오차? 생길게~ (JS 숫자 처리 코드 톺아보기)
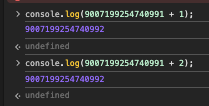
JS는 C언어와 달리 int, float, long과 같은 자료형이 없고 죄다 Number로 통일이다.
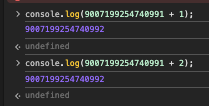
그래서 그런지 이런 이상한 오차가 종종 발생한다. JS에서는 const에 9007199254740993을 그냥 담을 수 없을까?
우선
const x = 9007199254740993;이 한 줄을 실행하면 일어나는 일들을 순서대로 따라가보면 답이 나올 것이다.
작성일 기준, 각 레포지토리의 main 브랜치 코드를 보며 정리했다.
0. scanner
scanner가 소스코드를 읽어서 토큰으로 쪼개는 과정이다. 예를 들어 다음과 같은 형태로 변환될 것이다.
Identifier("const")
Identifier("x")
Token("=")
Token(NUMBER, "9007199254740993")
Token(";")문자열 "9007199254740993"이 NUMBER 토큰의 literal buffer에 저장된다. 이 시점까지 scanner는 문자열로만 숫자를 인식한다.
1. parser
// src/parsing/parser.cc
Expression* Parser::ExpressionFromLiteral(Token::Value token, int pos) {
switch (token) {
case Token::kNullLiteral:
// (중략)
case Token::kNumber: {
double value = scanner()->DoubleValue();
return factory()->NewNumberLiteral(value, pos);
}
case Token::kBigInt:
return factory()->NewBigIntLiteral(
AstBigInt(scanner()->CurrentLiteralAsCString(zone())), pos);
case Token::kString: {
return factory()->NewStringLiteral(GetSymbol(), pos);
}
default:
DCHECK(false);
}
return FailureExpression();
}이건 현재 토큰(token)과, 소스코드에서 이 리터럴이 있던 위치(pos)를 받아서 해당 리터럴을 나타내는 AST Expression Node 포인터를 반환하는 함수이다.
Number 토큰의 경우 소수점 유무에 관계없이 DoubleValue()를 통해 double 값으로 변환해서 NewNumberLiteral()를 통해 AST Node를 만든다.
n 접미사가 붙은 BigInt 리터럴(9007199254740993n)은
Token::kBigInt로 분류되어 double 변환을 아예 거치지 않는다. 즉, 정밀도가 필요한 값은 처음부터 Number가 아니라 BigInt 토큰으로 파싱되게 만들어야 한다
// src/parsing/parser.cc
double Scanner::DoubleValue() {
DCHECK(is_literal_one_byte());
switch (current().number_kind) {
case IMPLICIT_OCTAL:
return ImplicitOctalStringToDouble(literal_one_byte_string());
case BINARY:
return BinaryStringToDouble(literal_one_byte_string());
case OCTAL:
return OctalStringToDouble(literal_one_byte_string());
case HEX:
return HexStringToDouble(literal_one_byte_string());
case DECIMAL:
case DECIMAL_WITH_LEADING_ZERO:
return StringToDouble(literal_one_byte_string(), NO_CONVERSION_FLAG);
}
}DoubleValue()는 숫자 리터럴을 분류에 맞는 변환 함수로 라우팅하는 dispatcher인 것 같다. "9007199254740993"은 DECIMAL에 해당하니 StringToDouble 함수를 보면 될 듯 하다
2. conversions
1. 문자열을 숫자 파서로 전달
// src/numbers/conversions.cc
double StringToDouble(base::Vector<const uint8_t> str, ConversionFlag flags,
double empty_string_val) {
return InternalStringToDouble(str.begin(), str.end(), flags,
empty_string_val);
}
double StringToDouble(base::Vector<const base::uc16> str, ConversionFlag flags,
double empty_string_val) {
return InternalStringToDouble(str.begin(), str.end(), flags,
empty_string_val);
}똑같이 생긴 함수가 2개인데, 아마 1바이트 문자열일 때와 UTF-16처럼 2바이트 문자열일 때의 버전으로 나눠놓은 것 같다...
2. 접두사/공백 처리 후 fast_float로 위임
// src/numbers/conversions.cc
template <class Char>
double InternalStringToDouble(const Char* current, const Char* end,
ConversionFlag flag, double empty_string_val) {
if (!AdvanceToNonspace(¤t, end)) {
return empty_string_val;
}
if (flag == ALLOW_NON_DECIMAL_PREFIX) {
// Copy the current iterator, so that on a failure to find the prefix, we
// rewind to the start.
const Char* prefixed = current;
if (*prefixed == '0') {
++prefixed;
if (prefixed == end) return 0;
if (*prefixed == 'x' || *prefixed == 'X') {
++prefixed;
if (prefixed == end) return JunkStringValue();
return InternalStringToIntDouble<4>(prefixed, end, false, false);
} else if (*prefixed == 'o' || *prefixed == 'O') {
// (중략)
}
}
함수의 첫 부분에서는 간단하게 AdvanceToNonspace()함수로 공백을 걸러내거나 prefixed를 통해 2, 8, 10진수 처리를 하는 것 같다.
