
오늘의 할 일!
스크래핑 : 웹 사이트를 분석하여 원하는 데이터를 추출하는 과정
- 크롤링이라 쓰고, 아직 우리 수준에서는 스크래핑이 더 맞기 때문에
실제로 하는건 스크래핑이라 부르자
크롤링과 스크래핑의 차이?
크롤링
- 자동화
- 웹 상의 데이터가 최신화 될 때마다 나의 데이터베이스도 최신화 된다
스크래핑
- 자동화가 되지는 않음
- 긁어오는 시점의 데이터만 긁어온다
우선 어떤 웹 브라우저를 크롤링 하고싶은지 지정하기!
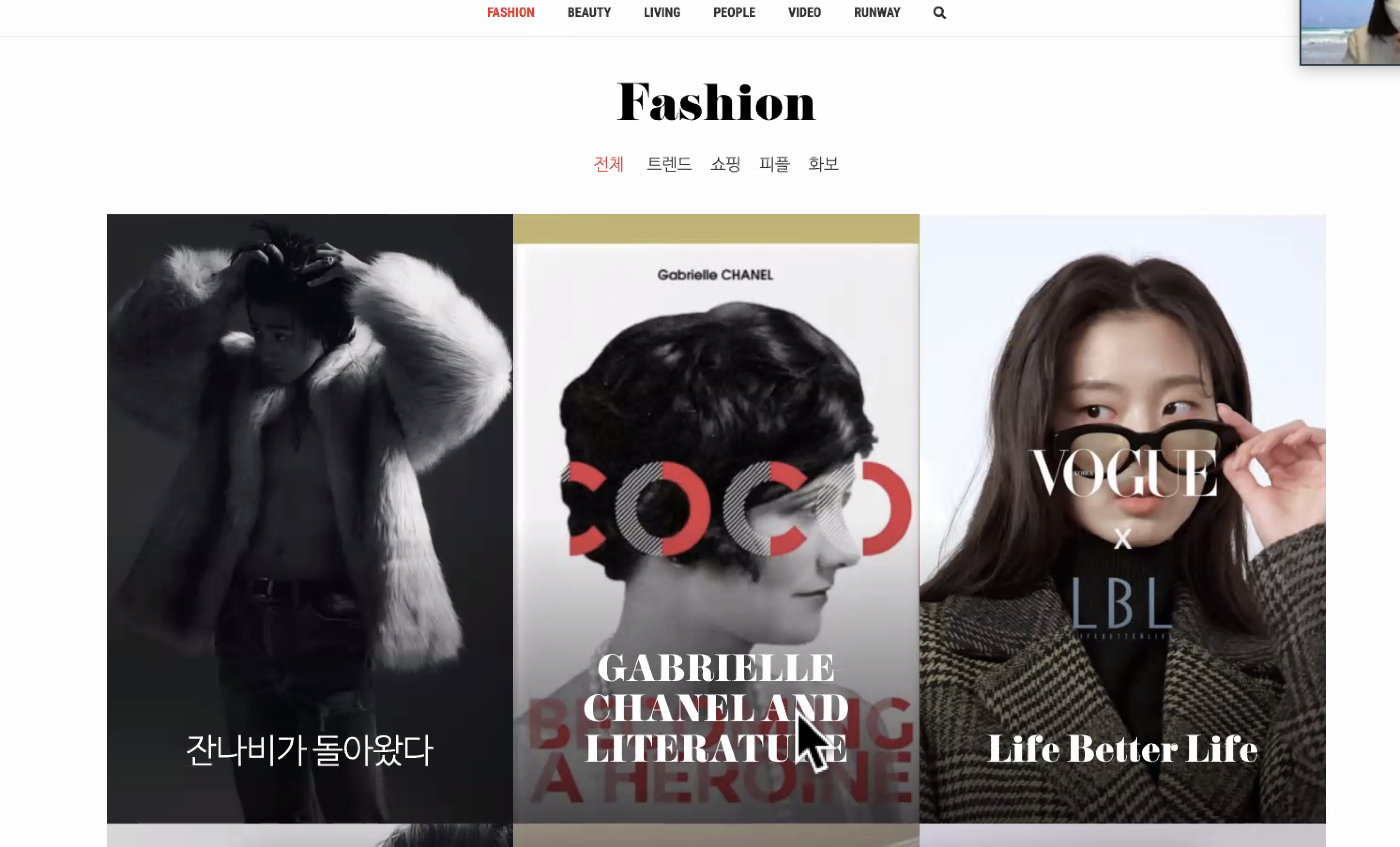
👆🏻 보그 웹사이트를 크롤링한다고 가정했을 때,
- 어떠한 항목들을 가져올 것인지
- 어떠한 라이브러리를 사용해서 크롤링 작업을 할 것인지
정해야한다!

