
주요 학습내용
1. 통계란
통계학(統計學, 영어: statistics)은 산술적 방법을 기초로 하여, 주로 다량의 데이터를 관찰하고 정리 및 분석하는 방법을 연구하는 수학의 한 분야이다. 근대 과학으로서의 통계학은 19세기 중반 벨기에의 케틀레가 독일의 "국상학(國狀學, Staatenkunde, 넓은 의미의 국가학)"과 영국의 "정치 산술(政治算術, Political Arithmetic, 정치 사회에 대한 수량적 연구 방법)"을 자연과학의 "확률 이론"과 결합하여, 수립한 학문에서 발전되었다
[출처 위키백과]

2. 용어
- 평균
- 중앙값(median) : 가운데 위치하는 값
- 최빈값(mode)

- 범위
- 사분위수(quartile): 전체 데이터를 오름차순으로 정렬하여 4등분을 하였을 때, 첫 번째를 제 1사분위수(Q1)
- 백분위수(percentile)
- 분산(variance) : 데이터의 분포가 얼마나 흩어져 있는지를 알 수 있는 측도
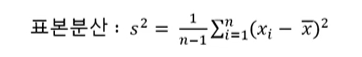
- 표준 편차(standard deviation) : 분산의 제곱근
- 변동계수(Coefficient of Variation: CV) : 평균이 다른 두개 이상의 그룹의 표준편차를 비교할 때 사용
