주요 학습내용
예제를 통한 자료구조 문제풀이
1. 리스트
2. 튜플
3. 딕셔너리
I. 리스트(List)
예제 1)_ append()

userInput = int(input('1보다 큰 정수 입력: '))
listA = []
isPrimeList = []
# 약수
for i in range(1, userInput + 1):
if userInput % i == 0:
listA.append(i)
# 소수(반복문 필요)
for number in range(2, userInput + 1):
flag = True
for n in range(2, number):
if number % n == 0:
flag = False
if flag:
isPrimeList.append(number)
print(f'약수: {listA}')
print(f'소수: {isPrimeList}')출력 결과 :

예제 2)_append() + random 값

# 난수 생성 필요 => import random
import random
randList = random.sample(range(1, 101), 10)
evenList = []
oddList = []
for value in randList:
if value % 2 == 0:
evenList.append(value)출력 결과 :

예제 3)_for문
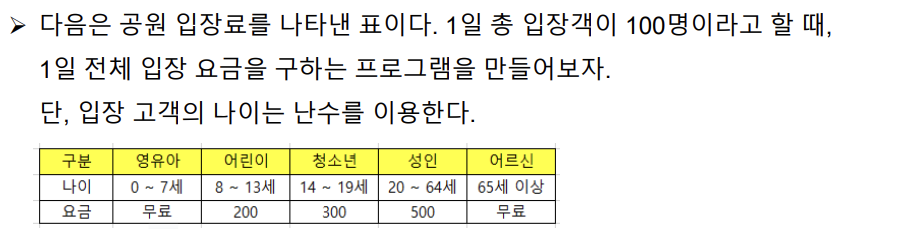
# 1일 총 입장객 = 100명, 1일 총 입장요금 구하기
import random
visitors = []
for i in range(100):
visitors.append(random.randint(1, 100))
print(visitors)
group1 = 0; group2 = 0; group3 = 0; group4 = 0; group5 = 0
for age in visitors:
if age >= 0 and age <= 7:
group1 += 1
elif age > 8 and age <= 13:
group2 += 1
elif age > 14 and age <= 19:
group3 += 1
elif age > 20 and age <= 64:
group4 += 1
elif age > 65:
group5 += 1
price1 = 0 * group1
price2 = 200 * group2
price3 = 300 * group3
price4 = 500 * group4
price5 = 0 * group5
sumPrice = price1 + price2 + price3 + price4 + price5
print('-'* 50)
print(f'영유아 \t: {group1}명\t: {format(price1, ',')}원')
print(f'어린이 \t: {group2}명\t: {format(price2, ',')}원')
print(f'청소년 \t: {group3}명\t: {format(price3, ',')}원')
print(f'성인 \t: {group4}명\t: {format(price4, ',')}원')
print(f'어르신 \t: {group5}명\t: {format(price5, ',')}원')
print('-'* 50)
print(f'1일 요금 총합계: {format(sumPrice, ',')}원')출력 결과 :
예제 4)_while문

numbers = [2, 22, 7, 8, 9, 2, 7, 3, 5, 2, 7, 1, 3]
print(f'numbers: {numbers}')
idx = 0
while True:
if idx >= len(numbers):
break
# break 후 반복문 빠져나옴 => idx + 1
if numbers.count(numbers[idx]) >= 2:
# numbers의 해당 idx의 해당하는 숫자의 개수 >= 2:
numbers.remove(numbers[idx])
# numbers.pop(idx)도 사용 가능
continue
# if count >= 2, idx + 1 하지말고 지운 후 다음 데이터부터 다시 check
# idx = len(numbers)-1 => 해당 idx까지 반복하여 count
idx += 1
# # pop() : 마지막 삭제
# # pop(idx) : 해당 인덱스 값 삭제
# # remove() : 특정 아이템 삭제 가능
# # remove()는 한 개의 아이템만 삭제 가능하므로,
# if 삭제 데이터 >= 2개, while 문 사용해야 함출력 결과 :

