console에서 테스트
properties 파일 설정
Kafka를 설치한 후 Kafka 디렉토리에서 아래 경로에 server.properties가 있는 것을 확인할 수 있다.

나는 kraft/server.properties를 kraft/my-properties로 복사해서 설정을 변경해주었다. 아래 환경 설정 부분을 주목해야 한다.
사실 kafka가 로컬에서 실행되고 테스트도 로컬에서 진행된다면 localhost나 127.0.0.1로 설정해도 작동이 되어야 하는게 맞는데 지속적으로 같은 에러가 발생했다. 구글링을 하다가 찾아본 해결 방법이 바로 아래처럼 환경설정을 변경하는 것이다. 참고-블로그
# kafka 로컬에 다운로드
# config/kraft/server.properties 설정변경
#주석#advertised.listeners=PLAINTEXT://localhost:9092
# localhost 대신 카프카 서버의 IP 입력
advertised.listeners=PLAINTEXT://<카프카서버IP>:9092터밀널에서 ifconfig 명령어를 사용하여 IP를 확인할 수 있다. inet 부분을 확인하면 된다. Kafka 서버가 로컬에서 실행 중이므로 여기서는 로컬 IP가 Kafka 서버 IP라고 할 수 있다.
en0: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.1.2 netmask 0xffffff00 broadcast 192.168.1.255
inet6 fe80::fa56:b5ff:fe8d:393e%en0 prefixlen 64 secured scopeid 0x4
ether fa:56:b5:8d:39:3e
media: autoselect
status: activestorage 초기화
propertise 파일을 보면 log.dirs=/tmp/kraft-combined-logs로 설정되어 있는 부분이 있다. 이 곳에 kraft 모드로 실행되는 Kafka 로그가 저장되는데 kafka 클러스터를 생성 후 최초 1회 스토리지 초기화를 해야 kafka가 제대로 작동한다.
# 스토리지 초기화
$ bin/kafka-storage.sh random-uuid
$ bin/kafka-storage.sh format -t <UUID> -c config/kraft/my-properties왜 storage를 초기화 해줘야 할까?
KRaft 모드에서는 Kafka가 Zookeeper 없이 자체적으로 메타데이터를 관리하므로, Kafka를 시작하기 전에 해당 메타데이터 저장소를 초기화해야 한다. 이 초기화 과정은 Kafka가 디스크에 필요한 메타데이터 파일을 생성하고, 클러스터를 관리하는 데 필요한 데이터를 저장하는 작업이다. 이 과정을 통해 Kafka는 클러스터 상태를 추적하고 올바르게 작동할 수 있게 된다.
Kafka 실행
# kafka 실행
$ bin/kafka-server-start.sh ./config/kraft/my-properties
# topic 생성
$ bin/kafka-topics.sh --create --topic <topic> --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1
# topic list 확인
$ bin/kafka-topics.sh --bootstrap-server=localhost:9092 --list
# producer로 메세지 전송
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic <topic>
# consumer로 메세지 수신
$ bin/kafka-console-consumer.sh --topic <topic> --bootstrap-server localhost:9092 --from-beginningproducer

consumer

consumer로 csv파일 만들기
콘솔에서 간단한 테스트를 진행했으니, 이제 python파일로 더미 데이터를 만들어서 producer로 보내고, consumer로 받아서 csv 파일로 저장해보자.
Kafka 실행까지만 콘솔에서 진행하고 나머지 명령어로 실행했던 것들을 python파일로 실행하면 된다. 테스트 코드라서 간단하게 작성해봤다. 실제 코드에서는 많은 예외처리를 생각해야 한다.