using UC = std::conditional_t<std::is_same_v<Char, uint8_t>, char, char16_t>;
static_assert(sizeof(UC) == sizeof(Char));
const UC* current_uc = reinterpret_cast<const UC*>(current);
const UC* end_uc = reinterpret_cast<const UC*>(end);
auto ret =
fast_float::from_chars(current_uc, end_uc, value,
static_cast<fast_float::chars_format>(
fast_float::chars_format::general |
fast_float::chars_format::no_infnan |
fast_float::chars_format::allow_leading_plus));
if (ret.ptr == end_uc) return value;
if (ret.ptr > current_uc) {
current = reinterpret_cast<const Char*>(ret.ptr);
if (!allow_trailing_junk && AdvanceToNonspace(¤t, end)) {
return JunkStringValue();
}
return value;
}이 부분이 진짜 핵심인데, fast_float 라고 하는 라이브러리를 사용해서 문자열을 double 형으로 변환한다.
ret.ptr == end_uc이면 fast_float가 문자열을 끝까지 읽었다고 판단하고 바로 결과(double형 데이터)를 반환한다ret.ptr > current_uc이면 fast_float가 문자열의 일부분만 parsing에 성공했다고 판단한다. 뒤에 남은 문자가 공백뿐이면 허용되고, 공백 이외의 junk가 남아 있으면(allow_trailing_junk가 false이면) 실패 처리하며JunkStringValue를 반환한다. (숫자 취급 X)
3. fast_float 라이브러리
V8의 InternalStringToDouble 함수에서 이런 식으로 라이브러리를 호출하고 있었다.
fast_float::from_chars(current_uc, end_uc, value,
static_cast<fast_float::chars_format>(
fast_float::chars_format::general |
fast_float::chars_format::no_infnan |
fast_float::chars_format::allow_leading_plus));no_infnan은 Infinity, NaN 같은 것들을 허용하지 않는 플래그이다. 따로 언급하진 않았지만InternalStringToDouble함수의 마지막 부분에서 이것들에 대한 처리를 따로 한다.allow_leading_plus은+12<-- 이렇게 앞에 +를 붙인 숫자를 허용하도록 하는 플래그이다.
라이브러리 레포지토리로 들어갔더니 API처럼 보이는 헤더파일들이 있었는데 로직이 너무 파편화되어 있어서 약간 힘들었다...
문자열 "9007199254740993"가 이 parsed_number_string_t 구조체의 각 필드에 들어가게 된다.
// include/fast_float/ascii_number.h
template <typename UC> struct parsed_number_string_t {
int64_t exponent{0};
uint64_t mantissa{0};
UC const *lastmatch{nullptr};
bool negative{false};
bool valid{false};
bool too_many_digits{false};
// contains the range of the significant digits
span<UC const> integer{}; // non-nullable
span<UC const> fraction{}; // nullable
parse_error error{parse_error::no_error};
};각 필드는 다음과 같은 의미를 가진다.
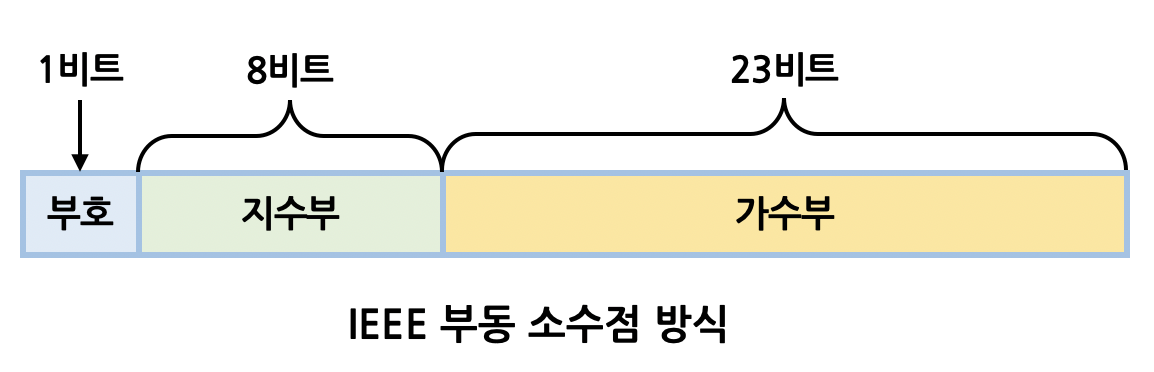

exponent: 10의 지수 (부동소수점에서 지수부)mantissa: 소수점을 무시하고 숫자(digits)를 10진 정수로 누적한 값 (부동소수점에서 가수부)lastmatch: 숫자 파싱이 끝난 위치를 가리키는 포인터negative: 부호valid: parsing 성공 여부too_many_digits: 숫자가 19자리 이상인 지 여부integer: 정수부 sapnfraction: 소수부 spanerror: 에러
1. 파싱 옵션 정리 및 유효성 검사
from_chars_float_advanced 함수가 parsed_number_string_t 구조체에 값을 넣기 위한 관리?검증? 역할을 한다. (그냥 넘어가도 될듯하다)
// include/fast_float/parse_number.h
template <typename T, typename UC>
FASTFLOAT_CONSTEXPR20 from_chars_result_t<UC>
from_chars_float_advanced(UC const *first, UC const *last, T &value,
parse_options_t<UC> options) noexcept {
static_assert(is_supported_float_type<T>::value,
"only some floating-point types are supported");
static_assert(is_supported_char_type<UC>::value,
"only char, wchar_t, char16_t and char32_t are supported");
chars_format const fmt = detail::adjust_for_feature_macros(options.format);
from_chars_result_t<UC> answer;
if (uint64_t(fmt & chars_format::skip_white_space)) {
while ((first != last) && fast_float::is_space(*first)) {
first++;
}
}
if (first == last) {
answer.ec = std::errc::invalid_argument;
answer.ptr = first;
return answer;
}
parsed_number_string_t<UC> pns =
uint64_t(fmt & detail::basic_json_fmt)
? parse_number_string<true, UC>(first, last, options)
: parse_number_string<false, UC>(first, last, options);
if (!pns.valid) {
if (uint64_t(fmt & chars_format::no_infnan)) {
answer.ec = std::errc::invalid_argument;
answer.ptr = first;
return answer;
} else {
return detail::parse_infnan(first, last, value, fmt);
}
}
// call overload that takes parsed_number_string_t directly.
