오늘 정리할 내용은 Human Pose Estimation 중에서도 Stacked Hourglass Networks for Human Pose Estimation 이라는 논문이다. 사실 이 논문 이전에 DeepPose처럼 pose estimation task에 딥러닝 모델을 사용한 논문들이 몇개 있지만 이걸 제일 먼저 정리하는 이유는 내가 이걸 그저께 읽었기 때문이ㄷㅏ...
1. Introduction
일단 Stacked Hourglass Networks for Human Pose Estimation paper는 제목 자체에서 많은 걸 알 수 있다. Task는 human pose estimation이고, neural network를 사용했고, hourglass network를 여러개 겹쳐서 전체 network를 구성했다는 것 정도?

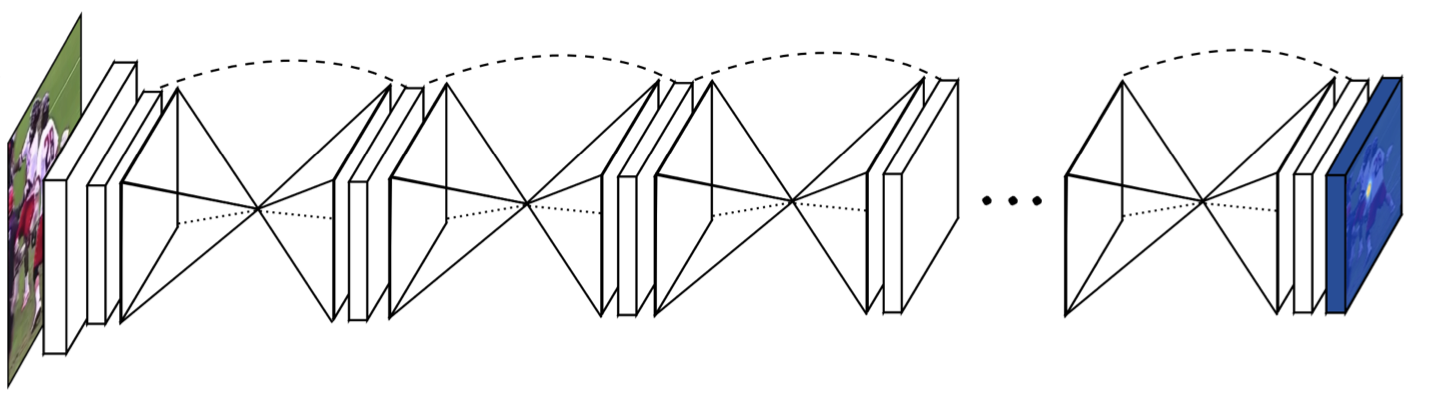
논문에서 보여주는 네트워크 그림을 보면 좀 더 직관적으로 생각할 수 있다. 이 Stacked hourglass network는 기존의 human pose estimation에서 사용하던 방식과는 다르게 Convnet을 메인 building block으로 잡아 전체 네트워크를 구성했고, 하나의 RGB 이미지가 인풋으로 들어오면 이미지는 maxpooling과 unsampling으로 이루어진 hourglass를 매우 많이 거쳐서 joint heatmap으로 나오게 된다.
결정적으로 이렇게 maxpooling으로 low resolution까지 쭉 내렸다가 다시 upsampling으로 다시 high resolution으로 올리면서 feature를 뽑아내는 과정을 여러번 반복하면서 보다 정확한 output을 얻어낸다고 한다..
2. Stacked Hourglass Network
 Stacked hourglass network에서 hourglass network 하나만 떼와서 자세히 보면 이렇게 생겼다. FCN이랑 비슷하지만 bottom-up processing과 top-down processing 모듈의 symmetric한 distribution이 다른 점이라고 저자는 얘기하는데 나는 FCN보다는 U-Net의 encoder - decoder 구조와 비슷하게 생겼다고 이해했다.
Stacked hourglass network에서 hourglass network 하나만 떼와서 자세히 보면 이렇게 생겼다. FCN이랑 비슷하지만 bottom-up processing과 top-down processing 모듈의 symmetric한 distribution이 다른 점이라고 저자는 얘기하는데 나는 FCN보다는 U-Net의 encoder - decoder 구조와 비슷하게 생겼다고 이해했다.
1) Hourglass Design
Human pose estimation을 하기 위해서는 이미지의 크고 작은 feature를 동시에 잘 잡아낼 수 있어야 한다고 한다. 뭐 당연한 얘기일 수도 있겠지만 하나의 네트워크로 다양한 resolution의 feature를 잡아내고 프로세싱하기 위해서는 단순한 CNN보다는 FCN에서 했던 것처럼 skip layer를 더해 spatial information을 보존하는 방법을 선택했다고 한다. 말로 하는 것보다 그림을 보는게 더 이해가 잘될 것 같기는 하지만..
