심화(복습)
2차원 배열

크로아티아 알파벳 : 2941
문제

예제
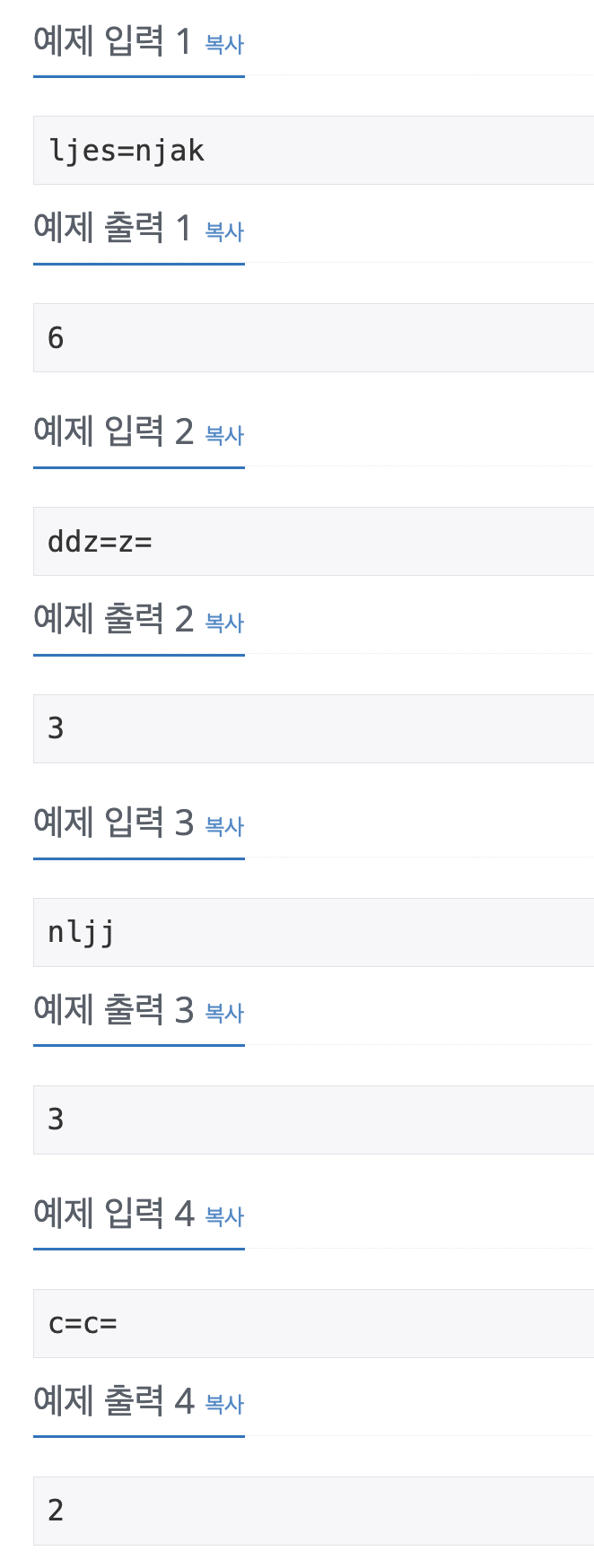
나의 풀이
replace()는 문자열에서만 사용가능하다는 것을 주의하자.