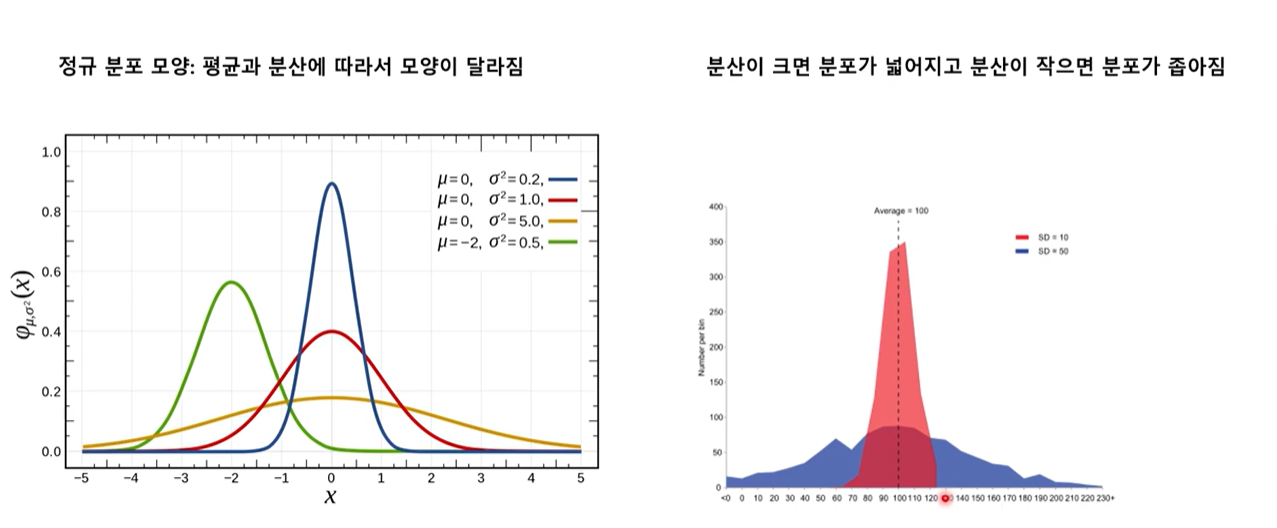
- 왜도(skew) : 자료의 분포가 얼마나 비대칭적인지 표현하는 지표
- 0: 좌우 대칭
- 0에서 클수록 : 우측꼬리 길어짐
- 0에서 작을수록 : 좌측꼬리 길어짐
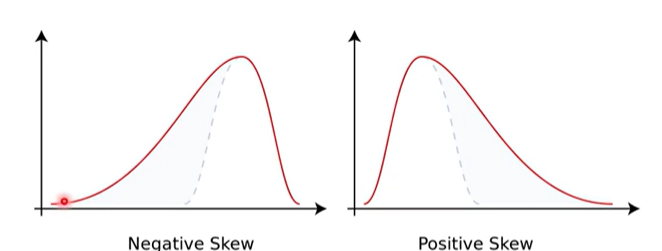
-
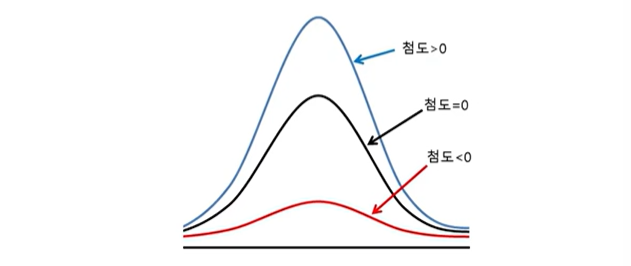
첨도(kurtosis) : 확률분포의 꼬리가 두꺼운 정도를 나타내는 척도
- 3에 가까우면 : 정규분포에 가까움
- 3보다 작을 경우 : 꼬리가 얇은 분포
- 3보다 큰 양수 : 꼬리가 두꺼운 분포
3. 확률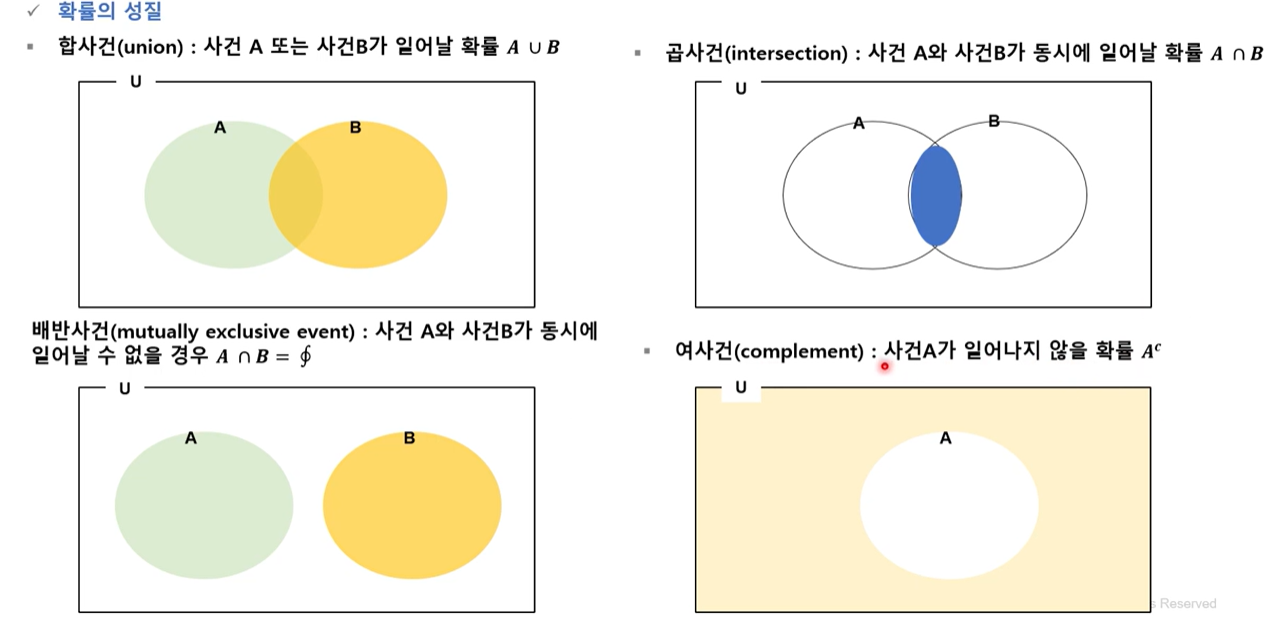

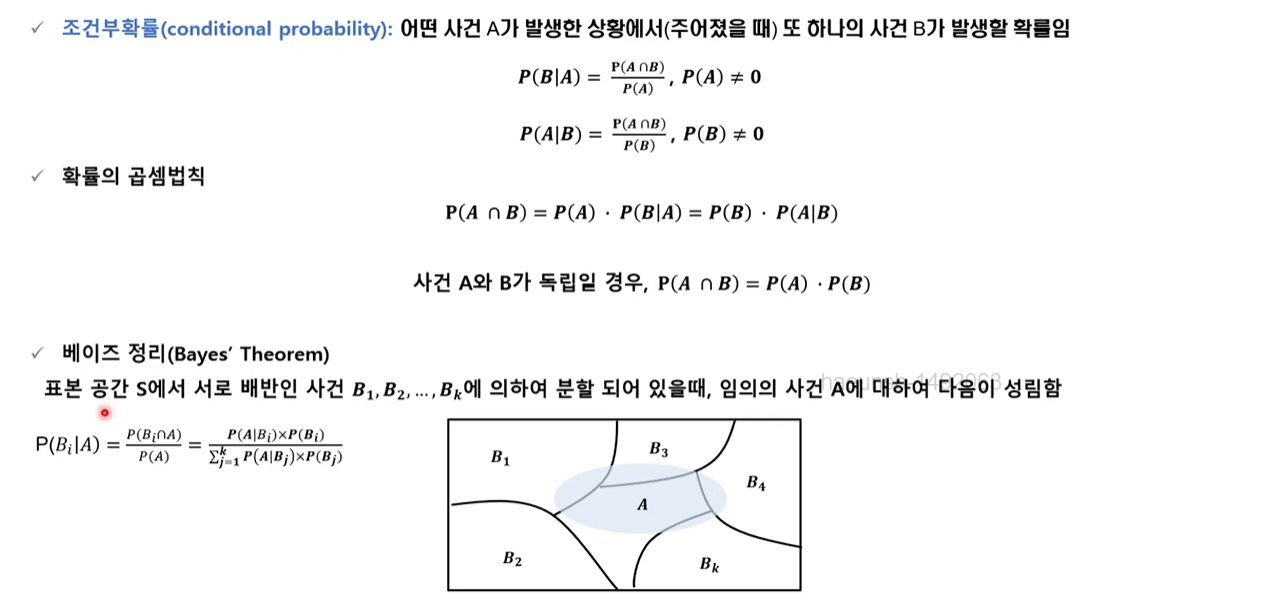
-
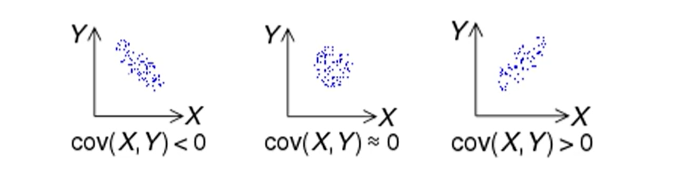
공분산
- 양의 공분산: 하나의 값이 상승할 때 다른 값도 상승
- 음의 공분산: 하나의 값이 상승할 때 하락ㅋ
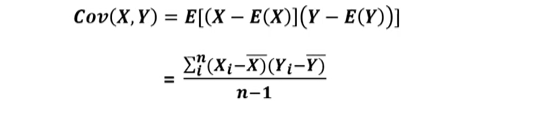
-
분산의 성질

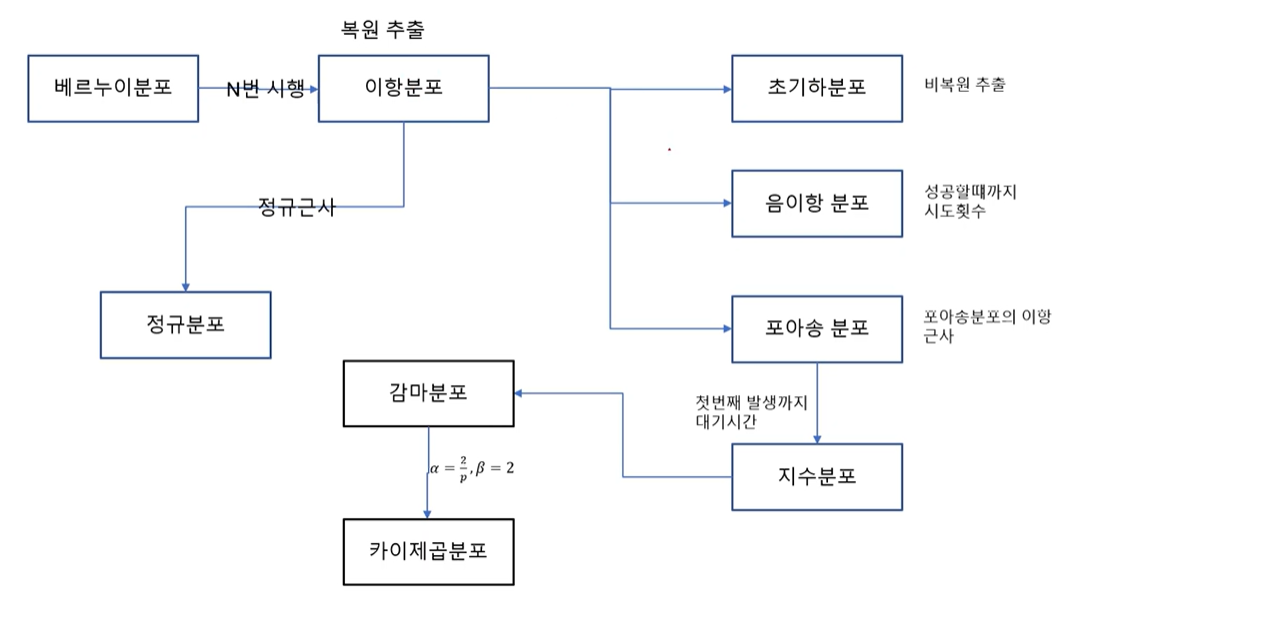
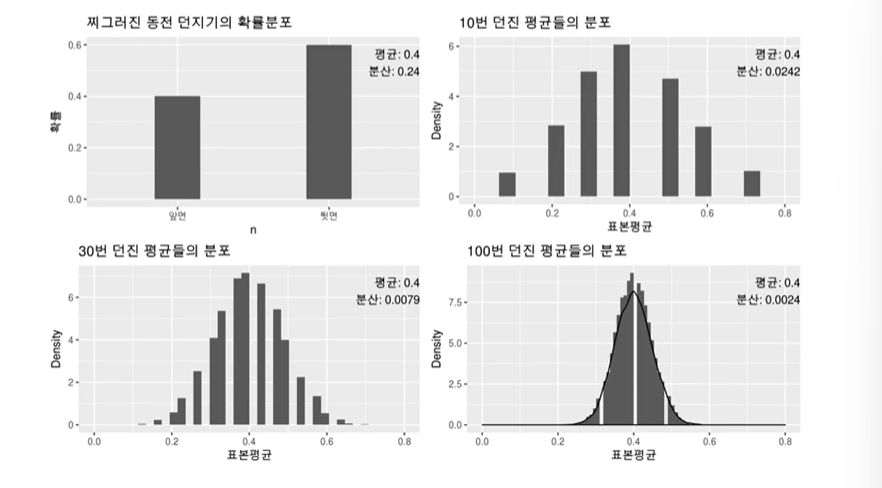