개발자 도구option + command + i를 통해 html 파일을 조회해보면 대략적인 분석이 가능하다.
우선, <img> 태그를 확인해보자!
👉🏻 해당 태그마다 어떠한 image 파일을 사용하고 있는지, 등을 분석할 수 있다.
BUT!!
웹 브라우저는 html 파일을 이해할 수 있지만
terminal에게 html파일은 그저 텍스트일 뿐!
terminal은 해당 코드가 html 태그인지, css 선택자인지 알 수 없다
크롤링을 하기 위해, html 파일을 인식하도록 하기 위해서는
특정 라이브러리를 사용해야 한다
Beautiful soup
- html과 xml파일로부터 데이터를 뽑아내는 파이썬 라이브러리
- html의 'id', 'class' , css selector를 분석해서 변수로 사용할 수 있도록 해준다
selenium
- 브라우저를 실행시켜 동적인 입력이 필요한 웹을 구동할 수 있는 라이브러리
- 검색어 입력, 버튼 클릭 등의 동작을 실행하도록 도와준다
ex) '크롤링' 검색 결과 페이지 스크랩
> pip freeze👆🏻 가상환경에 어떠한 라이브러리가 설치되었는지 확인할 수 있다
실습하기
1. 가상환경 세팅하기
python --version우선 내 컴퓨터에 설치되어있는 파이썬의 버전을 확인한 뒤,
conda create -n web-crawling python=3.8miniconda를 통해 web-crawling이라는 이름의 가상환경을 설치하겠다고 입력하기!
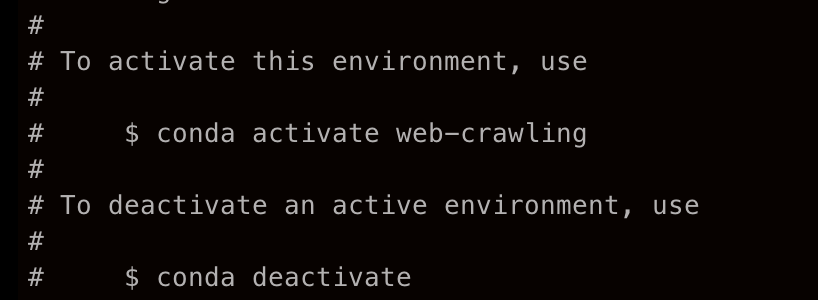
이 가상환경을 활성화 할 것인지, 아닌지에 대해서 입력해야 한다.
conda activate web-crawling나는 작업을 해줄 것이므로 👆🏻👆🏻 요로케 입력하기!
2. 필요한 라이브러리 설치해주기
>> pip install beautifulsoup4
>> pip install requests
>> pip install selenium
>> pip install webdriver-manager
>> pip freeze👆🏻 크롤링을 하기 위해 필요한 beautifulsoup,
웹사이트로 요청할 때 필요한 requests를 설치하고
(추후에 자동화 된 크롤링을 하기 위해 selenium, webdriver-manager를 추가했다)
pip freeze를 통해 설치내역 확인하기!