return from_chars_advanced(pns, value);
}2. 구조체 각 필드에 값 삽입
// include/fast_float/ascii_number.h
template <bool basic_json_fmt, typename UC>
fastfloat_really_inline FASTFLOAT_CONSTEXPR20 parsed_number_string_t<UC>
parse_number_string(UC const *p, UC const *pend,
parse_options_t<UC> options) noexcept {
chars_format const fmt = detail::adjust_for_feature_macros(options.format);
UC const decimal_point = options.decimal_point;함수의 첫 부분에서 초기 세팅을 한다. decimal_point가 소수점인데, .으로 하드코딩하지 않고 locale 옵션에 따라 소수점을 변경할 수 있게 해놓은 모습이다 ㄷㄷ
parsed_number_string_t<UC> answer;
answer.valid = false;
answer.too_many_digits = false;
// assume p < pend, so dereference without checks;
answer.negative = (*p == UC('-'));드디어 parsed_number_string_t의 필드에 값을 삽입한다. 재밌는 점은 parsing 성공 여부(valid)를 먼저 false라고 해놓은 것인데, 아마 이 함수가 끝날 때 쯤에 성공이라고 판단되면 true로 바꿀 것 같다.
negative는 일단 -인지만 판단해서 넣어놓는데, 바로 밑에서 디테일한 처리를 한다.
-
부호 판단
// C++17 20.19.3.(7.1) explicitly forbids '+' sign here if ((*p == UC('-')) || (uint64_t(fmt & chars_format::allow_leading_plus) && !basic_json_fmt && *p == UC('+'))) {다음과 같은 조건을 만족하면 부호 결정 if문으로 들어간다. 만족하지 않으면 부호 결정 시도를 안하고 양수로 취급하는 것 같다.
-
*p == UC('-')
옵션 관계 없이 첫 포인터에-가 있을 때 -
uint64_t(fmt & chars_format::allow_leading_plus) && !basic_json_fmt && *p == UC('+'))
allow_leading_plus옵션이 켜져 있고,basic_json_fmt이 아닌 경우에, 첫 포인터에+가 있을 때앞서 V8의
InternalStringToDouble템플릿에서fast_float라이브러리를 호출할 때allow_leading_plus옵션을 설정했었는데, 그게 이 부분에서 영향을 미친다.
if 조건에서 부호가 있는지를 검사했으며, 지금까지 포인터는 첫번째 문자를 가리키고 있었다. 때문에 무조건 포인터는
-또는+문자를 가리키고 있었을 것이다.++p; if (p == pend) { return report_parse_error<UC>( p, parse_error::missing_integer_or_dot_after_sign); }이 시점에서 포인터를 한 칸 옮겨서 부호 다음 문자를 검사한다. 이건 부호만 있고, 뒤에 아무것도 없을 시에
missing_integer_or_dot_after_sign를 반환하는 if문이다.FASTFLOAT_IF_CONSTEXPR17(basic_json_fmt) { if (!is_integer(*p)) { // a sign must be followed by an integer return report_parse_error<UC>(p, parse_error::missing_integer_after_sign); } }basic_json_fmt인 경우에 부호 다음 문자가 숫자가 아닐 시missing_integer_after_sign에러를 뱉는다.else { if (!is_integer(*p) && (*p != decimal_point)) { return report_parse_error<UC>( p, parse_error::missing_integer_or_dot_after_sign); } }basic_json_fmt이 아닌 경우에는 부호 다음 문자가 숫자(integer)나.(dot)가 아니라면missing_integer_or_dot_after_sign에러를 뱉는다.UC const *const start_digits = p;아까 포인터를 부호 다음 위치로 옮겼으니, 숫자(digits)의 시작 위치(
start_digits)에 현재 포인터를 할당하고 부호 판단이 끝난다. -
-
정수부 처리
uint64_t i = 0; // an unsigned int avoids signed overflows (which are bad) while ((p != pend) && is_integer(*p)) { // a multiplication by 10 is cheaper than an arbitrary integer // multiplication i = 10 * i + uint64_t(*p - UC('0')); ++p; } UC const *const end_of_integer_part = p;아까 설정한
start_digits부터 digits 연속 구간을 찾고, 읽은 digits를 변수i에 10진수로 누적한다. 이 시점에서는 overflow를 허용하고 나중에 처리한다.정수(integer)의 마지막 위치(
end_of_integer_part)에 현재 포인터를 할당한다.int64_t digit_count = int64_t(end_of_integer_part - start_digits); answer.integer = span<UC const>(start_digits, size_t(digit_count));정수의 마지막 위치와 숫자의 위치의 차를 구하여 숫자 개수(
digit_count)에 할당하고,parsed_number_string_t구조체의integer필드에 정수부의 원문 범위를 span으로 저장한다.FASTFLOAT_IF_CONSTEXPR17(basic_json_fmt) { // at least 1 digit in integer part, without leading zeros if (digit_count == 0) { return report_parse_error<UC>(p, parse_error::no_digits_in_integer_part); } if ((start_digits[0] == UC('0') && digit_count > 1)) { return report_parse_error<UC>(start_digits, parse_error::leading_zeros_in_integer_part); } }이후에
basic_json_fmt인 경우에 숫자 개수가 0일 시no_digits_in_integer_part에러를, 첫 숫자가 0일 시leading_zeros_in_integer_part에러를 반환하며 정수부 처리가 끝난다.
