
파이썬이라고 뭉뚱그리긴 하지만 배울 게 많음
데이터사이언스는 하나하나 배우면서 따라가는게 아니라 실습하면서 하는 것
프로젝트를 완성해 가는 형태로 진행
- 프로젝트가 진행되는 과정을 중시
- 이론: 결과, 흐름 위주 / 실습: 문제는 효율성.
chapter 01. 파이썬 환경설정
1.1 miniconda 설치
1.2 conda 가상환경
Analysis Seoul CCTV
python, Pandas, Matplotlib한번에 공부하기 좋은 실습
-> 인구수 별 CCTV 배치 시각화, 서울시 전체 경향 시각화
- 목표
[Python, Pandas]
1. 서울시 구별 CCTV 현황 데이터 확보
- 구글 검색 - 데이터다운로드- data폴더에 저장
- 인구 현황 데이터 확보
- 서울열린데이터광장 - 오픈api서비스 - 구별인구통계 - 엑셀파일로 저장
- CCTV 데이터와 인구 현황 데이터 합치기
- 데이터를 정리하고 정렬하기
[Matplotlib]
5. 그래프를 그릴 수 있는 능력
[Regression using Numpy]
6. 전체적인 경향을 파악할 수 있는 능력
[Insight and Visualization]
7. 그 경향에서 벗어난 데이터를 강조하는 능력
- Pandas에서 엑셀 및 텍스트 파일 읽기
-
pandas(강력한 데이터 핸들링 성능제공, 스테로이드 맞은 엑셀)로
CSV(comma seperate value), 엑셀파일 읽기
많은 모듈이 만들어지고 있음. -
import(모듈을 사용하겠다) pandas as(-라는 이름으로 부르겠다) pd
-
from MODULE import function
: 모듈에 포함된 function이라는 함수만 사용하겠다 -
통상 csv는 띄어쓰기로 구분되니 그냥 read_csv 명령으로 읽기
-
긴 파일명을 끝까지 입력하지말고 적당한 곳에서 tab키를 눌러보자
-
한글은 인코딩 설정이 필수 -> encoding="utf-8"
.head() : 앞부분 5개만 보여달라는 것
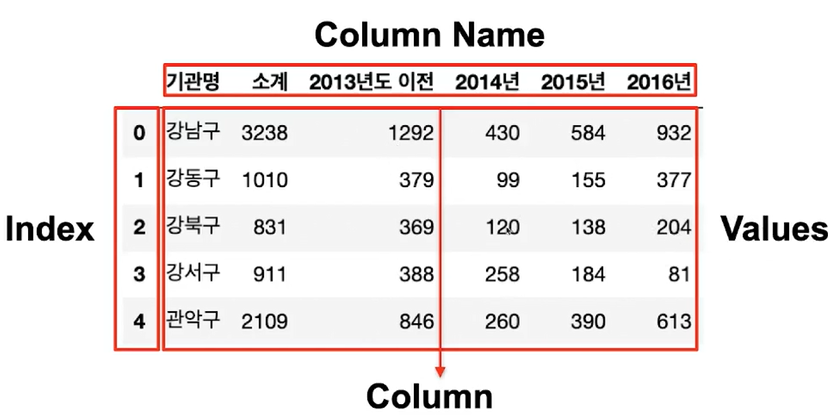
.column[] : 인덱스 조회
.rename(columns={}, inplace=True) : 컬럼 이름을 바꿈
, header = 2 : 위에 두줄의 행 빼고 보여달라
, usecols= " , ," : 필요한 column 지정
- pandas basic
-
pandas는 통상 pd로 import,
수치해석적 함수가 많은 numpy는 통상 np로 import -
pandas의 데이터형을 구성하는 기본은 Series
-
pd.date_range = 날짜(시간)을 이용가능
-
pandas에서 가장 많이 사용하는 데이텨형은 pd.DataFrame
index와 columns를 지정하면 된다 -
조회
.index
.columns
.values -
기본정보 확인
.info() : DataFrame의 기본정보, 각 컬럼의 크기와 데이터 형태 등
.describe() : DataFrame의 통계적 기본정보 -
데이터 정렬
.sort_values
예) df.sort_values(by="B", ascending=False) : B 컬럼 기준으로, 내림차순 정렬 -
특정 컬럼만 읽기
df["A"]
df[n:m] : n부터 m-1까지 : 인덱스 번호
df["" : ""] : 인덱스 이름
df.loc[: , ["A", "B"] : 위치지정. 행, 열
-> [ : , ] = 모든 행
df.iloc : iloc 옵션을 이용해서 번호로만 접근
-> df.iloc[3:5, 0:2] = 3~4행, 0~1 column
df : -
특정 요소가 있는지 확인
df["E"].isin(["two", "four"]) -
특정 요소가 있는 행만 선택
df[df["E"].isin(["two", "four"])] -
특정 컬럼 제거
del df["E"] -
각 컬럼 누적합
df.apply(np.cumsum)
jupiter notebook
B: 줄 추가
M: 마크다운으로 입력
shift + enter : 문서작업완료
A: 상단에 셀 추가
CCTV데이터 훑어보기
.drop([0]) : 첫행(0번)의 합계 데이터는 필요없으니 지움 = 행을 지우는 명령
.unique() : 여러번 등장하는 걸 한 번만 보는 것
두 데이터 합치기
pandas 데이터 merge 이용해서 병합하기
pd.merge(left, right, on="key")
merge명령을 쓰는데 l과 r을 병합해라. key를 기준으로
, how="left" = left 값을 다 살아있게 함
, how="outer" = 모든 값을 다 살아있게 함
, how="inner" = 공통분모만
.set_index("") : index로 잡아줌.