producer_test.py
import json
from kafka import KafkaProducer
import json
from datetime import datetime, timedelta
import random
from faker import Faker
import time
fake = Faker()
# Kafka 설정
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# 사용자 행동 로그 샘플 정의
event_types = ['movie_click', 'like_click', 'ad_click', 'play_start', 'play_complete']
pages = ['main', 'movie_detail', 'campaign']
categories = ['action', 'comedy', 'drama', 'sci-fi']
def generate_log():
now = datetime.utcnow()
return {
"user_id": fake.uuid4(),
"movie_id": f"m{random.randint(100,999)}",
"timestamp": now.isoformat(),
"event_type": random.choice(event_types),
"page": random.choice(pages),
"movie_category": random.choice(categories),
"utm_source": random.choice(['instagram', 'naver', 'youtube']),
"utm_medium": random.choice(['social', 'banner', 'cpc']),
"utm_campaign": random.choice(['spring_sale', 'launch2025']),
"utm_content": random.choice(['blue_button', 'video_ad'])
}
# 100개 샘플 메시지 전송
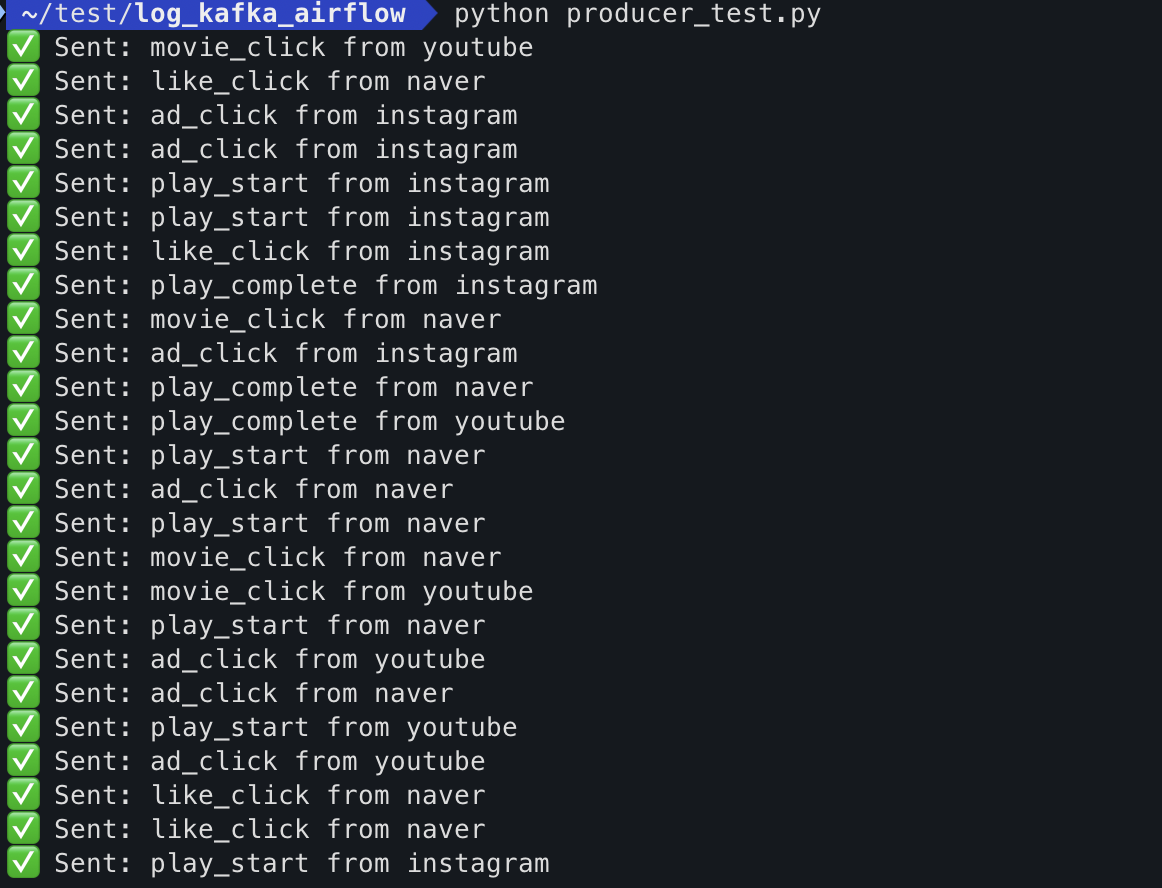
for i in range(100):
event = generate_log()
producer.send('logtest', event)
print(f"✅ Sent: {event['event_type']} from {event['utm_source']}")
time.sleep(0.05) # 속도 조절
producer.flush()flush()
Kafka 프로듀서는 비동기적으로 메시지를 전송한다. 즉 producer.send()를 호출하면 메시지가 즉시 Kafka 브로커에 전송되는 것이 아니라 내부 버퍼에 쌓였다가 일정량이 되거나 특정 조건이 만족되면 일괄적으로 전송된다. 이 방식은 성능을 최적화하기 위해서인데 작은 메시지를 여러 번 보내는 것보다 일정량의 데이터를 한 번에 보내는 것이 효율적이다.