-
소수부 처리
int64_t exponent = 0; bool const has_decimal_point = (p != pend) && (*p == decimal_point); if (has_decimal_point) { ++p; UC const *before = p;우선 소수점(
decimal_point)이 존재하는지(has_decimal_point) 검사를 한다.
만약 소수점이 있다면, 정수의 마지막 위치에 있던 포인터를 앞으로 옮기고, 소수점 이후 첫 자리 위치를 변수before에 저장한다.// can occur at most twice without overflowing, but let it occur more, since // for integers with many digits, digit parsing is the primary bottleneck. loop_parse_if_eight_digits(p, pend, i); while ((p != pend) && is_integer(*p)) { uint8_t digit = uint8_t(*p - UC('0')); ++p; i = i * 10 + digit; // in rare cases, this will overflow, but that's ok }반복문으로 포인터를 이동시키며 소수 부분 숫자들을 읽는다. 이때 소수점을 무시하고 기존 변수
i에 10진수로 누적한다. 예를 들어 12.34를 parsing할 때 이 while문을 지나면i는 1234가 되는 식이다. (이i가 나중에parsed_number_string_t구조체의mantissa에 저장된다)exponent = before - p;포인터를 모두 이동시킨 후 소수 부분 끝 위치에서
exponent계산을 하는데, 소수점 직후 숫자의 주소인before에서 끝 주소를 뺐으니 음수가 나오게 된다. 아까 나온i에 을 곱하면 원래 숫자가 나오는 식이다.예를 들어 12.34의 경우,
before가 3의 주소를 가리키고, 현재 포인터가 소수의 끝(while문에서 4까지 읽었기 때문에 그 다음 주소)을 가리키고 있으니 이고, 이기 때문에 가 성립한다.answer.fraction = span<UC const>(before, size_t(p - before)); digit_count -= exponent;마지막으로 정수부 처리 할 때와 동일하게 소수부의 원문 범위를
parsed_number_string_t구조체의fraction에 span으로 저장한다.
현재 숫자 개수(digit_count)에 정수부 개수까지만 저장되어 있는데, 거기에exponent를 빼서(음수기 때문에) 전체 숫자 개수를 반영한다.
-
지수부 처리
int64_t exp_number = 0; // explicit exponential part if ((uint64_t(fmt & chars_format::scientific) && (p != pend) && ((UC('e') == *p) || (UC('E') == *p))) || (uint64_t(fmt & detail::basic_fortran_fmt) && (p != pend) && ((UC('+') == *p) || (UC('-') == *p) || (UC('d') == *p) || (UC('D') == *p)))) { UC const *location_of_e = p; if ((UC('e') == *p) || (UC('E') == *p) || (UC('d') == *p) || (UC('D') == *p)) { ++p; }조건이 상당히 긴데... 그냥 지수부의 시작인 지 판단하는 것 같다.
만약 맞다면 나중에 실패했을 때를 대비해서 현재 주소('e' 또는 'E'의 위치)를location_of_e에 저장하고, 포인터를 한 칸 이동한다.if ((p != pend) && (UC('-') == *p)) { neg_exp = true; ++p; } else if ((p != pend) && (UC('+') == *p)) { ++p; }지수부의 부호가 음수인 경우
neg_exp를true로 설정한다.if ((p == pend) || !is_integer(*p)) { if (!uint64_t(fmt & chars_format::fixed)) { // The exponential part is invalid for scientific notation, so it must // be a trailing token for fixed notation. However, fixed notation is // disabled, so report a scientific notation error. return report_parse_error<UC>(p, parse_error::missing_exponential_part); } // Otherwise, we will be ignoring the 'e'. p = location_of_e; }'e'의 뒤에 숫자가 나오지 않았을 때,
-
고정 소수점 표기를 금지하는 옵션(fixed)이라면
missing_exponential_part에러를 뱉는다 -
고정 소수점 표기가 허용(general)되어 있다면 'e'를 지수부가 아닌 것으로 간주하고 포인터를
location_of_e로 되돌리고 지수부 parsing을 취소한다(ignoring).