예제 5)_for문 + 순열

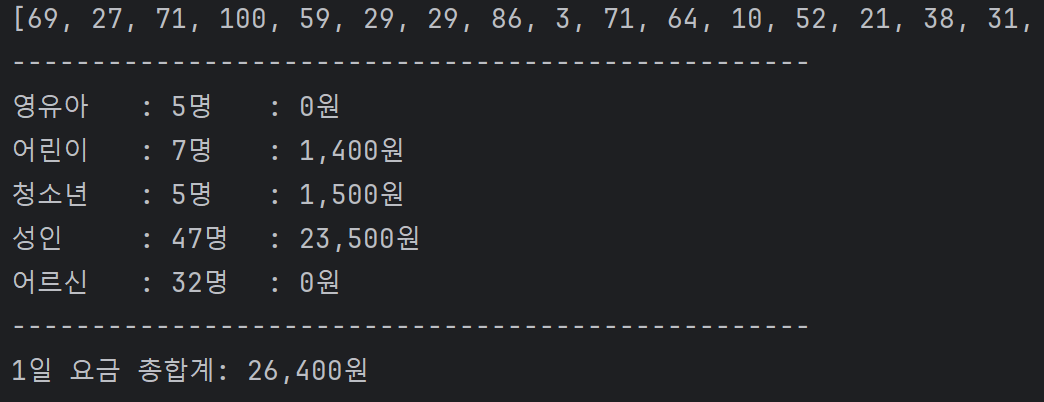
# 4개의 숫자 중 서로 다른 숫자 3개를 선택해서 만들 수 있는 모든 경우의 수
# 방법 1)
result1 = []
for n1 in numbers:
for n2 in numbers:
if n1 == n2: continue
for n3 in numbers:
if n1 == n3 or n2 == n3: continue
result.append([n1, n2, n3])
print(f'result: {result}')
print(f'개수: {len(result)}개')
# 방법 2)
from itertools import permutations
print(list(permutations(numbers,3)))
print(len(list(permutations(numbers, 3))))출력 결과 :
II. 튜플(Tuple)
예제 1)_for문 + append()

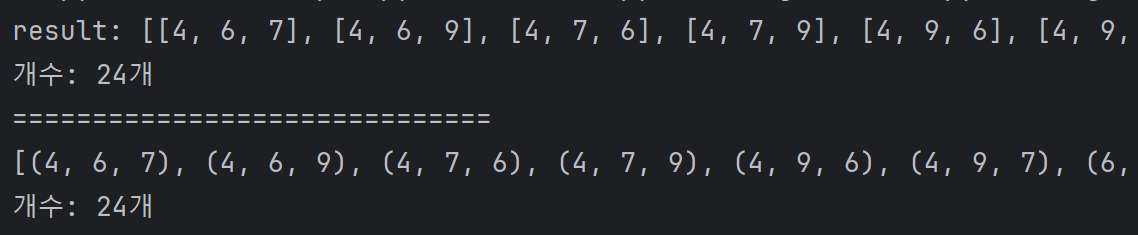
# 졸업 시 4.0 이상의 학점을 받기 위해 받아야하는 4학년 1, 2학기의 최소 학점
scores = ((3.7, 4.2),
(2.9, 4.3),
(4.1, 4.2))
total = 0
for s1 in scores: # ()의 값
for s2 in s1: # (())의 값
total += s2 # 각 점수 +
avg = total / 6
print('3학년 총학점: %.1f'%total)
print('3학년 평균: %.1f'%avg)
# 타겟 학점 setting
grade4TargetScore = (4.0 * 8) - (total)
semester = round(grade4TargetScore/2, 1)
print('-' * 70)
print('4학년 목표 총학점: %.1f'%grade4TargetScore)
print('4학년 한 학기 최소 학점: %.1f'%semester)
print('-' * 70)
scores = list(scores)
scores.append((semester, semester))
scores = tuple(scores)
print(f'scores: {scores}')출력 결과 :
-
예제 2)_for문 & while문