상관관계: 한 쪽이 증가하면, 다른 쪽이 변화하는가?(증가 혹은 감소)
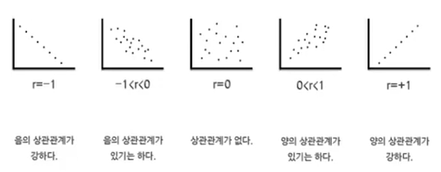
상관관계가 있다고 인과관계가 있는 건 아님
.corr() : 상관관계
상관관계 0.2 이상이어야 조금 상관관계가 있는 것
Scatter 데이터 경향파악
numpy를 이용한 1차 직선 만들기
[절차]
- np.polyfit (y절편과 기울기)
: 직선을 구성하기 위한 계수 계산 - np.poly1d (방정식 구성 함수)
: polyfit으로 찾은 계수로 python에서 사용할 함수를 만들어줌
import numpy as np
# x축, y축, 1차로 만들어달라
fpl = np.polyfit(data_result["인구수"], data_result["소계"], 1)
fpl
-->
array([1.1111558e-03, 1.065157453+03])
fl = np.polyld(fpl) = 직선
- polyfit에서 찾은 계수를 넣어서 함수 완성
- 변수가 함수가 됨. 어떤 값 넣으면 결과값 튀어나옴
fl(400000)
- 인구 400000인 구에서 서울시의 전체 경향에 맞는 적당한 cctv 수를 알고 싶을 때
fx=np.linspace(100000, 700000, 100)
-
경향선을 그리기 위해 x데이터 생성
-
np.linspace(a, b, n): a부터 b까지 n개의 등간격 데이터 생성
= 10만부터 70만 까지 사이 중에서 100개의 데이터를 등간격으로 만들라는 것
데이터의 경향을 직선으로 !
표현하기
경향에서 벗어난 데이터 강조하기
data_result['오차'] = data_result['소계'] - f1(data_result['인구수'])
- 경향(trend)과의 오차를 만들자
- 경향은 f1함수에 해당 인구를 입력
f1(data_result['인구수']) - 현재값: data_result['소계']
# 실제값 - 예측값
data_result['오차'] = data_result['소계'] - f1(data_result['인구수'])
# 경향과 비교해서 데이터의 오차가 너무 나는 데이터를 계산
#경향대비 cctv를 많이 가진 구; 오름차순
df_sort_f = data_result.sort_values(by="오차", ascending=False)
#경향대비 cctv를 적게 가진 구; 내림차순
df_sort_t = data_result.sort_values(by="오차", ascending=True)--
색상지정
from matploitlib.colors import ListedColotmap #지정한 걸로 사용가능
#color map을 사용자 정의 user define으로 세팅
color_step = ["#333333", ... , ]
my_cmap = ListedColormap(color_step)--
오차가 큰 데이터 아래 위로 5개씩만 특별히 마커 옆에 구 이름 명시. 점에 글씨 가려지지 않도록 마조금 떨어트림
for n in range(5):
plt.text(df_sort_f['인구수'][n]*1.02, df_sort_f['소계'][n]*0.98, df_sort_f.index[n], fontsize=15)