어쨌든 convolution과 max pooling를 이용해 feature를 low resolution까지 내리는데, 이 과정에서 중간중간에 max pooling 이후에 branch를 빼서 각 resolution에 맞는 convolution 연산을 따로 해준다. 이렇게 가장 낮은 차원의 resolution으로 내려간 다음에는 다시 upsampling을 이용해서 resolution을 다시 올려주는데, 이때 아까 branch 따로 빼서 convolution 연산 해뒀던 애들이랑 같이 합쳐주면서 차원을 올린다.
마지막으로 stacked hourglass network 연산을 거친 후에는 두번의 1x1 convolution 연산을 해서 각 joint의 heat map을 최종 output으로 뽑게 된! 다!
2) Layer Implementation
 paper에서는 전반적인 hourglass 모양을 유지하면서 다양한 레이어를 실험해봤는데, 최종 성능이나 학습 시간에 따라서 다양한 결과가 정리되어 있다. 그렇게 해서 결정된 최종 디자인은 residual module과 최대 크기 3x3의 conv fileter, 64x64으로 고정된 최대 input resolution 등등등이 있다...
paper에서는 전반적인 hourglass 모양을 유지하면서 다양한 레이어를 실험해봤는데, 최종 성능이나 학습 시간에 따라서 다양한 결과가 정리되어 있다. 그렇게 해서 결정된 최종 디자인은 residual module과 최대 크기 3x3의 conv fileter, 64x64으로 고정된 최대 input resolution 등등등이 있다...
3) Stacked Hourglass with Intermediate Supervision
 이 paper에서는 hourglass를 반복적으로 쌓아서 이전 hourglass의 output을 이 다음 hourglass의 input으로 주는데, 이러한 과정을 통해서 처음 예측했던 거를 다시 재예측하고, 재예측할 수 있도록 한다. 그러면 여기에서 중간 중간 heatmap에도 loss를 적용할 수 있게된다. 즉 각각 hourglass의 intermediate supervision을 iterative stages로 이해할 수 있게 된다.
이 paper에서는 hourglass를 반복적으로 쌓아서 이전 hourglass의 output을 이 다음 hourglass의 input으로 주는데, 이러한 과정을 통해서 처음 예측했던 거를 다시 재예측하고, 재예측할 수 있도록 한다. 그러면 여기에서 중간 중간 heatmap에도 loss를 적용할 수 있게된다. 즉 각각 hourglass의 intermediate supervision을 iterative stages로 이해할 수 있게 된다.
그림을 보면 더 이해가 나을 것 같은데, 일단 이번 hourglass에서 나온 output에 1x1 conv를 실행해서 차원수를 맞춰주고, 이전 hourglass에서 나온 output이랑 합쳐서 다음 hourglass로 넘겨준다. 이렇게 함으로써 spatial location의 feature도 중간에 잃어버리지 않고 잘 유지하고, 전반적인 location 정보도 잘 유지했다고 한다. 사실 hourglass module 여러개 쌓는거랑 이거랑 무슨 상관인지는 잘 모르겠다 .. upsamling할때 이전 정보 combine하는 걸로는 잘 안됐나 보다 ..ㅠㅡㅠ
논문에서는 hourglass 8개를 사용했다고 한다 !
3. Experimental

MPII 데이터 셋에 대해서 적용한 거라는데 성능이 꽤 좋은 걸 확인할 수 있다.

iteration이 많아질 수록 성능이 상승함을 확인할 수 있고, 다양한 hourglass 모듈에 따른 성능차이를 확인할 수 있다.
Reference