1) 강의 수강 전 내가 했던 방법
- commonList를 추가로 생성해준 뒤 해당 리스트에 append()
# 내가 한 방법(while문) tuple1 = (1, 3, 2, 6, 12, 5, 7, 8) tuple2 = (0, 5, 2, 9, 8, 6, 17, 3) tuple3 = tuple1 + tuple2 print(tuple3) tuple3 = list(tuple3) commonList = [] # 중복항목 제거 while문 사용하여 반복문 실행 idx = 0 while True: if idx >= len(tuple3): break if tuple3.count(tuple3[idx]) >= 2: tuple3.remove(tuple3[idx]) idx += 1 tuple3.sort() for n1 in tuple1: if n1 in tuple2: commonList.append(n1) commonList.sort() commonList = tuple(commonList) tuple3 = tuple(tuple3) print(f'합집합(중복X)\t: {tuple3}') print(f'교집합 \t: {commonList}')출력 결과 :

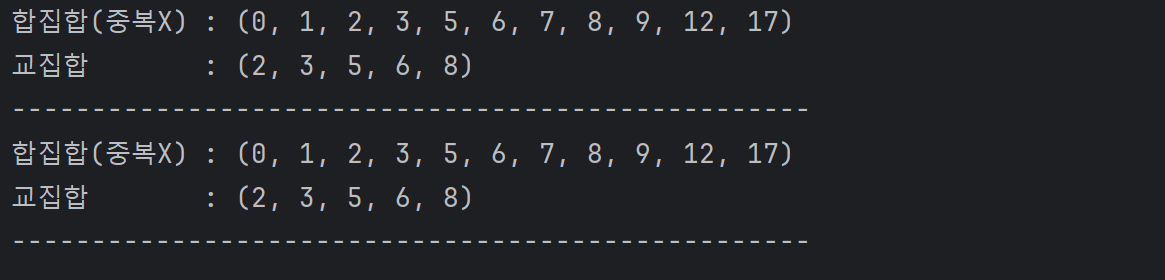
2) 강의에서 다룬 내용
1) for문 사용tuple1 = (1, 3, 2, 6, 12, 5, 7, 8) tuple2 = (0, 5, 2, 9, 8, 6, 17, 3) # 강의 자료 for문 tempHap = list(tuple1) tempGyo = list() for n in tuple2: if n not in tempHap: tempHap.append(n) else: tempGyo.append(n) tempHap.sort() tempGyo.sort() tempHap = tuple(tempHap) tempGyo = tuple(tempGyo) print(f'합집합(중복X)\t: {tempHap}') print(f'교집합 \t: {tempGyo}') print('-'*50) # 강의 자료 while문 tempHap = tuple1 + tuple2 tempGyo = list() tempHap = list(tempHap) idx = 0 while True: if idx >= len(tempHap): break if tempHap.count(tempHap[idx]) >= 2: tempGyo.append(tempHap[idx]) tempHap.remove(tempHap[idx]) continue idx += 1 tempHap.sort() tempGyo.sort() tempHap = tuple(tempHap) tempGyo = tuple(tempGyo) print(f'합집합(중복X)\t: {tempHap}') print(f'교집합 \t: {tempGyo}') print('-'*50)출력 결과 :
-
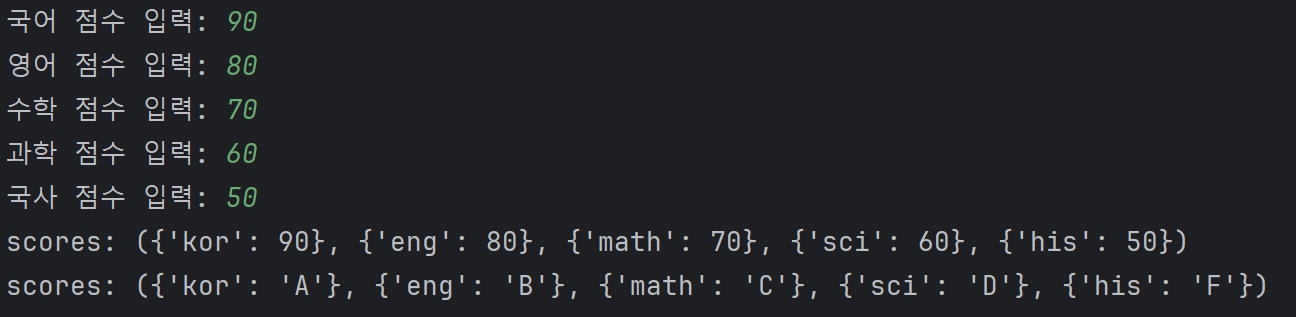
예제 3)_수정(자료구조 변경 후 진행)