4. 확률분포_이산형확률분포(유한)
확률분포(probability distribution)
확률 변수 x가 취할 수 있는 모든 값과 그 값이 나타날 확률을 표현한 함수
* 이항분포 중요
4-1) 이산형 균등 분포(discrete uniform distribution)
X ~ U(a,b) 표현
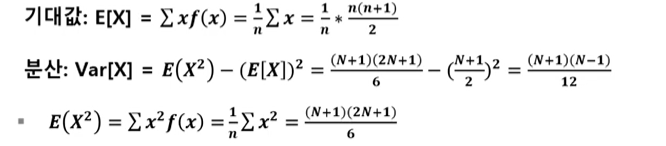
- 확률 변수 x가 유한개이고, 모든 확률 변수에 대하여 균일한 확률을 갖는 분포
- e.g) 주사위를 한번 굴려서 나오는 숫자를 확률 변수 x라고 하면, 확률 변수 x는 모두 1/6
4-2) 베르누이 시행(Bernoulli trial)
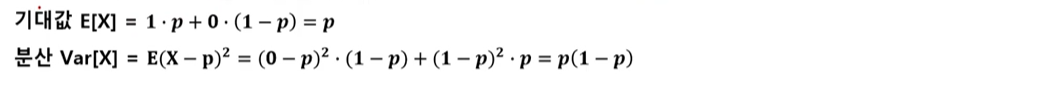
- 각 시행의 결과가 성공/실패 두가지 결과만 존재하는 시행
- 베르누이 시행에서 성공이 1, 실패가 0의 값을 갖을 때 확률 변수 x의 분포를 베르누이분포라고 함
- e.g) 빨간 공 3개, 파란공 7개가 들어있는 주머니에서 공 하나를 뽑을 때, 파란공이면 성공, 빨간공이면 실패(공 한번 꺼내면 다시 넣기 x)
4-3) 이항분포(Binomial distribution)


- 연속적인 베르누이 시행을 거쳐 나타나는 확률 분포