여기서 producer.flush()는 버퍼에 쌓인 모든 메시지를 Kafka 브로커로 즉시 전송하는 역할이다. 이 메서드는 전송 대기 중인 메시지가 모두 전송될 때까지 기다리므로, 이 호출 이후에 메시지가 전송되지 않은 상태로 프로듀서를 종료하지 않도록 보장할 수 있다.
데이터 손실을 방지하려면 프로그램이 종료되기 전에 flush()를 호출하여 버퍼에 쌓인 모든 메시지를 보내는 것이 중요하다.
consumer_test.py
import csv
import json
from kafka import KafkaConsumer
import time
# Kafka Consumer 설정
consumer = KafkaConsumer(
'logtest', # 구독할 토픽 이름
bootstrap_servers='localhost:9092',
group_id='log-test', # 컨슈머 그룹 ID
value_deserializer=lambda x: json.loads(x.decode('utf-8')), # JSON 형식으로 디시리얼화
auto_offset_reset='earliest',
enable_auto_commit=False,
consumer_timeout_ms=5000
)
# CSV 파일 경로
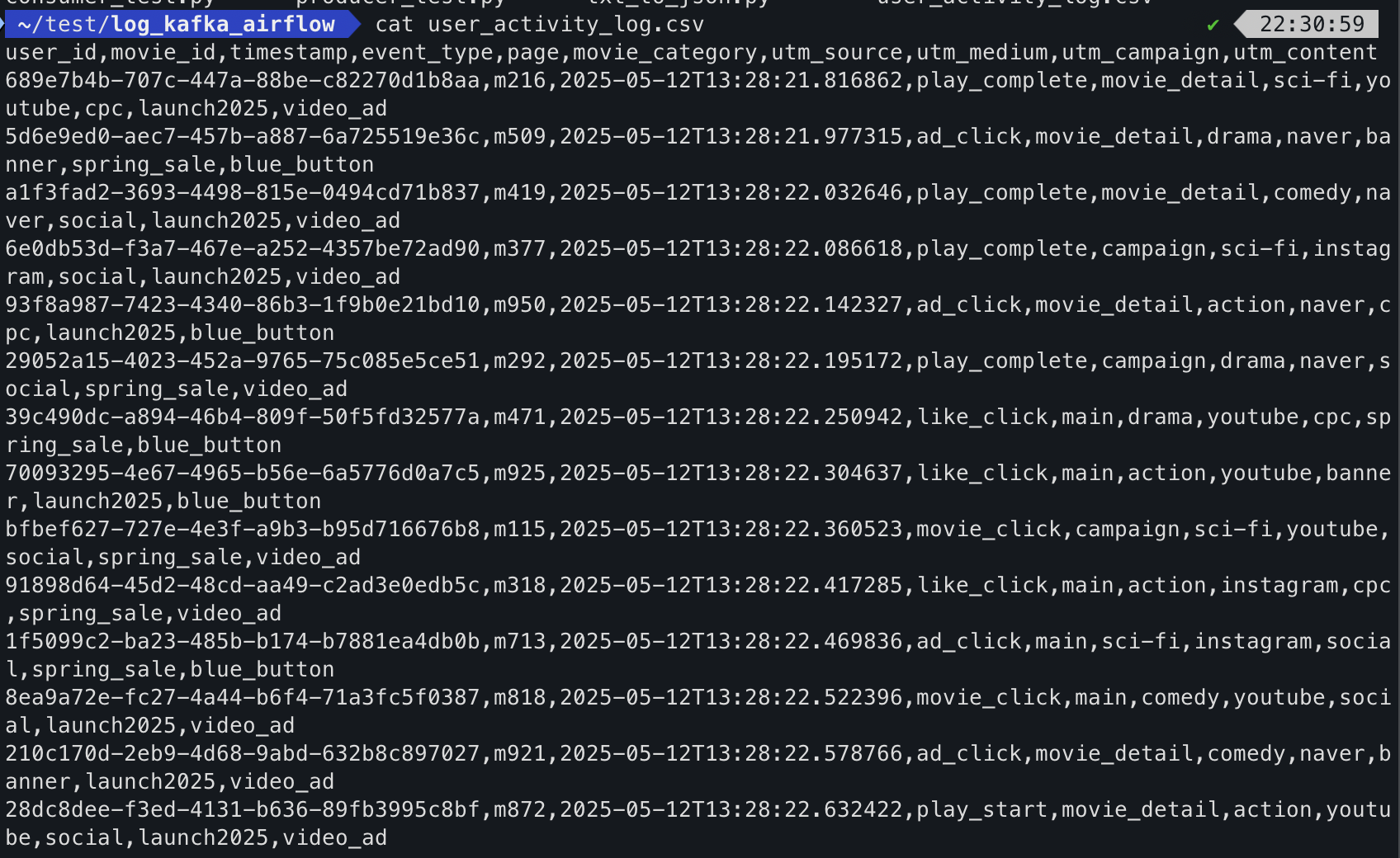
csv_file_path = './user_activity_log.csv'
# CSV 파일 열기 (헤더 작성)
with open(csv_file_path, 'a', newline='') as file:
fieldnames = ["user_id", "movie_id", "timestamp", "event_type", "page", "movie_category", "utm_source", "utm_medium", "utm_campaign", "utm_content"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
# 첫 번째로 파일이 비어 있을 경우 헤더 작성
if file.tell() == 0: # 파일이 비어 있으면 헤더 작성
writer.writeheader()
print("✅ Consumer started, waiting for messages...")