# 시험 점수 입력 후, 튜플에 저장하고 과목별 학점 출력
kor = int(input('국어 점수 입력: '))
eng = int(input('영어 점수 입력: '))
math = int(input('수학 점수 입력: '))
sci = int(input('과학 점수 입력: '))
his = int(input('국사 점수 입력: '))
scores = ({'kor': kor},
{'eng': eng},
{'math': math},
{'sci': sci},
{'his': his})
print(f'scores: {scores}')
for item in scores:
for key in item.keys():
if item[key] >= 90: item[key] = 'A'
elif item[key] >= 80: item[key] = 'B'
elif item[key] >= 70: item[key] = 'C'
elif item[key] >= 60: item[key] = 'D'
elif item[key] < 60: item[key] = 'F'
# 튜플은 수정이 안되지만, 튜플 안에있는 딕셔너리는 수정 가능
print(f'scores: {scores}')출력 결과 :
예제 4)_오름차순 & 내림차순

# value 하나씩 비교해주며 인덱스 이동
fruits = ({'수박': 8},
{'포도': 13},
{'참외': 12},
{'사과': 17},
{'자두': 19},
{'자몽': 15})
fruits = list(fruits)
# 관리하고자하는 인덱스 값 생성
cIdx = 0; nIdx = 1; eIdx = len(fruits) - 1
flag = True
while flag:
curDic = fruits[cIdx] # 반복하는 동안 변동 x
nextDic = fruits[nIdx] # cIdx을 기준으로 한칸씩 이동
curDicCnt = list(curDic.values())[0]
nextDicCnt = list(nextDic.values())[0]
if nextDicCnt < curDicCnt:
fruits.insert(cIdx, fruits.pop(nIdx))
# 잘라내서 cIdx자리에 붙여넣기(자리바꿈)
nIdx = cIdx + 1 # 처음에는 cIdx = 0이므로 + 1
continue # 계속 반복
# cIdx가 계속 작은 경우, 영원히 반복 x
nIdx += 1
if nIdx > eIdx:
cIdx += 1
nIdx = cIdx + 1
if cIdx == 5:
flag = False
print(f'오름차순: {tuple(fruits)}')
# 내림차순은 역으로 계산
# 관리하고자하는 인덱스 값 생성
cIdxR = 0; nIdxR = 1; eIdxR = len(fruits) - 1
flag = True
while flag:
curDicR = fruits[cIdxR] # 반복하는 동안 변동 x
nextDicR = fruits[nIdxR] # cIdx을 기준으로 한칸씩 이동
curDicCntR = list(curDicR.values())[0]
nextDicCntR = list(nextDicR.values())[0]
if nextDicCntR > curDicCntR:
fruits.insert(cIdxR, fruits.pop(nIdxR))
# 잘라내서 cIdx자리에 붙여넣기(자리바꿈)
nIdxR = cIdxR + 1 # 처음에는 cIdx = 0이므로 + 1
continue # 계속 반복
# cIdx가 계속 작은 경우, 영원히 반복 x
nIdxR += 1
if nIdxR > eIdxR:
cIdxR += 1
nIdxR = cIdxR + 1
if cIdx == 5:
flag = False
print('내림차순: {}'.format(tuple(fruits)))출력 결과 :
- 해당 예제가 자료구조 예제들을 통틀어 가장 시간을 많이 들였던 것 같다.
value만 따로 빼서 비교는 하였지만, 인덱스를 어떻게 넣어야하는지에 대해 고민만 계속 하다 결국 강의 자료를 통해 해답을 얻을 수 있었다.- 결론적으로는 인덱스를 기준으로 while문을 통해 값을 반복 비교를 하며 순위를 매기는 방식이였다.(이전 학급인원 최대값, 최소값을 구하는 방식과 비슷했다)
- 결론을 알고나면 어렵지 않은 문제였지만, 인덱스를 기준으로 while문을 생성한다는 것이 바로 직관적으로 머리에 떠오르지 않은 것을 보며 더 많이 연습해야겠다고 생각했다.