3. Beautiful Soup으로 크롤링 시도하기
1 from bs4 import BeautifulSoup
2
3 import csv
4 import re
5 import requests
6
7 #1. csv file open
8 csv_name = "main_all.csv"
9 csv_open = open(csv_name, "w+", encoding="utf-8")
10 csv_writer = csv.writer(csv_open)
11 csv_writer.writerow(("drink", "image_url"))
12
13 #2.BeautifulSoup
14 crawling_url = "https://www.starbucks.co.kr/menu/drink_list.do"
15 response = requests.get(crawling_url)
16
17 #3. Parsing html code
18 html = response.text
19 bs = BeautifulSoup(response.text, 'html.parser')
20
21 #4. Get element selector
22 lists = bs.select("#container > div.content > div.product_result_wrap.product_result_wrap01 > div > dl > dd:nth-child(2) > div.product_list > dl > dd:nth-child(2) > ul > li:nth-child(1) > dl > dd")
23 imgs = bs.select("#container > div.content > div.product_result_wrap.product_result_wrap01 > div > dl > dd:nth-child(2) > div.product_list > dl > dd:nth-child(2) > ul > li:nth-child(1) > dl > dt > a > img") 24
25 #5. Save drink, img
26 with open(csv_name, "w+", encoding = "utf-8") as file:
27 for i in range(len(lists)):
28 #drink
29 drink = lists[i]['dd']
30
31 #image_url
32 img_url = crawling_url + '/' + imgs[i]['src']
33
34 writer = csv.writer(file)
35 writer.writerow((drink, img_url))👆🏻 크롤링 작업을 위해 BeautifulSoup만 쓴 상황!
작성하다가 selenium을 사용해서 보다 편리하게 크롤링을 하려고 했어서 작성ㅎㅏ다 그만둔 코드..

요로케 python crawling.py하고 파일을 실행시키면
터미널 창에는 아무런 변화도 생기지 않지만
내가 작업중인 디렉토리에 가면 csv파일이 생성되어있는것을 볼 수 있다!
👆🏻 결과물!
(아무 데이터도 가져오지 못했으니 누가 봐도 문제가 다분한 코드파일인듯 ㅎㅅㅎ)
4. Selenium으로 크롤링 동작 구동하기
무튼 selenium을 사용해서, 동적인 입력을 자동으로 하는 크롤링을 해보도록 할 것!
1 from bs4 import BeautifulSoup
2 from selenium import webdriver
3 from webdriver_manager.chrome import ChromeDriverManager
4
5 import csv
6 import time
7
8 #1. csv file open
9 csv_name = "main_all.csv"
10 csv_open = open(csv_name, "w+", encoding="utf-8")
11 csv_writer = csv.writer(csv_open)
12 csv_writer.writerow(("category", "drink", "image_url"))
13
14
15 #2. Driver & BeautifulSoup
16 driver = webdriver.Chrome(ChromeDriverManager().install())
17
18 crawling_url = "https://www.starbucks.co.kr/menu/drink_list.do"
19 driver.get(crawling_url)
20
21
22 #3. Parsing html code
23 full_html = driver.page_source
24 soup = BeautifulSoup(full_html, 'html.parser')
25
26 time.sleep(3)
27
28
29 #4. Get element selector (1)
30 categories = soup.select('#mCSB_1_container > li')
31
32
33 #5. Get element selector (2)
34 for i in range(2, len(categories)+1):
35 element = driver.find_element_by_css_selector(f'#mCSB_1_container > li:nth-child({i})')
36 category_name = element.text
37 time.sleep(2)
38 element.click()
39
40 full_html = driver.page_source
41 soup = BeautifulSoup(full_html, 'html.parser')
42
43 titles = soup.select(f'#container > div.content > div.product_result_wrap.product_result_wrap01 > div > dl > dd:nth-child(2) > div.product_list > dl > dd:nth-child({(i-1)*2}) > ul > li > dl > dt > a > img')
44
45 #6. print drink_title, image url
46 for i, title in enumerate(titles):
47 print('title: ', title['alt'])
48 print('original src: ', title['src'])
49 print('image_url: ', title['src'].split('/')[4:])
50 url = crawling_url + '/' + '/'.join(title['src'].split('/')[4:])
51
52 if i == 0:내가 작성한 코드!
0. 필요한 라이브러리, 모듈 import
우선 selenium 라이브러리, time 모듈을 추가로 import 해준다.
