
🔔 앞으로의 Reactive X 시리즈는 RxJava, RxKotlin 기준으로 작성됩니다
공식 문서를 참고하여 작성된 포스팅입니다.
지금까지 다룬 내용
우리는 Observable 의 개념에 대해 살펴보았고, Observable 로 만들 수 있는 다양한 데이터 스트림의 형태를 익혀보았다. 또한, Observable 데이터 스트림에 체이닝 가능한 편리한 연산자들의 용법에 대해서도 알아보았다.
하지만, Observable 은 한 가지 문제점이 잠재되어 있다. 바로, 배압현상이라는 것이다. 이번 포스팅에선 이 배압현상이 무엇이고 왜 일어나는 지에 관하여 익혀보며, 이를 해결할 수 있는 새로운 데이터 스트림에 관하여 알아보자.
배압 (Backpressure) 이란?
배압은, 데이터의 발행과 소비의 균형이 어긋날 때 발생하는 현상이다.
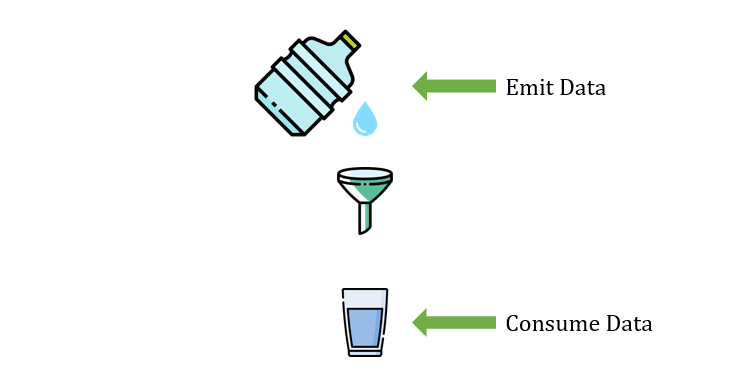
[이미지 출처] https://4z7l.github.io/2020/12/23/rxjava-7.html
예를 들어 어떤 Observable 데이터 스트림이 10,000개의 데이터를 0.1초마다 계속하여 발행하고, Observer (구독하는 주체) 는 이를 10초에 한 번씩만 소비한다면, 구독자가 소비를 하든말든 데이터가 스트림에 계속하여 쌓이게 된다. 즉, 소비 속도가 데이터 발행 속도를 못 따라가는 것이다.
Observable 은 데이터를 계속하여 발행함으로써 Observer 에 압력을 가하고 있는데, Observer 가 의도치 않게 메모리에 역-압력을 가하고 있는 것과 같다고 하여 'Backpressure' 라고 하는 것 같다.
아래는 10,000개의 데이터를 계속하여 발행하는 데이터 스트림을 만들고, 이를 0.1초에 한 번 소비하는 Observer 를 달아준 예제이다. 한 번 결과를 살펴보자.
fun main() {
Observable.range(1, 10000)
.doOnNext {
println("onNext() : $it")
}
.observeOn(Schedulers.io())
.subscribe {
println("Consumer : $it")
Thread.sleep(100)
}
Thread.sleep(100 * 10000)
}onNext() : 1
onNext() : 2
onNext() : 3
onNext() : 4
onNext() : 5
onNext() : 6
onNext() : 7
onNext() : 8
Consumer : 1
onNext() : 9
onNext() : 10
...
onNext() : 9996
onNext() : 9997
onNext() : 9998
onNext() : 9999
onNext() : 10000
Consumer : 2
Consumer : 3
Consumer : 4
Consumer : 5
Consumer : 6
...출력은 위와 같이 나오게 된다. 이 예제에서는 그렇게 크게 문제될 것은 없지만, Observer 가 데이터 하나를 소비할 때 Observable 은 이미 데이터를 모두 발행했다. 만약 계속 이런 식으로 데이터가 쌓이면, 결국 메모리가 오버플로우 되어버려서 OutOfMemoryException 에러가 발생하여 자칫 큰일날 수 있다. 이를 배압현상이라고 한다.
따라서 Reactive X 는, 이러한 Observable 의 문제점을 제어할 수 있는 특별한 데이터 스트림을 제공해준다.

너로 정했다, Flowable !
Flowable 은 Backpressure 현상을 제어할 수 있는 데이터 스트림이다. 개념 설명보단 먼저 예제 코드를 살펴보자. 위 예제 코드에서 데이터 스트림만 Flowable 로 바꿔서 실행해보자. 매우 신기한 결과를 볼 수 있을 것이다.
fun main() {
Flowable.range(1, 10000)
.doOnNext {
println("onNext() : $it")
}
.observeOn(Schedulers.io())
.subscribe {
println("Consumer : $it")
Thread.sleep(100)
}
Thread.sleep(100 * 10000)
}onNext() : 1
onNext() : 2
onNext() : 3
onNext() : 4
Consumer : 1
onNext() : 5
onNext() : 6
...
onNext() : 126
onNext() : 127
onNext() : 128
Consumer : 2
Consumer : 3
Consumer : 4
...
Consumer : 95
Consumer : 96
onNext() : 129
onNext() : 130
onNext() : 131
...너무 신기하게도, Observable 예제 코드와 다르게 onNext() 가 어느 정도 실행되고서는 멈추더니, Consumer 가 일정 시간동안 쌓인 데이터를 하나씩 소비를 하는 것을 발견할 수 있다. 그러고는 또 onNext() 가 어느 정도 실행되다가 또 멈추고, 이를 반복한다. 배압현상을 방지하기 위해 제어하는 모습이다!
이것이 바로 Flowable 의 순기능이다. Observable 와 다르게, Flowable 은 데이터 스트림에 쌓이는 데이터의 양을 제어할 수 있는 데이터 스트림이다.
그럼 걍 Flowable 만 쓰면 되는 거 아녜요?
절대 아니다. 심지어는 GitHub 공식 위키에서 이와 관련하여 정의해둔 목차가 있다.
공식 문서에서 지침한대로 목적에 맞게 적절히 선택하여 활용하자.
웬만하면 Observable 써라
- 1,000개 미만의 데이터가 발행되는 경우
- 즉,
OutOfMemoryException발생 확률이 거의 없는 경우
- 즉,
- GUI 프로그래밍 시 (마우스 이벤트, 터치 이벤트 등 →
debounce()등으로 제어 가능) - Java Stream API 를 사용하지 않는 경우
Flowable 을 사용하는 것보다 Observable 을 사용하는 것이 오버헤드가 적기 때문에, 만약 Observable 을 사용해도 되는 조건이라면 무조건 기본적으로 Observable 을 사용하라고 권장한다.
웬만하지 않으면 (?) Flowable 써라
- 데이터가 10,000개 이상 처리되는 경우
- 디스크에서 파일을 읽어들이는 경우
- JDBC 를 통해 DB 쿼리 결과를 가져오는 경우
- 네트워크 I/O 작업을 하는 경우
- 다수의, 혹은 Non-Blocking 방식의 API 를 요청하는 경우
즉, 한정적인 실행환경에서 방대한 작업량을 문제없이 수행해야 할 때 Flowable 을 사용하는 것이다.
이번 포스팅에선 Observable 데이터 스트림에서 발생할 수 있는 배압 현상에 관해 알아보았고, 이를 제어할 수 있는 데이터 스트림인 Flowable 에 대해 익혀보았다.
Flowable 에서도 배압을 제어하지 못할 수 있는 예외상황이 존재한다. 다음 포스팅에선 이러한 상황에 대해 알아보고, 이를 제어할 수 있는 다양한 전략에 관해 살펴보자.