else { while ((p != pend) && is_integer(*p)) { uint8_t digit = uint8_t(*p - UC('0')); if (exp_number < 0x10000000) { exp_number = 10 * exp_number + digit; } ++p; } if (neg_exp) { exp_number = -exp_number; } exponent += exp_number; }'e' 뒤에 숫자가 정상적으로 있다면 while을 돌려서 지수 값을 정수로
exp_number에 저장한다.neg_exp를 통해 부호를 적용한 뒤, 소수부 처리할 때 계산한exponent에 더한다. -
-
성공?
answer.lastmatch = p; answer.valid = true;arsed_number_string_t구조체의valid를 true로 바꾸고,lastmatch에 현재 포인터를 저장한다. -
truncation
아까 전체 숫자를 10진수로 누적했던 변수
i의 자료형이 uint_64이기 때문에, 자릿수가 너무 크면 overflow 위험이 있다.// E.g., 0.000000000...000. UC const *start = start_digits; while ((start != pend) && (*start == UC('0') || *start == decimal_point)) { if (*start == UC('0')) { digit_count--; } start++; }앞쪽의 '0'과 decimal_point를 스킵해서 실제 유효한 숫자(significant digits)를 재계산한다. 그래도
digit_count > 19라면 truncation이라는 작업을 진행한다. ("9007199254740993"은digit_count = 16이기 때문에 여기서 걸리지는 않는다)answer.too_many_digits = true;이때
parsed_number_string_t구조체의too_many_digits를 ture로 바꾼다.i = 0; p = answer.integer.ptr; UC const *int_end = p + answer.integer.len(); uint64_t const minimal_nineteen_digit_integer{1000000000000000000}; while ((i < minimal_nineteen_digit_integer) && (p != int_end)) { i = i * 10 + uint64_t(*p - UC('0')); ++p; } if (i >= minimal_nineteen_digit_integer) { // We have a big integer exponent = end_of_integer_part - p + exp_number; } else { // We have a value with a fractional component. p = answer.fraction.ptr; UC const *frac_end = p + answer.fraction.len(); while ((i < minimal_nineteen_digit_integer) && (p != frac_end)) { i = i * 10 + uint64_t(*p - UC('0')); ++p; } exponent = answer.fraction.ptr - p + exp_number; }truncation은
i를 그냥 초기화해버리고, 앞에서부터 19자리를 다시 읽어서 채우는 작업이다. 숫자를 19글자까지만 읽고 말았으므로, 읽지 않은 뒷부분의 자리수만큼 지수를 키움으로써 값의 크기를 대략적으로 맞춘다. 예를 들어 25자리 숫자 중 19자리까지 읽은 상황에서는 지수에 +6을 해주는 식이다. -
진짜 끝
나머지 필드들을 채우고 반환한다.
answer.exponent = exponent; answer.mantissa = i; return answer;
이 모든 과정을 거친 parsed_number_string_t 구조체는 다음과 같다.
parsed_number_string_t<char> pns {
.mantissa = 9007199254740993,
.exponent = 0,
.negative = false,
.too_many_digits = false,
.integer = "9007199254740993",
.fraction = "",
.valid = true
};여기까지 값이 멀쩡하게 유지되는 모습이다..
3. binary64(double) 값으로 변환
from_chars_advanced는 parsed_number_string_t를 받아서 value에 float 또는 double 값을 저장하는 함수이다. 파싱된 10진 숫자를 float 또는 double로 변환하는 역할이라고 생각하면 간단하다.
// include/fast_float/parse_number.h
template <typename T, typename UC>
FASTFLOAT_CONSTEXPR20 from_chars_result_t<UC>
from_chars_advanced(parsed_number_string_t<UC> &pns, T &value) noexcept {
// (생략)
from_chars_result_t<UC> answer;
answer.ec = std::errc(); // be optimistic
answer.ptr = pns.lastmatch;
ec는 0(성공)으로 초기화하고, 함수 마지막에서 overflow/underflow일 때 실패 처리 한다.
이 함수에서도 포인터는 파싱이 끝난 위치를 뜻하는데, 파싱이 끝난 pns를 받았으므로 pns 위치(lastmatch)로 냅두고 나중에 그대로 반환한다.
if (!pns.too_many_digits && clinger_fast_path_impl(pns.mantissa, pns.exponent, pns.negative, value))
return answer; 10진 문자열로 표현된 실수를 2진 부동소수점으로 반올림해 표현하는 연산이 매우 복잡하기 때문에, 이 과정을 앞두고 Clinger's fast path(그냥 조기 return인 듯)로 갈 지 판단하는 if문이다. 2가지 조건을 검사하는데 이는 다음과 같다.
-
pns.too_many_digits가 false인가too_many_digits는 유효 숫자가 너무 길어서truncate당했다는 뜻인데, 단순 변환하면 반올림이 틀릴 가능성이 크기 때문에 조기 return하지 않는다. -
clinger_fast_path_impl()가 true인가이 함수는 다음 조건들을 확인한다
-
를 만족하는가?
