에 각각 detect된 joint와 optical-flow에 기반에 추정된 joint들을 넣고, 얘네를 NMS(Non-Maximum Suppression)를 이용해 중복을 제거한 들을 similarity metric 기준으로 greedy matching한다. 이 내용을 에 차곡차곡 쌓아두는 내용이 설명되어 있다 !
3. Experimental
 위의 표는 COCO val2017 기준으로 ```CPN```, ```Hourglass```를 비교한 차트이다. 동일 resolution의 input 기준으로 두 모델보다 좋은 성능(AP)을 보임을 확인할 수 있다.
위의 표는 COCO val2017 기준으로 ```CPN```, ```Hourglass```를 비교한 차트이다. 동일 resolution의 input 기준으로 두 모델보다 좋은 성능(AP)을 보임을 확인할 수 있다.
그리고 pose tracking의 경우에는 PoseTrack이라는 dataset 기준으로 성능을 비교했다.
- single frame pose estimation (metric mAP)
- single frame pose estimation with temporal information
- tracking using multi-object tracking metric
다양한 성능 비교 표가 있었는데, tracking 쪽은 내가 아직 공부를 많이 못해봐서 metric 부분이 많이 생소해 다 가져오지는 않았다.
 일단 상단의 표에서 확인할 수 있듯이, 기존의 모델들과 비교했을 때 성능(mAP, MOTA)에서 꽤 큰 차이로 좋은 성능을 보임을 알 수 있다.
일단 상단의 표에서 확인할 수 있듯이, 기존의 모델들과 비교했을 때 성능(mAP, MOTA)에서 꽤 큰 차이로 좋은 성능을 보임을 알 수 있다.
다만 아쉬웠던 점은 이 논문 자체가 실험 결과를 기반으로 쓰여져 있었기 때문에 이론적인 뒷받침이 많이 없었고, 다른 모델들의 결과(CPN, hourglass) 역시 직접 구현해 실험한 것이 아니라 해당 논문에 있는 실험결과를 그대로 가져왔기 때문에 동일 환경에서 실험한 결과가 아니라는 것이었다.
비슷한 맥락에서의 문제점이겠지만, 논문에서는 이 모델이 매우 간단하고 효과적이라는 것을 강조했으나 실험결과에서 정량적으로 이 모델이 얼마나 간단한지를 알 수 있는 객관적인 지표(파라미터의 크기, 메모리 소비 정도, 학습/인퍼런스 시간 등등 ... )가 없다는 것도 아쉬웠다.
물론 생긴 네트워크 모양을 보면 확실하게 이전 모델들 보다 간단하구나가 보이기는 하지만 말이다 .. .
4. Conclusion
이 논문에서는 pose estimation과 tracking에서 사용할 수 있는 간단하고 효과적인 baseline network를 제안한다. 다만 실제 논문에서는 baseline network에 대한 설명보다는 tracking에서 사용할 수 있는 similarity metric과 tracking training algorithm을 설명하는 데에 더 지면을 할애하기는 한다. (사실 baseline network)가 설명할 께 많이 없기는 하다.
개인적으로는 3. Experimental에서 잠깐 언급했듯이 네트워크가 효율적이라는 걸 정량적으로 볼 수 있는 지표가 없어서 조금 아쉬웠다. 그리고 나는 원래 매 프레임 pose estimation을 하면 컴퓨팅이 너무 크니까 network propagation은 몇 프레임마다 한번씩만 하고, 나머지 프레임은 tracking을 해서 컴퓨팅을 조금 하는 용도로 tracking을 같이 하는 줄 알았는데 그게 아니었다 ... ..
졸업연구ㅇㅔ서 아마 이거 할 거 같은데 큰일 났다 .. .^^
- 아 진짜 이거 레이텍 수식 검색해가면서 진짜 열심히 tracking 부분 수식 썼었는데 다시 쓰려니까 의욕 XXXXX 여서 그냥 간단한 것만 썼다 .. . . 다음에 수식 많이 나오는거 리뷰하면 그때는 진짜 예쁘게 써야지
- 쓰다보니까 너무 단순한 논문 번역본이 되어가는 것 같다.. ㅠㅠ 좀 더 핵심만 잘 정리해서 써야겠다 ..!
Reference
