Lv.3 대장균의 크기에 따라 분류하기 2
문제
대장균 개체의 크기를 내름차순으로 정렬했을 때 상위 0% ~ 25% 를 'CRITICAL', 26% ~ 50% 를 'HIGH', 51% ~ 75% 를 'MEDIUM', 76% ~ 100% 를 'LOW' 라고 분류합니다. 대장균 개체의 ID(ID) 와 분류된 이름(COLONY_NAME)을 출력하는 SQL 문을 작성해주세요. 이때 결과는 개체의 ID 에 대해 오름차순 정렬해주세요 . 단, 총 데이터의 수는 4의 배수이며 같은 사이즈의 대장균 개체가 서로 다른 이름으로 분류되는 경우는 없습니다.
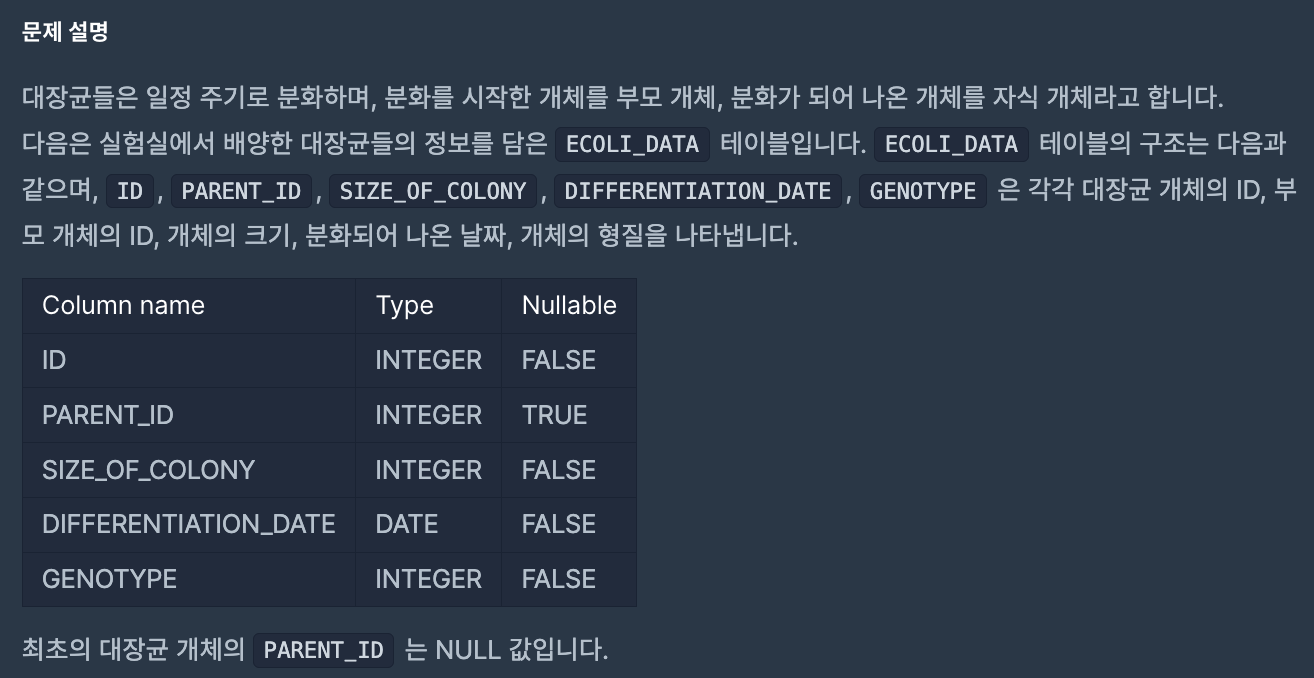
예제
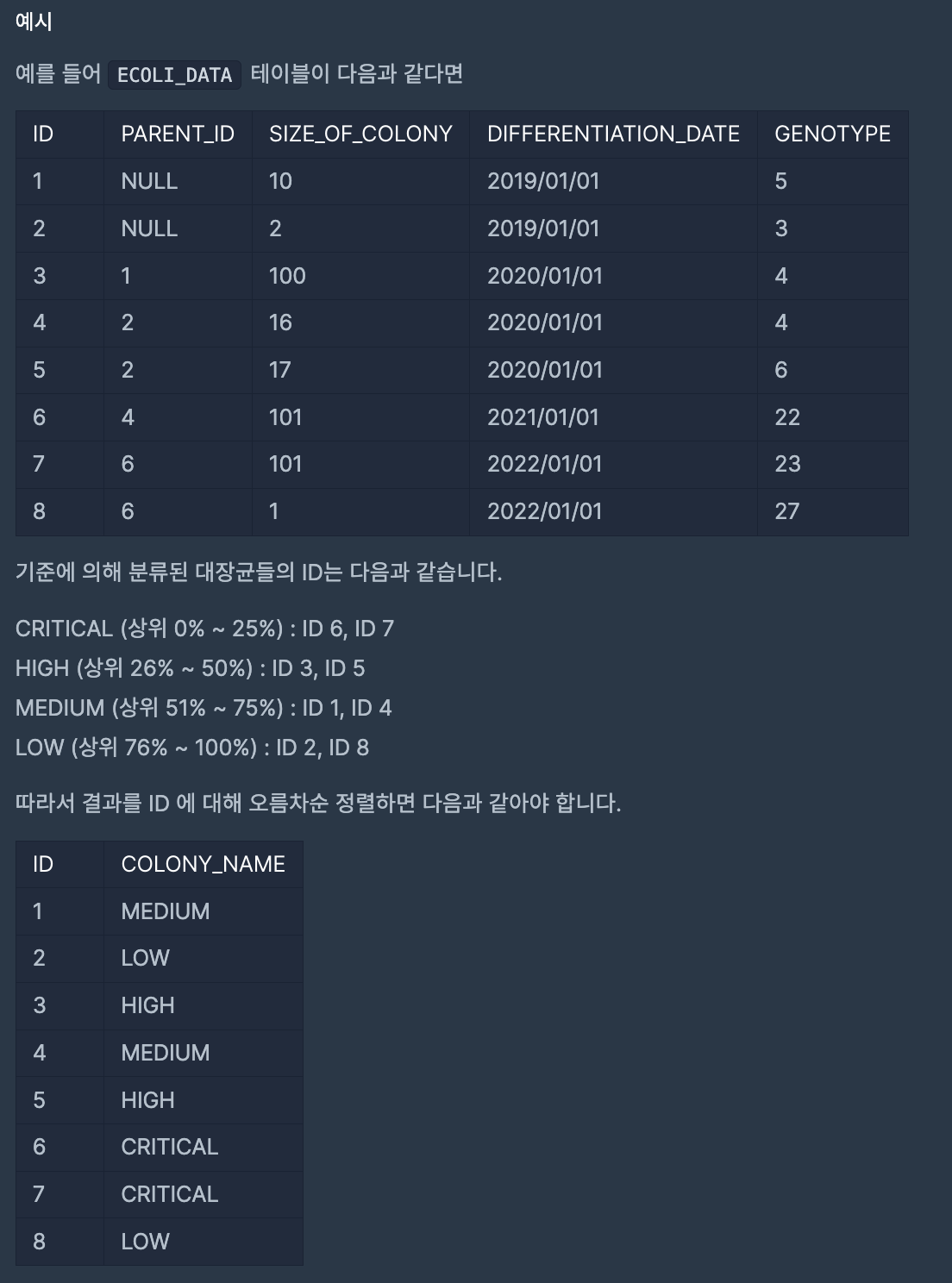
나의 풀이
크기 비교를 BETWEEN으로 해서 풀었는데 그렇게 하면 % 사이에 갭이 생기는 부분이 발생하여서 비교 연산자로 다시 풀었다.
SELECT
I.ID,
CASE
WHEN I.R <=0.25 THEN 'CRITICAL'
WHEN I.R <= 0.5 THEN 'HIGH'
WHEN I.R <= 0.75 THEN 'MEDIUM'
ELSE 'LOW'
END AS COLONY_NAME
FROM
(
SELECT
ID,
PERCENT_RANK() OVER (ORDER BY SIZE_OF_COLONY DESC) AS R
FROM