이 범위를 벗어나면 연산의 정확도가 떨어진다고 한다.
-
rounding mode가 “round-to-nearest”인가?
현재 CPU(FPU)의 rounding mode가
FE_TONEAREST인 지 확인한다.IEEE 754에 따른 rounding mode의 종류는 다음과 같다.
FE_TONEAREST: 가장 가까운 값으로 반올림 (동률이면 짝수 쪽으로)FE_DOWNWARD: 음의 무한대 방향으로 버림FE_UPWARD: 양의 무한대 방향으로 올림FE_TOWARDZERO: 0 방향으로 버림
-
를 만족하는가?
이 범위를 벗어나면 double 자료형의 정밀도를 보장할 수 없기 때문이다. 9007199254740993의 경우 여기서 false가 뜨기 때문에
Clinger's fast path로 갈 수 없다.
-
adjusted_mantissa am =
compute_float<binary_format<T>>(pns.exponent, pns.mantissa); adjusted_mantissa 구조체는 다음과 같은 형식을 가진다
uint64_t mantissa{0}: 2진 정규화된 가수(bits)int32_t power2{0}: 2의 지수
compute_float 함수를 호출하여 값을 계산한다. 이 함수는 대부분의 입력에서 빠른 근사 계산으로 반올림을 확정하는데, 계산 결과가 확실하게 반올림이 결정되는 구간에 있다면 정상 값을 반환하지만, 표현 가능한 두 수의 정 중앙 근처에 있다면(Halfway Case) 반올림을 확정하기 어렵게 된다. 그래서 나중에 나올 digit_comp로 넘겨서 재계산이 필요하다는 뜻으로 am.power2에 음수를 넣어 반환(fallback)한다.
바로 이 과정에서 9007199254740993이 9007199254740992로 연산된다. 자세한 내용은 뒤에서 알아보자
if (pns.too_many_digits && am.power2 >= 0) {
if (am != compute_float<binary_format<T>>(pns.exponent, pns.mantissa + 1)) {
am = compute_error<binary_format<T>>(pns.exponent, pns.mantissa);
}
} pns.too_many_digits==true인 경우, 잘려나간 뒷 부분이 반올림에 영향을 주는 지 확인한다. 만약 mantissa와 mantissa+1이 서로 다른 float 결과를 만든다면, '경계선'에 있는 값이라고 판단하여 compute_error 함수로 재계산한다.
if (am.power2 < 0) {
am = digit_comp<T>(pns, am);
} am.power2가 음수(fallback)이면, digit_comp로 들어간다. 이 함수는 좀 느리지만 정확하게 반올림 방향을 결정한다.
to_float(pns.negative, am, value); to_float 함수에서 부호(negative)를 붙이고, exponent bias를 적용하고 mantissa bit 마스킹을 하면 value에 최종 결과값이 들어간다.
// Test for over/underflow.
if ((pns.mantissa != 0 && am.mantissa == 0 && am.power2 == 0) ||
am.power2 == binary_format<T>::infinite_power()) {
answer.ec = std::errc::result_out_of_range;
}
return answer;
}마지막으로 underflow와 overflow를 감지하면 함수가 끝난다.
4. halfway 처리와 ties-to-even 반올림(IEEE-754)
아까 이 함수에서 값이 바뀐다고 했는데, 이를 반증하기 위한 test code를 임의로 작성해볼 것이다.
mantissa를 9007199254740993으로, exponent를 0으로 설정하고 다음과 같은 코드를 실행해보면,
#include <iostream>
#include "fast_float/float_common.h"
#include "fast_float/ascii_number.h"
#include "fast_float/decimal_to_binary.h"
int main() {
fast_float::parsed_number_string_t<char> pns;
pns.mantissa = 9007199254740993;
pns.exponent = 0;
auto am = fast_float::compute_float<fast_float::binary_format<double>>(
pns.exponent, pns.mantissa);
std::cout << "power2: " << am.power2 << std::endl;
std::cout << "mantissa: " << am.mantissa << std::endl;
return 0;
}다음과 같은 결과가 나온다.
 IEEE-754 표준 상 변환하고자 하는 double 자료형의 bias는 1023 이므로, 1076-1023=53이다.
IEEE-754 표준 상 변환하고자 하는 double 자료형의 bias는 1023 이므로, 1076-1023=53이다.
즉, compute_float 함수가 을 으로 계산한 것이 원인이다. 이제 이 함수가 왜 이렇게 설계되어 있는지 공부해보자...
우선 는 2진수로 100000000000000000000000000000000000000000000000000001(54bit)이다.