- 서로 독립인 베르누이 시행을 n번 반복해서 실행했을 때, 성공한 횟수 x의 확률 분포
- e.g) 빨간 공 3개, 파란공 7개가 들어있는 주머니에서 공 하나를 뽑을 때, 파란공이면 성공, 빨간공이면 실패(공 한번 꺼내면 다시 넣기 O)
- e.g) 축구선수의 패널티킥 성공률이 80%일 떄, 10번의 기회에서 성공횟우와 그 확률 구하기
4-4) 포아송 분포(Poisson distribution)
~
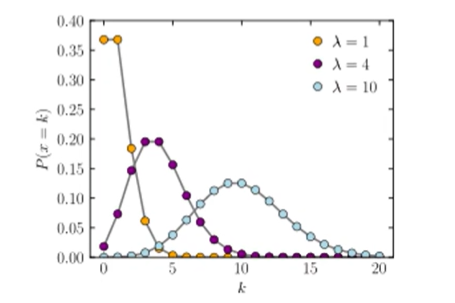
- 어느 희귀한 사건이 어떤 일정한 시간대에 특정한 사건이 발생할 확률 분포
- e.g) 야구장에서 파울볼을 잡을 횟수, 버스 정류장에서 특정버스가 5분 이내에 도착한 횟수, 1년간 지구에 1미터 이상의 운석이 떨어지는 수 등
- 포아송 분포의 조건
1) 어떤 단위 구간(예, 1일) 동안 이를 더 짧은 작은 단위의 구간(예, 1시간)로 나눌 수 있고, 이러한 더 짧은 단위구간 중에 어떤 사건이 발생할 확률은 전체 척도 중에서 항상 일정
2) 두개 이상의 사건이 동시에 발생할 확률은 0에 가까움
3) 어떤 단위 구간의 사건의 발생은 다른 단위구간의 발생으로부터 독립적임
4) 특정 구간에서의 사건 발생확률은 그 구간의 크기에 비례함
5) 포아송분포 확률 변수의 기댓값과 분산은 모두 임