msg_count = 0
max_msg = 100
while True:
message = consumer.poll(timeout_ms=5000)
# 메시지 없으면 종료
if not message:
print("No message")
break
# Kafka로부터 메시지 받기
for tp, messages in message.items():
for msg in messages:
event = msg.value
# CSV로 기록
writer.writerow({key: event[key] for key in fieldnames})
# 메시지 출력 (원하는 정보)
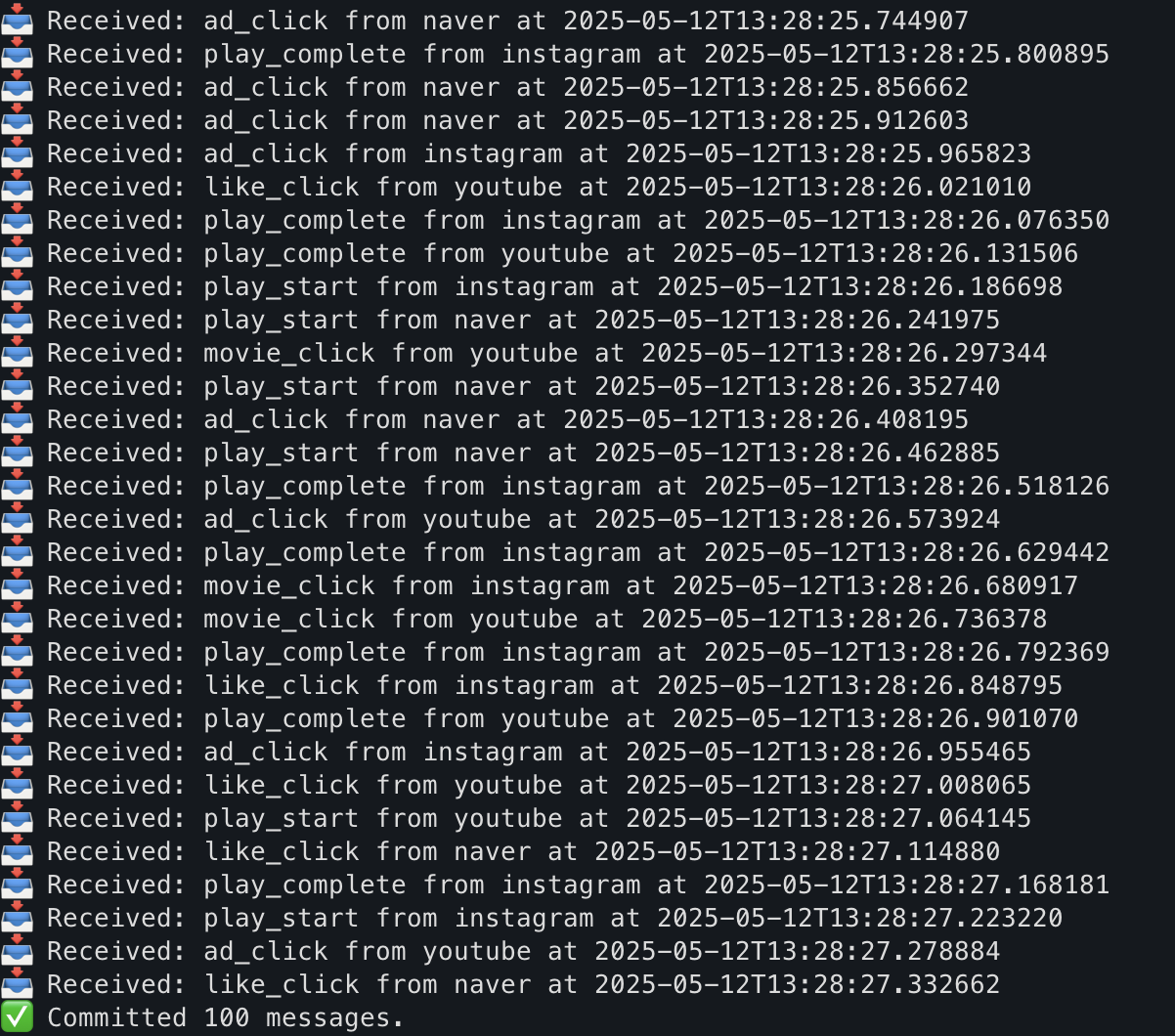
print(f"📥 Received: {event['event_type']} from {event['utm_source']} at {event['timestamp']}")
msg_count += 1
if msg_count >= max_msg:
consumer.commit()
print(f"✅ Committed {msg_count} messages.")