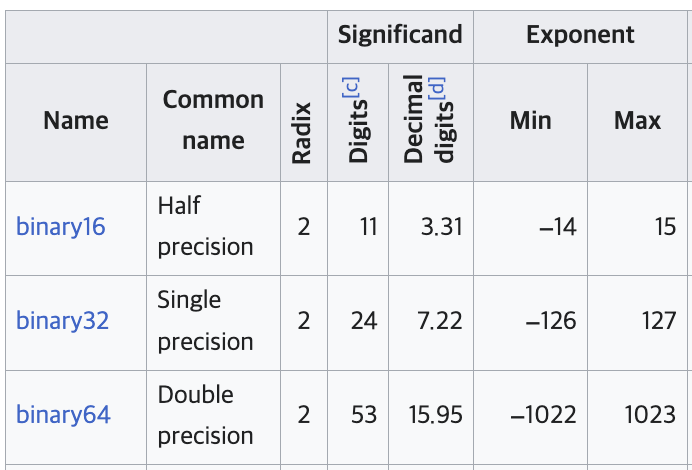
그런데 double 자료형은 IEEE-754 binary64의 spec상 significand 53개 bit로만 값을 표현한다. 따라서 이 구간에서 double이 표현할 수 있는 값은 다음 2개로 귀결된다. 표현 간격(ULP)가 2인 것이다.
-
10000...000(53bit) = 9007199254740992 = -
10000...001(53bit) = 9007199254740994 =
54번째 bit를 저장할 공간이 없어서 54번째부터의 bit를 탈락(drop)시켜야 하기 때문이다. 은 저 두 값 중 하나로 '반올림' 되어야 하는 운명이다.
-
round to nearest
IEEE-754의 기본 반올림 규칙이 'round to nearest' 이다. 다른 규칙들도 몇개 더 있긴 한데 이 라이브러리에서는 'round to nearest'를 적용하는 것 같다.
값을 가장 가까운 수로 반올림하는 규칙이다.
대부분의 경우는 더 가까운 값이 명확하지만, 은 두 값의 정확한 중앙(halfway) 에 위치하기 때문에 tie-break가 요구된다.
-
GRS
실제 부동소수점 구현에서는 탈락할 bit들을 직접 비교하지 않고 halfway인 지 여부를 내부적으로 GRS bit를 이용해 판정한다.
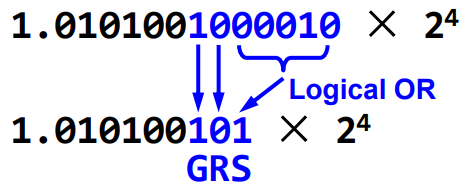
- Guard bit: 유지할 마지막 bit 바로 다음 bit
- Round bit: Guard bit 다음 bit
- Sticky bit: Guard bit 뒤에 1이 하나라도 있는지 여부 (OR)
이 3개 bit를 합쳐서 버려지는 부분이 정확히
1000...00인 지(halfway),1000..01인지 등을 구분한다. -
ties to even
IEEE-754에서 이와 같은 halfway 상황에서 tie-break를 위해 반올림 규칙 중 'ties to even'을 사용한다.
'ties to even'은 반올림 대상이 두 값의 정확한 중앙에 위치할 때 반올림 결과의 significand의 LSB(최하위 bit)를 0이 되도록(even) 선택한다.
만약 항상 올림하면 값이 양의 방향으로 편향될 것이고, 이는 반대 경우에서도 마찬가지이다. 때문에 통계적으로 편향을 최소화시키기 위해 "ties to even"을 적용하는 것이다.
compute_float함수는 Fast Number Parsing Without Fallback 이라는 논문을 토대로 구현되어 있는데, 아직 필자가 이해할 수준이 아닌 것 같아서 반올림 하는 부분만 간단히 살펴봤다..
아래 코드는 compute_float가 binary64로 변환할 때 최종 반올림을 수행하는 부분이다. 이때 answer.mantissa는 우리가 처음 입력한 정수를 단순히 2진법으로 바꾼게 아니다. 반올림을 위해 GRS를 포함한 중간 mantissa다. 그리고 맨 아래서 answer.mantissa >>= 1에서 그 여분 bit를 떼어내며 최종 mantissa로 만든다.
// usually, we round *up*, but if we fall right in between and and we have an
// even basis, we need to round down
// We are only concerned with the cases where 5**q fits in single 64-bit word.
if ((product.low <= 1) && (q >= binary::min_exponent_round_to_even()) &&
(q <= binary::max_exponent_round_to_even()) &&
((answer.mantissa & 3) == 1)) { // we may fall between two floats!
if ((answer.mantissa << shift) == product.high) {
answer.mantissa &= ~uint64_t(1); // flip it so that we do not round up
}
}
answer.mantissa += (answer.mantissa & 1); // round up
answer.mantissa >>= 1;(answer.mantissa & 3) == 1 이 조건은 마지막 2개의 bit가 2진수로 01인가를 판단하는 것이다. Guard bit가 1이고 Round bit가 0이라서 halfway일 가능성이 있는 것이다. 아직 확정은 아니고 Sticky bit까지 까봐야 아는 거긴 하다.
(answer.mantissa << shift) == product.high 소수점 아래로 버려지는 숫자(나머지)들이 정말 0인지(Sticky bit = 0) 확인하는 조건인데, 만약 나머지가 조금이라도 있다면 이 조건에서 false가 뜬다.