4-5) 기하분포(geometric distribution)
~

- 어떤 실험에서 처음 성공이 발생하기 까지 시도한 횟수 x의 분포, 이때 각 시도는 베르누이 시행을 따름
- e.g) 축구선수 A의 필드골 성공 확률이 30%일 때, 5번째 슛팅에서 골을 넣을 확률 분포
4-6) 음이항분포(negative binomial distribution)
~
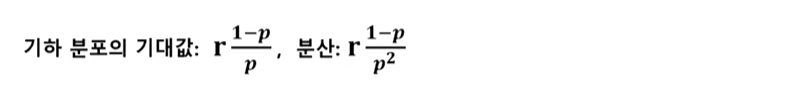
- 어떤 실험에서 성공확률이 p일 때, r번의 실패가 나올 때 까지 발생한 성공 횟수 x의 확률 분포
- e.g) 농구 선수의 자유투 성공 확률이 90%일 때, 3번째 실패가 나올 때 까지 성공시킨 자유투가 10번일 확률
5. 확률분포_연속형확룰분포(무한)
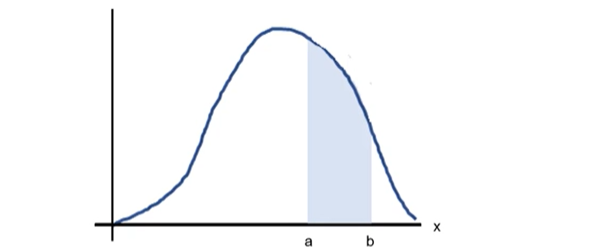
5-1) 확률밀도함수(probability density function)
- 연속형 확률 변수 x에 대해서 함수 f(x)가 아래의 조건을 만족하면 확률밀도함수라고 함
1) 모든 x에 대해서 f(x) >= 0
2)
3)
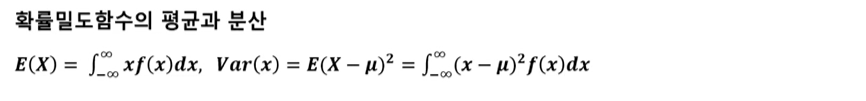
5-2) 누적분포함수(cumulative density function)