예제 5)_최소값, 최대값, 평균, 편차 구하기

# 전체/평균/학생수 MAX/학생수 MIN/편차 출력
students = ({'cls01': 18},
{'cls02': 21},
{'cls03': 20},
{'cls04': 19},
{'cls05': 22},
{'cls06': 20},
{'cls07': 23},
{'cls08': 17})
students = list(students)
total = 0
minClass = 0; maxClass = 0
minClsCnt = 0; maxClsCnt = 0
diff = []
for item in students:
for key in item.keys():
total += item[key]
avg = round(total / len(students), 1)
if minClsCnt == 0 or minClsCnt > item[key]:
minClsCnt = item[key]
minClass = key
if maxClsCnt == 0 or maxClsCnt < item[key]:
maxClsCnt = item[key]
maxClass = key
for item in students:
for key in item.keys():
diff.append({key: item[key] - avg})
print('전체 학생 수: {}명'.format(total))
print('평균 학생 수: %.1f명'%avg)
print('학생 후가 가장 적은 학급: {}({}명)'.format(minClass, minClsCnt))
print('학생 후가 가장 많은 학급: {}({}명)'.format(maxClass, maxClsCnt))
print('학급별 학생 편차: {}'.format(diff))출력 결과 :

III. 딕셔너리(Dictionary)
예제 1)_아이템 존재유무 확인(in/not in)

# 실습 로그인 프로그램 생성
members = {'aaaa': '111111',
'bbbb': '222222',
'cccc': '333333',
'dddd': '444444',
'eeee': '555555',
'ffff': '666666',
'gggg': '777777',
'hhhh': '888888',
'iiii': '999999',
'jjjj': '101010'}
userInputId = input('ID 입력: ')
userInputPw = input('PW 입력: ')
if userInputId in members: # 키값을 기준으로 비교하게 됨
if userInputPw == members[userInputId]:
print('로그인 성공')
if userInputPw != members[userInputId]:
print('비밀번호 확인!!')
else:
print('아이디 확인!!')출력 결과 :



예제 2)_자료구조 변경 + append()

# 1 ~ 10 각각의 정수에 대한 약수를 저장하는 딕셔너리 만들고 출력
numberdic = {}
for i in range(2, 11):
tempList = []
for n in range(1, i + 1):
if i % n == 0:
tempList.append(n) # 약수이면 tempList에 저장
numberdic[n] = tempList # 키값 : n => n 에 해당하는 약수 ~
# value : tempList
print(numberdic)출력 결과 :

예제 3)_value 수정(replace())

# 비속어 -> 표준어로 변경
# replace() 사용
words = {'꺼지다': '가다',
'쩔다': '엄청나다',
'짭새': '경찰관',
'꼽사리': '중간에 낀 사람',
'먹튀': '먹고 도망',
'지린다': '겁을 먹다',
'쪼개다': '웃다',
'뒷담 까다': '험담하다'}
txt = '강도는 서로 쪼개다, 짭새를 보고 빠르게 따돌리며 먹튀했다.'
print(txt)
print('-'*20+ '원문'+'-'*20)
keys = list(words.keys())
for key in keys:
if key in txt: # 키 값 기준으로 txt에 해당 단어 있는지 확인
print('key: {}'.format(key))
print('words[{}]: {}'.format(key, words[key]))
txt = txt.replace(key, words[key]) # 다시 할당
print('-'*20+ '수정후'+'-'*20)
print(txt)출력 결과 :