이 조건 이후의 로직은 answer.mantissa += (answer.mantissa & 1);을 통해 01을 10으로 올림하는 코드이다. 근데 100...001은 정확히 100...000과 100...010의 정 중앙이기 때문에 이 조건에서 true가 뜬다. 따라서 if 블럭 안에 있는 다음 코드가 실행되게 된다.
answer.mantissa &= ~uint64_t(1);올림을 유발하는 LSB 1을 강제로 0으로 바꿔서 100...000으로 만드는 코드이다. 이렇게 되면 answer.mantissa += (answer.mantissa & 1);을 만나도 올림 되지 않는다. 이 코드 때문에 compute_float의 결과가 으로 나오는 것이다.
4. 다시 parser로 돌아가서...
InternalStringToDouble 함수는 다음 값을 return한다.
double value = 9007199254740992;parser는 이 값이 어떻게 계산되었는지 모르고, 그저 토큰이 NUMBER라면 double 값을 받아서 AST node를 만드는 책임만 가진다.
// src/parsing/parser.cc
Expression* Parser::ExpressionFromLiteral(Token::Value token, int pos) {
switch (token) {
// (중략)
case Token::kNumber: {
double value = scanner()->DoubleValue(); // 이게 9007199254740992
return factory()->NewNumberLiteral(value, pos);
}
// (중략)
}
return FailureExpression();
}맨 처음에 나왔던 이 ExpressionFromLiteral 함수에서 value를 받아서 NewNumberLiteral에 넣는다.
5. AST
AST는 Abstract Syntax Tree의 약자로 JS 문법 구조를 표현한 트리라고 보면 된다. AST는 Zone(arena allocator)에 생성되며, 파싱/컴파일 단계가 끝나면 Zone 단위로 해제된다. 따라서 JS Heap GC 대상에서는 제외된다.
1. 숫자 literal 저장 형태 결정(Smi/HeapNumber)
V8 AST에서 리터럴은 Literal class 하나로 처리된다. 이 class는 Expression을 상속하고 있고, 여러 타입을 enum Type으로 구분한다.
class Literal final : public Expression {
public:
enum Type {
kSmi,
kHeapNumber,
kBigInt,
kString,
kConsString,
kBoolean,
kUndefined,
kNull,
kTheHole,
};
// (중략)
// Returns true if literal represents a Number.
bool IsNumber() const { return type() == kHeapNumber || type() == kSmi; }
double AsNumber() const {
DCHECK(IsNumber());
switch (type()) {
case kSmi:
return smi_;
case kHeapNumber:
return number_;
default:
UNREACHABLE();
}
}
private:
// (중략)
union {
const AstRawString* string_;
int smi_;
double number_;
AstBigInt bigint_;
bool boolean_;
};
}Literal은 내부 enum type으로 숫자 리터럴의 저장 방식을 구분하는데, 종류는 다음과 같다.
kSmi: 빠르게 직접 표현 가능한 정수kHeapNumber: Heap에 저장되는 double 값
2. AST 노드 생성
// src/ast/ast.cc
Literal* AstNodeFactory::NewNumberLiteral(double number, int pos) {
int int_value;
if (DoubleToSmiInteger(number, &int_value)) {
return NewSmiLiteral(int_value, pos);
}
return zone_->New<Literal>(number, pos);
}NewNumberLiteral 함수는 넘겨받은 double 값을 기준으로 DoubleToSmiInteger를 검사하여 true이면 Smi로, false이면 HeapNumber로 저장한다.
// src/numbers/conversions-inl.h
bool DoubleToSmiInteger(double value, int* smi_int_value) {
if (!IsSmiDouble(value)) return false;
*smi_int_value = FastD2I(value);
DCHECK(Smi::IsValid(*smi_int_value));
return true;
}
bool IsSmiDouble(double value) {
return value >= Smi::kMinValue && value <= Smi::kMaxValue &&
!IsMinusZero(value) && value == FastI2D(FastD2I(value));
}다음 조건이 모두 맞다면 Smi(Small Integer) 형식으로 안전하게 변환될 수 있다고 판단한다
-
범위에 맞는 지 (Range check)
값이 현재 아키텍처에서 허용하는 Smi 표현 범위(31bit 또는 32bit 정수 범위) 내에 있는 지 확인한다. 9007199254740992의 경우 이를 초과하기 때문에 Smi가 안된다.
-
-0.0이 아닌 지 (Negative Zero check)깂이
-0.0이라면 부호를 보존해야 하므로 Smi가 아닌 HeapNumber로 취급된다. -
정수인 지 (Integer check)
값을 정수로 변환했다가 다시 double로 변환했을 때 원래 값과 같아야 한다.
이 시점에서 "9007199254740993"이라는 원본 문자열 정보는 더 이상 취급되지 않고 double 값이 유일한 진실이다.
BigInt 리터럴(kBigInt)은 AstBigInt로 digits 자체가 AST에 보존되므로, 정수 정밀도가 필요하면 애초에 n 접미사로 BigInt 경로를 타면 됩니다~
6. 결론 (3줄요약)
const x = 9007199254740993;- V8엔진은 정수를 저장하는 게 아니라 C++ 상의 double을 저장하기 때문에 53개 bit 이상으로 저장할 수 없다.
- 9007199254740993은 Parser에서
DoubleValue()가 호출되는 순간 fast_float 라이브러리가 binary64로 반올림 처리를 해버린다. - 연산 상의 오차는 아니고 IEEE-754의 규칙이 반영된 결과이다.
