전처리
AST pretrained 모델 같은 경우 추구하는 input configuration 이 있다.
- window size: 25ms, hop length: 10ms 기준으로 10.24초의 Mel Spectrogram
- Mel Filter Bank: 128 filters
- 16kHz Sampling rate
다행히도 HuggingFace Transformers 라이브러리에서 AST 모델에 맞게 전처리 모듈을 쉽게 불러오게끔 만들어 놓았다.
자세한 코드는 아래 링크를 통해 확인해볼 수 있다.
AST Feature Extractor
https://github.com/huggingface/transformers/blob/v4.38.2/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py#L39
AST Feature Extractor 로 전처리 하기 전에 먼저 세 가지를 진행하였다.
- Sampling Rate 조절
- 오디오 길이 조절
- Band Pass Filter
Sampling Rate 조절
AST model 은 기본적으로 16kHz Sampling rate을 요구한다. 그러나 EDA에서 봤듯이 40kHz 이상의 sampling rate이 상당히 많았기 때문에 16kHz로 압축을 시키면 정보손실이 클 우려가 있었다.
그렇다고 해서 기본 configuration을 크게 벗어나면 성능 및 학습에 문제가 있을 수 있으므로 우리 팀은 타협점을 찾아야 했다. 그래서 모든 오디오 sampling rate를 20kHz로 불러오기로 결정했다.
오디오 길이 조절
사실 AST Feature Extractor가 자동으로 10.24초로 패딩을 해주어 길이를 맞춰주기 때문에 길이 조절을 할 필요는 없었다. 그때 당시는 이 부분을 생각을 못하고 EDA에서 확인한 평균 6초로 오디오 길이를 맞춰주었다.
- 오디오 길이 조절 코드
def __getitem__(self, idx):
audio_path = self.audio_paths[idx]
label = self.audio_labels[idx]
waveform, _ = librosa.load(audio_path, sr=self.sr, duration=6.0)
if waveform.shape[0] < 120000:
waveform = librosa.util.fix_length(waveform, size=120000)BandPass Filter
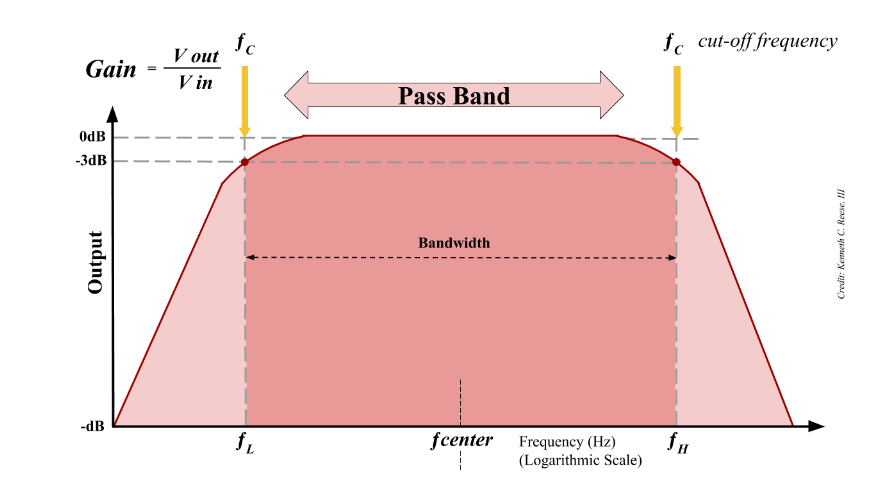
Band Pass filter를 설명하면 center frequency를 기준으로 Bandwidth를 정해서 Bandwidth 밖에 있는 주파수의 증폭을 줄이는 방식이다. Bandwidth는 쉽게 말해 통과시킬 주파수 범위를 의미하고 center frequency는 Bandwidth의 중간값을 의미한다.