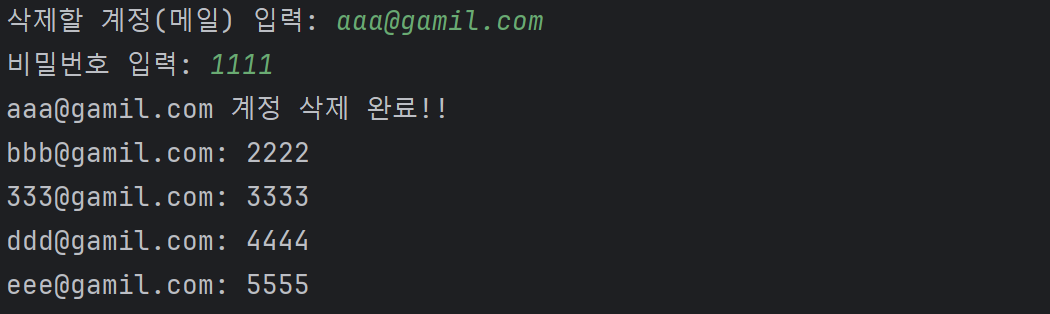
예제 4)_아이템 추가 및 삭제(del)

# 실습 1
# 딕셔너리 사용하여 5명의 회원을 가입 받고, 전체 회원 정보를 출력하는 프로그램 생성
members = {}
n = 1
while n < 6:
main = input('메일 입력: ')
pw = input('비번 입력: ')
if main in members:
print('이미 사용 중인 메일 계정입니다.')
continue # 다시 처음으로 돌아감
else:
members[main] = pw
n += 1
# key값 이용하여 출력
for key in members:
print(f'{key}: {members[key]}')
# 특정 회원 계정 삭제
while True:
delMail = input('삭제할 계정(메일) 입력: ')
if delMail in members:
delPw = input('비밀번호 입력: ')
if delPw == members[delMail]:
del members[delMail]
print(f'{delMail} 계정 삭제 완료!!')
break
else:
print('비밀번호 확인 요망')
else:
print('계정 확인 요망')
# key값 이용하여 출력
for key in members:
print(f'{key}: {members[key]}')출력 결과 :
(아이디/비밀번호를 잘못 입력했을 시)
출력 결과 :
예제 5)_자료구조의 효율적 선택
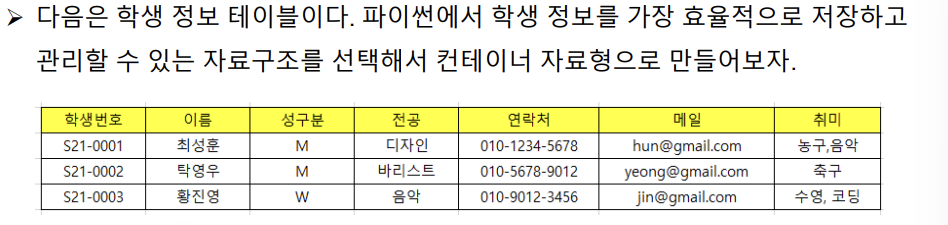