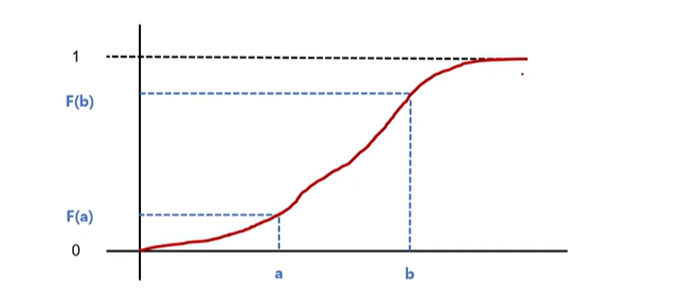
- 확률 밀도함수를 적분하면 누적분포함수가 됨
5-3) 정규분포(normal distribution)
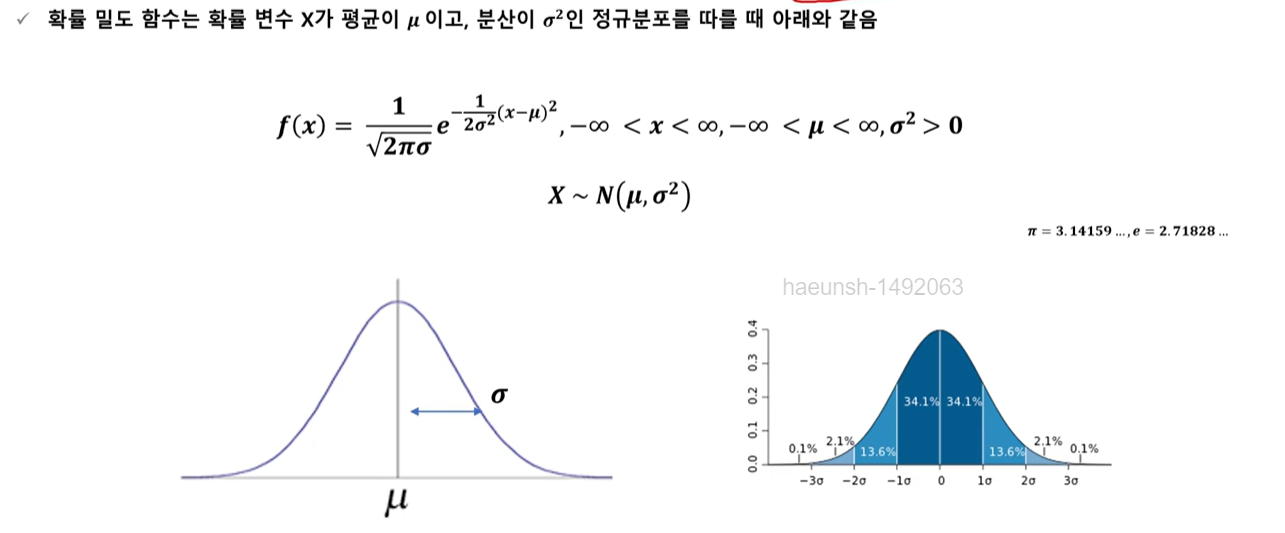
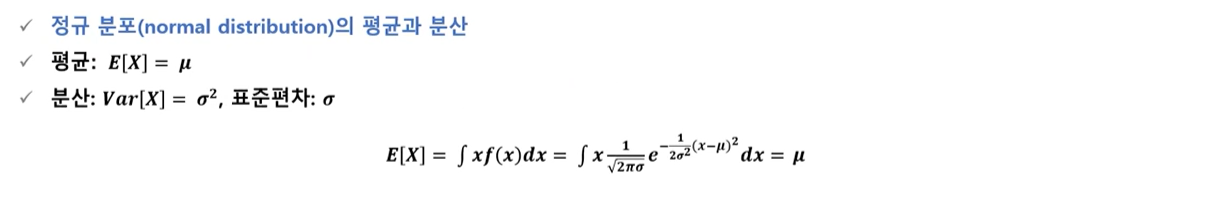
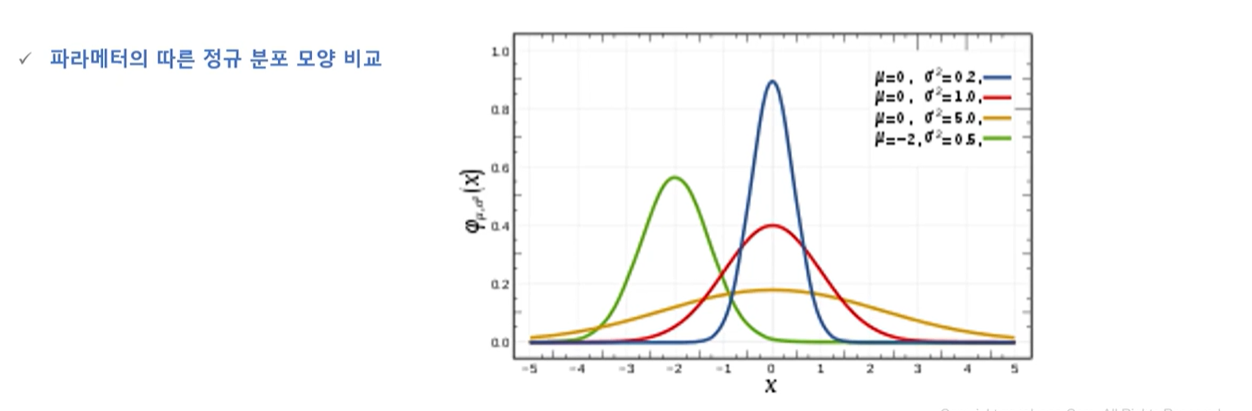

5-4) 이항분포의 정규 근사
- ~ 일 때, 확률 변수 X는 n이 충분히 크면 근사적으로 정규 분포 X ~ N(np, np(1-p))를 따름
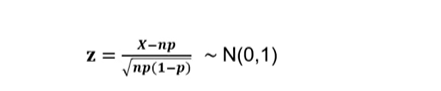
엑셀 예시
1) P[Z <= 1.96] = 0.975
- NORM.DIST(1.96, 0, 1, 1)
2) P[Z <= -1.96] = 1 - P[Z <= 1.96] 0.025
- 1- NORM.DIST(1.96, 0, 1, 1)
- NORM.DIST(-1.96, 0, 1, 1)
3) P[0.5 <= Z <= 1.96] = 0.975 - 0.6915 = 0.28354
- NORM.DIST(1.96, 0, 1, 1) - NORM.DIST(0.5, 0, 1, 1)