msg_count = 0 # 카운트 초기화
consumer.close()consumer_timeout_ms=5000: 이 설정은consumer.poll()이 데이터를 기다리는 최대 시간을 설정한다. 여기서는 5초 동안 메시지를 기다리며 만약 그 시간 동안 메시지가 도착하지 않으면poll()은 빈 결과를 반환한다.
결과
producer
consumer
No message

csv 파일로 저장 완료
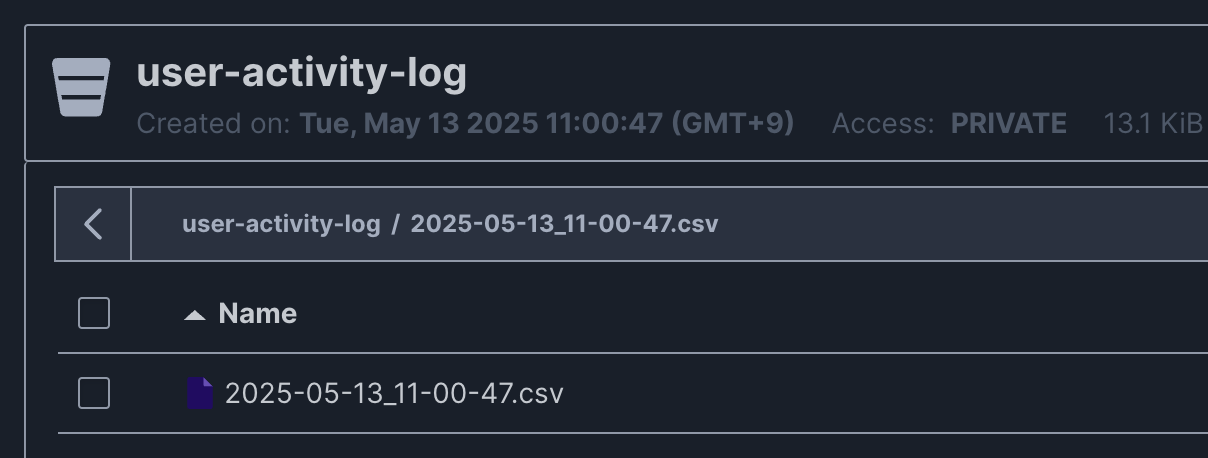
MinIO로 csv파일 업로드
로컬 저장소에 파일 업로드까지 테스트하기 위해서 minIO를 사용했다. producer 코드는 그대로고 consumer 코드만 minIO에 업로드하기 위해서 조금 수정하면 된다.