word = input()
c_word = ['c=', 'c-', 'dz=', 'd-', 'lj', 'nj', 's=', 'z=']
for i in c_word:
if i in word:
word = word.replace(i,'*')
print(len(word))그룹 단어 체커 : 1316
문제
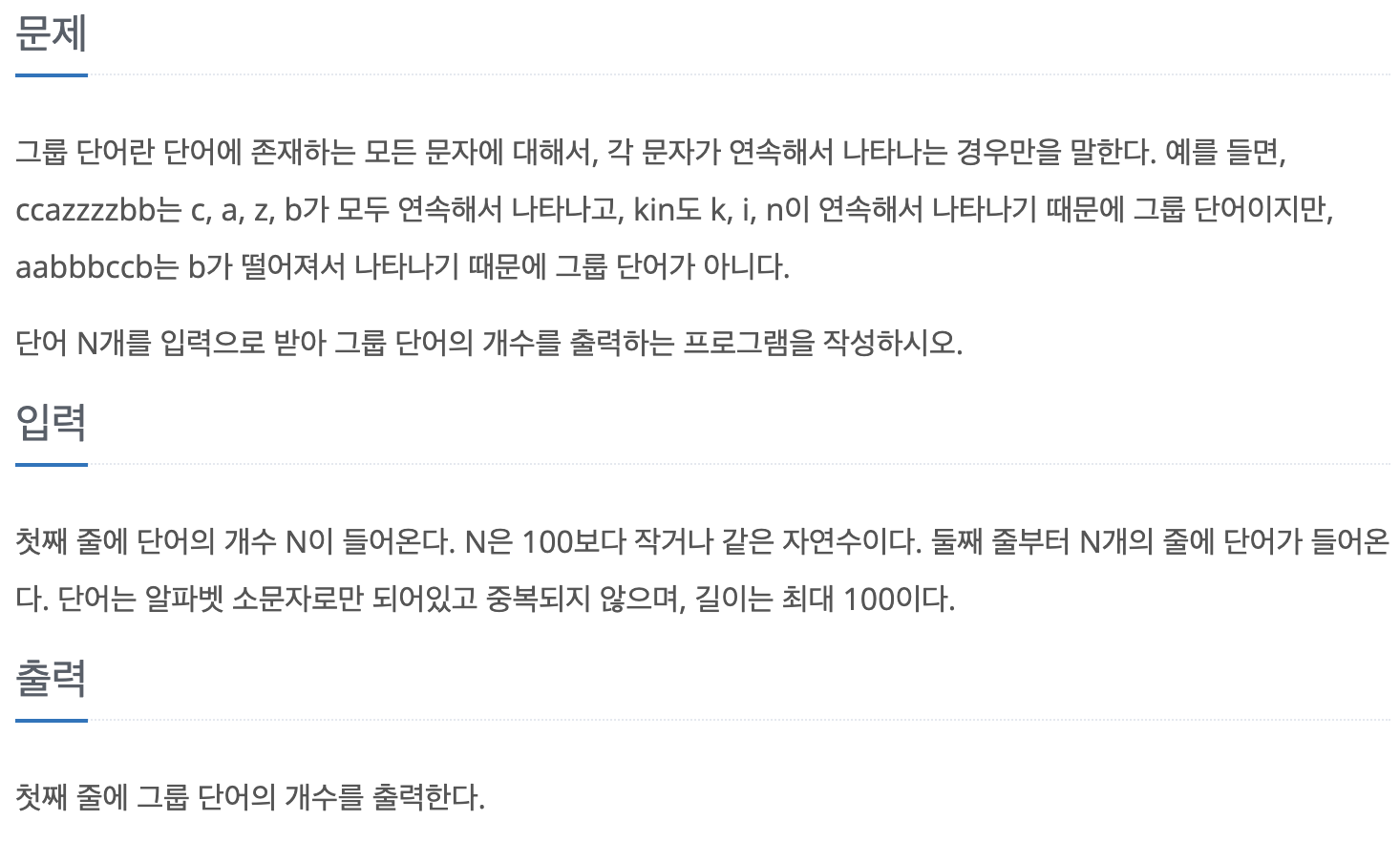
예제

나의 풀이
result = 0
for _ in range(int(input())):
word = input()
is_group_word = True
for i in range(1, len(word)):
if word[i] != word[i-1] and word[i] in word[:i]:
is_group_word = False
break
if is_group_word:
result += 1
print(result)다른 풀이
set()의 key 매개변수를 사용한 커스텀 정렬로 문제를 해결한 코드를 찾았다.