4) X ~ N(100, 10^2)일 때, P[100 <= X <= 110]을 구하시오(엑셀을 활용): P[100 <= X <= 110] = P((100-100)/10 <= (X-100)/10 <= (110-10)/10) = P(0<=Z<=1) = 0.8413 - 0.5 = 0.3413
- NORM.DIST(110, 100, 10, 1) - NORM.DIST(100, 100, 10, 1)
5) z_a의 값을 엑셀을 활용하여 구하시오(X ~N(30,25))
- P[X <= z_a] = 0.05 : NORM.INV(0.05, 30, 5)
- P[X >= z_a] = 0.1 : NORM.INV(0.9, 30, 5)
5-5) 지수분포(expoenetial distribution)
- 단위 시간당 발생할 확률 인 어떤 사건의 횟수가 포아송 분포를 따른다면, 어떤 사건이 처음 발생할 때까지 걸린 시간 확률 변수 X는 지수 분포임
- e.g) 버스 정류장에서 100번 버스가 도착하는 횟수가 포아송 분포를 따른다면, 첫 번째 버스가 도착할 때까지 대기 시간의 분포가 지수분포임
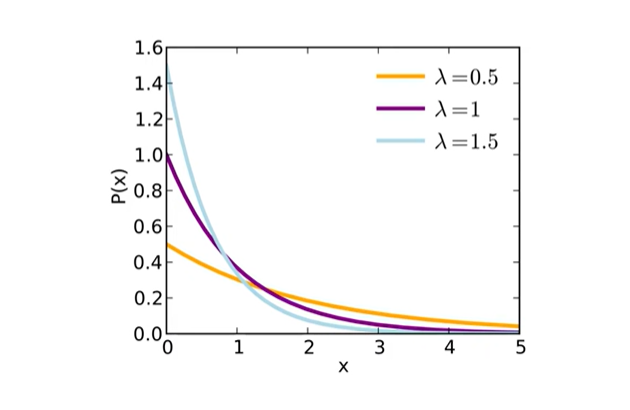

- 지수분포의 무기억성(Memoryless Property)