from minio import Minio
from minio.error import S3Error
from dotenv import load_dotenv
import os
from kafka import KafkaConsumer
from io import StringIO
import time
import csv
import json
from io import BytesIO
from datetime import datetime, timezone, timedelta
# 한국 시간(KST)으로 현재 시간 가져오기
kst = timezone(timedelta(hours=9)) # KST는 UTC +9 시간대
current_time_kst = datetime.now(kst)
load_dotenv()
# MinIO 클라이언트 초기화
minio_client = Minio(
"localhost:9000", # MinIO 서버의 주소
access_key=os.getenv('ID'), # 액세스 키
secret_key=os.getenv('PW'), # 시크릿 키
secure=False # HTTPS를 사용하지 않는 경우
)
# 연결 테스트
try:
# MinIO 서버가 정상적으로 연결되는지 확인
print(minio_client.list_buckets())
except S3Error as e:
print(f"Error occurred: {e}")
# 버킷없으면 생성
bucket_name = "user-activity-log"
if not minio_client.bucket_exists(bucket_name):
minio_client.make_bucket(bucket_name)
# Kafka Consumer 설정
consumer = KafkaConsumer(
'test', # 구독할 토픽 이름
bootstrap_servers='localhost:9092',
group_id='testminio', # 컨슈머 그룹 ID
value_deserializer=lambda x: json.loads(x.decode('utf-8')), # JSON 형식으로 디시리얼화
auto_offset_reset='earliest',
enable_auto_commit=False,
consumer_timeout_ms=5000
)
print("✅ Consumer started, waiting for messages...")
msg_count = 0
max_msg = 100
while True:
message = consumer.poll(timeout_ms=5000)
print(message)
# 메세지 없으면 종료
if not message:
print("No message!!!!")
break
csv_file = StringIO()
fieldnames = ["user_id", "movie_id", "timestamp", "event_type", "page", "movie_category", "utm_source", "utm_medium", "utm_campaign", "utm_content"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for tp, messages in message.items():
for msg in messages:
event = msg.value
writer.writerow({key: event[key] for key in fieldnames})
print(f"📥 Received: {event['event_type']} from {event['utm_source']} at {event['timestamp']}")
msg_count += 1
if msg_count >= max_msg:
consumer.commit()
print(f"✅ Committed {msg_count} messages.")
msg_count = 0
# csv를 minio에 업로드(메모리상에 기록된 csv를)
csv_file.seek(0) # 파일 포인터를 처음으로 되돌림
##############################
# StringIO 객체를 바이트형으로 변환하고, 이를 BytesIO 객체로 감쌈
csv_data = csv_file.getvalue().encode('utf-8') # 문자열을 바이트로 변환
csv_stream = BytesIO(csv_data) # 바이트 데이터를 BytesIO 객체로 변환
##############################
# 한국 시간으로 파일명 생성 (예: 2025-05-13_13-30-00.csv)
filename = current_time_kst.strftime("%Y-%m-%d_%H-%M-%S") + ".csv"
minio_client.put_object(
bucket_name,
filename,
csv_stream,
len(csv_data)
)
print("✅ File uploaded to MinIO")
consumer.close()MinIO 사용 이유
1-2단계에서는 최대한 클라우드 환경을 배제하고 로컬 환경에서 테스트하는 방향으로 프로젝트가 진행된다. 그래서 Amazon S3를 사용하기 보다는 S3와 호환되는 오브젝트 스토리지인 MinIO로 로컬 테스트를 먼저 진행했다.
MinIO는 Amzon S3와 호환되는 오브젝트 스토리지 시스템이다. S3 API와 호환되기 때문에, 로컬 테스트 중에도 실제 운영 환경과 동일한 방식으로 데이터를 저장하고 읽을 수 있다. 또한 클라우드 스토리지 사용 비용을 고려하지 않아도 되서 테스트 스토리지로 사용하게 되었다.
나름 트러블슈팅
콘솔에서 확인해보면 consumer가 메세지를 받아왔는데 minIO로 업로드 되지 않는 문제가 있었다. 아래는 이를 해결하는 방법이다.
consumer에서 받은 데이터를 메모리상에 문자열로 저장하기 위해 csv_file=StringIO()로 선언해주는데 MinIO나 다른 파일 업로드 시스템은 파일을 업로드할 때 데이터를 바이트 형식으로 받는다. 따라서 csv_file.getvalue()로 문자열을 가져와서 .encode('utf-8')로 바이트 형식으로 인코딩하는 작업이 필요하다.
또한 minio_client.put_object()는 파일-like 객체를 요구하므로 이를 BytesIO로 감싸서 파일처럼 처리할 수 있도록 만든다.
# StringIO 객체를 바이트형으로 변환하고, 이를 BytesIO 객체로 감쌈
csv_data = csv_file.getvalue().encode('utf-8') # 문자열을 바이트로 변환
csv_stream = BytesIO(csv_data) # 바이트 데이터를 BytesIO 객체로 변환결과