result = 0
for i in range(int(input())):
word = input()
if list(word) == sorted(word, key=word.find):
result += 1
print(result)최댓값 : 2566
문제

예제
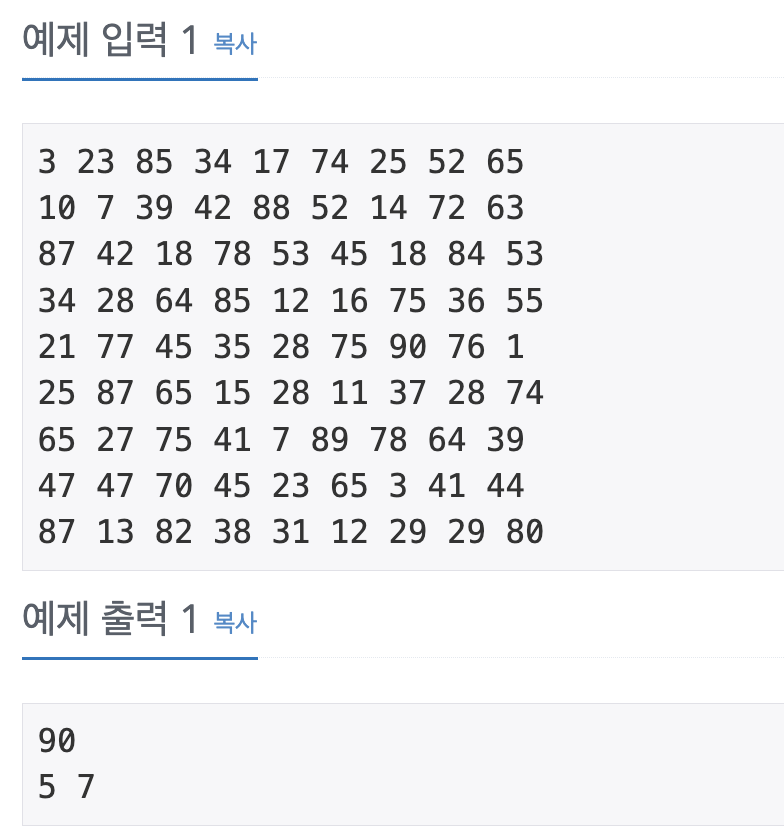
나의 풀이
arr = []
for _ in range(9):
arr.append(list(map(int, input().split())))
max_num = -1
for i in range(9):
for j in range(9):
if arr[i][j] > max_num:
max_num = arr[i][j]
col = i+1
row = j+1
print(max_num)
print(col, row)다른 풀이
max_num = max(max(row) for row in arr) 이 부분을 참고해서 max()를 활용해 보자
arr = []
for _ in range(9):
arr.append(list(map(int, input().split())))
max_num = max(max(row) for row in arr) # 각 행에서 최대값을 찾아 그 중에서 최대값을 찾음
# 최댓값을 가진 위치 찾기
for i in range(9):
if max_num in arr[i]:
col = i + 1
row = arr[i].index(max_num) + 1
break
print(max_num)
print(col, row)끄적끄적
repalce()
replace()는 주로 문자열에서 사용되는 함수로, 지정한 문자열을 다른 문자열로 바꿀 때 사용한다. 기본형은 text.replace(old value, new value)이다.
# 기본형
text = "나는 파이썬을 좋아해."
new_text = text.replace("파이썬", "자바")
print(new_text) # '나는 자바를 좋아해'
# 횟수 제한
text = "나는 파이썬을 좋아해. 파이썬은 정말 멋있어."
new_text = text.replace("파이썬", "자바", 1) # 한 번만 바꿀 때
print(new_text) # '나느 자바을 좋아해. 파이썬은 정말 멋있어'
sorted(word, key=value.find)
sorted(word, key=word.find)는 각 문자에 대해 word.find()를 호출하여 각 문자가 처음 등장한 인덱스를 기준으로 정렬하는 방식이다.
word = "aba"
# a가 처음 등장한 인덱스는 0이다.
# b가 처음 등장한 인덱스는 1이다.
# 두번째 a가 처음 등장한 인덱스는 0이다.
print(sorted(word, key=word.find)) # ['a', 'a', 'b']
데이터 엔지니어가 되어 봅시다 🌈