학부시절 자유전공으로 들어갔기에 1학년을 마치고 어떤 과를 선택할까 하는 고민이 많았다. 그리고 기초 통계수업을 들으며 흥미를 느꼈던 나는 통계학과를 선택했고 2학년까지는 어렵지만 재밌었던 R을 배우며 학부 과정을 보냈다.(지금은 다 까먹음 😂 통계 파트 수업 너무 어렵다...)
그러던 중 내가 수업시간표를 잘못짯던 것을 알게되었다(아직 전공을 고르기 전이였기에 정식 커리큘럼을 토대로 듣기보단 여러 전공의 수업들을 들었었고, 전공을 통계로 정한 뒤에 확인해보니 통계전공생은 2학년 1학기때 필수로 들어야하는 수업이 있었다.. 해당 과목은 1년에 한번 신청 할 수 있는 강의였고 또한 해당 과목을 듣지 않으면 상위 클래스를 들을 수 없었기 때문에 어쩔수 없이 1년을 교양/부전공 수업만 들으며 기다려야하는 상황..😂) 그 시절 나는 오랜 해외생활으로 지쳐있었기 때문에 그 다음으로 관심이 있었고 또 일부 수업을 들어놨던 경제학으로 전공을 바꿨다.
물론 경제학도 너무 재미있었고, 취업시장에서도 좋은 결과를 가져다주었다. 하지만 데이터를 뒤늦게 공부하고 있는 현재에 와보니 1년 꾹 참고 통계학을 졸업했다면 지금은 어땠을까하는 생각을 한다.
역시 인생은 어떻게 될지 한 치 앞도 알 수가 없다!
[자료 출처] 제로베이스 데이터 스쿨
[참고 자료] https://katex.org/docs/supported.html