ECOLI_DATA
)
AS I
ORDER BY
I.ID ASC;끄적끄적
이참에 RANK 관련 문법 정리를 해보자.
RANK()
RANK()는 순위를 부여하는 함수로 동일한 값이 있을 경우 같은 순위를 부여하여 순위 건너뛰기가 발생한다.
RANK() OVER (PARTITION BY column_name ORDER BY column_name DESC)DENSE_RANK()
DENSE_RANK()는 동점이면 같은 순위를 부여하지만 순위가 건너뛰지 않는다.
DENSE_RANK() OVER (PARTITION BY column_name ORDER BY column_name DESC)ROW_NUMBER()
ROW_NUMBER()는 순위를 무조건 1,2,3, ... 형태로 부여하며 동점이어도 랜덤하게 순위를 부여한다. 순위의 일관성이 필요하다면 ORDER BY로 정렬 조건을 추가해야 한다.
ROW_NUMBER() OVER (PARTITION BY column_name ORDER BY column_name DESC)PERCENT_RANK()
PERCENT_RANK()는 백분율 순위를 계산하는 함수로 0과 1 사이의 값으로 표현되며, 0은 최저 순위, 1은 최고 순위이다.
PERCENT_RANK() OVER (PARTITION BY column_name ORDER BY column_name DESC)
데이터 엔지니어가 되어 봅시다 🌈