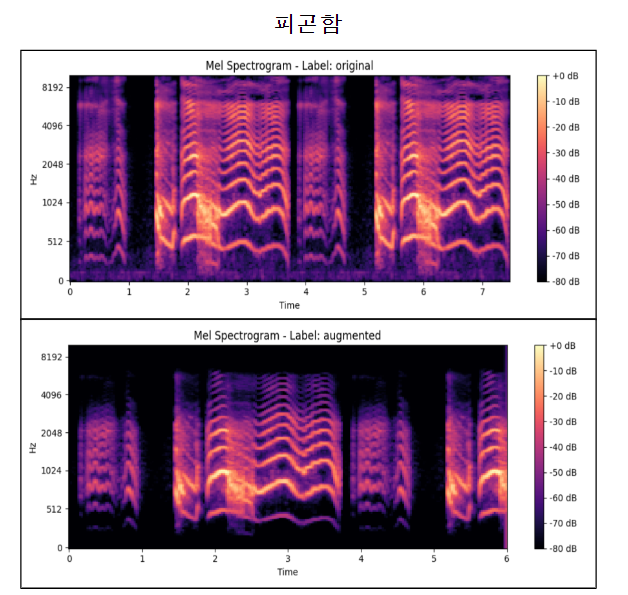
이렇게 했을 때 아래와 같이 원본과 Band Pass Filter 가 적용된 Mel Spectrogram을 비교해 볼 수 있다.
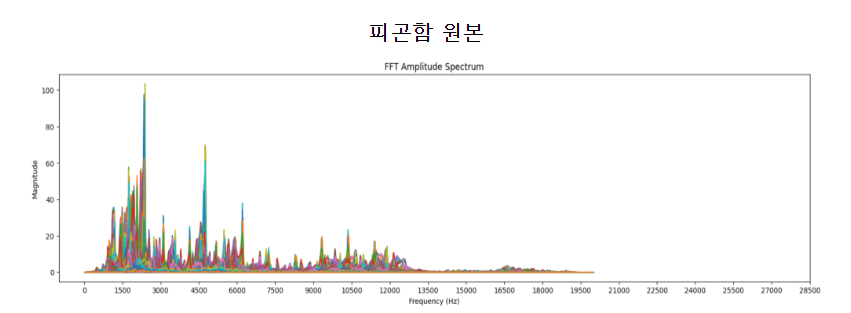
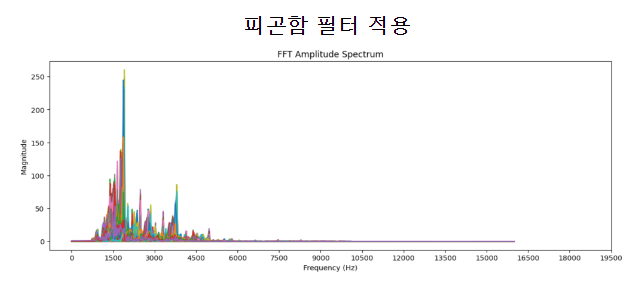
덤으로 STFT(Short Term Fourier Transform)으로도 비교를 할 수 있었다.
데이터 증강
데이터 셋을 재구성 후 사이즈가 작은 걸 인지하였기에 증강을 하기로 했다.
방법은 tf.ImageDataGenerator 같은 방식을 택하였다. 그래서 에폭마다 데이터셋이 바뀌어 input으로 들어가게 해서 작은 데이터 셋 사이즈를 어느 정도 보완하였다.
처음에는 증강을 torchaudio를 활용할 생각이었으나 방법이 복잡하여 Audiomentations을 쓰기로 했다.
증강은 아래 방법으로 진행하였다.
- 생활소음 합성
a. 아무래도 육아 환경이 집일 확률이 높기 때문에 생활소음을 섞어 증강에 적용하는 게 적절하다고 판단
b. 생활소음 데이터 셋 소스 - 길이 확대 및 축소
- 음 높낮이 변경
적용 코드는 아래와 같다.
augmentations = Compose([
AddBackgroundNoise(sounds_path = noise_path,
min_snr_db=17,
max_snr_db=17,
p=0.3),
TimeStretch(min_rate=0.9, max_rate=1.1, p=0.5),
PitchShift(min_semitones=-1.1, max_semitones=1.1, p=0.5),
BandPassFilter(min_center_freq=1500, max_center_freq=1500,
max_bandwidth_fraction=1.33, min_bandwidth_fraction=1.33,
max_rolloff=12, min_rolloff=12, p=1.0),
Normalize(p=1.0)
])
train_dataset = AudioPipeline(audio_paths=train_paths, audio_labels=train_labels, sr=20000, transform=augmentations)
val_dataset = AudioPipeline(audio_paths=val_paths, audio_labels=val_labels, sr=20000)
test_dataset = AudioPipeline(audio_paths=test_paths, audio_labels=test_labels, sr=20000)
# dataloader에 담기
train_dataloader = DataLoader(train_dataset, batch_size=10, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=10, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=10, shuffle=True)👉👉 다음 챕터 읽으러 가기