# 학생 정보 테이블 컨테이너 자료형으로 만들기
# 학번 같이 고유항목이 있고 해당 값을 기준으로 나머지 값들이 출력되는 경우,
# Dic {} 사용하는 것이 가장 효율적
# 키 값 기준으로 dic 안에 dic(다중)
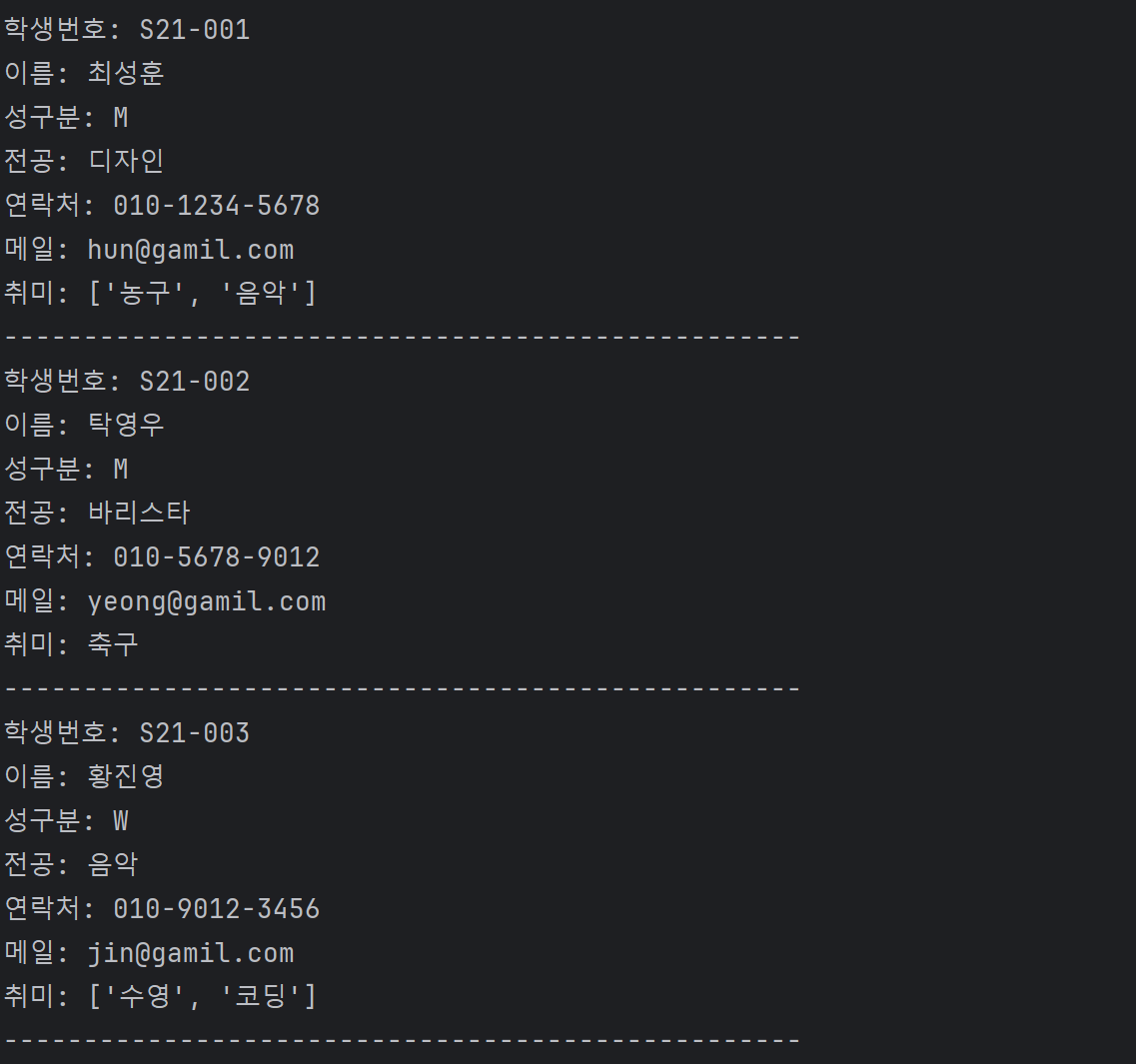
students = {'S21-001': {'이름': '최성훈',
'성구분': 'M',
'전공': '디자인',
'연락처': '010-1234-5678',
'메일': 'hun@gamil.com',
'취미': ['농구', '음악']},
'S21-002': {'이름': '탁영우',
'성구분': 'M',
'전공': '바리스타',
'연락처': '010-5678-9012',
'메일': 'yeong@gamil.com',
'취미': '축구'},
'S21-003': {'이름': '황진영',
'성구분': 'W',
'전공': '음악',
'연락처': '010-9012-3456',
'메일': 'jin@gamil.com',
'취미': ['수영', '코딩']}} # 항목 여러개이므로 list로 관리
for k1 in students.keys():
print('-'*50)
print('학생번호: {}'.format(k1)) # students의 키 값이니까 학번
student = students[k1] # 학생 한명당 또 하나의 dic
for k2 in student.keys():
print('{}: {}'.format(k2, student[k2]))
# 특정 학생 정보 조회
print('-'*50)
studentNo = input('조회 대상 학생 번호 입력: ')
print('{}: {}'.format(studentNo, students[studentNo]))출력 결과 :
출력 결과 :


할 거면 제대로 하자