동적인 입력을 자동으로 하게 하기 위해서는 웹 페이지가 로딩 된 이후에 동작해야 한다.
이 때 time모듈의 기능을 사용해주는 것!
1. CSV파일 관련 설정
작성할 csv파일에 대한 설정을 해주고, csv 파일 내 어떤 컬럼을 생성할 것인지 지정한다
2. 크롤링 준비
어떠한 웹 브라우저를 통해 크롤링을 할 것인지,
어느 주소의 웹 페이지를 크롤링 할 것인지 명시해주는 구간!
3. 웹 페이지를 html파일로 파싱
내가 크롤링하겠다고 명시한 페이지를 html파일로 파싱해주는 구간!
여기서 BeautifulSoup 라이브러리를 사용해서 파이썬이 html파일을 인식할 수 있도록 해준다.
앞서 이야기했지만, html 파일은 파이썬에게 있어 그저 문자열의 나열일 뿐!
parsing을 통해 이것이 우리가 작업할 html파일이다, 하고 인식할 수 있도록 해주어야 한다.
이제 대망의 단계, 크롤링 해올 선택자를 파악해야하는 구간이다.
(여기서 제일 많이 헷갈리고 고민되는 부분)
4. 선택자 가져오기 (1)
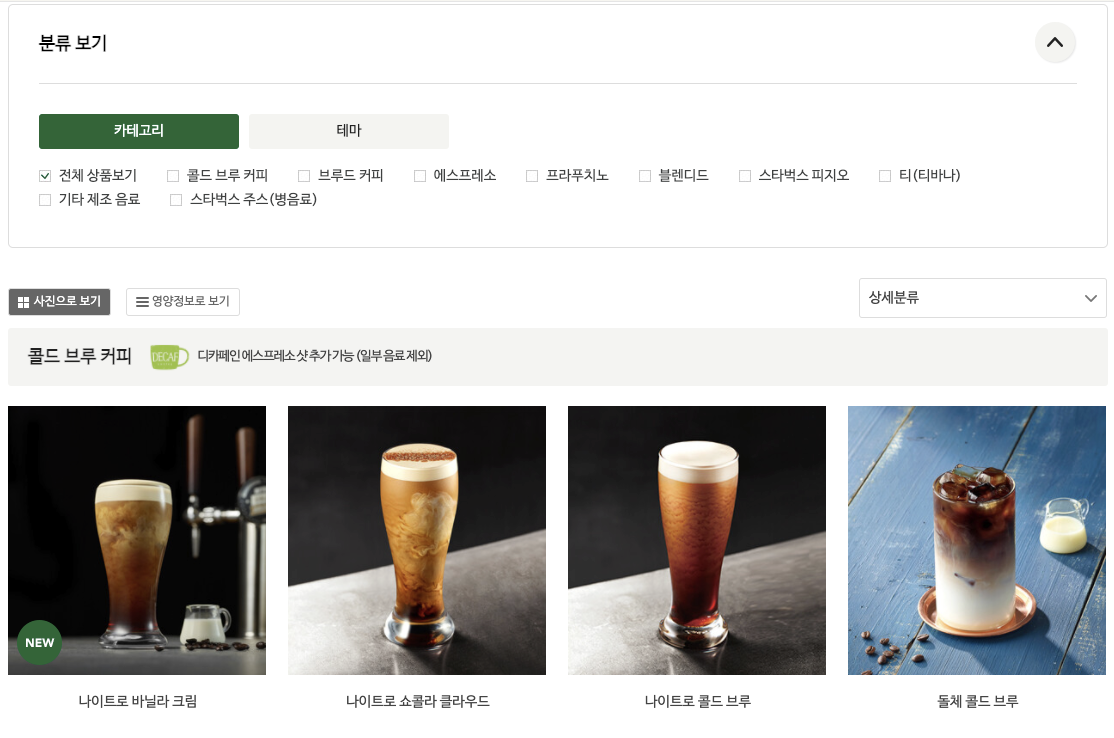
우선 어떻게 크롤링을 해올지 생각을 해보자.
각 카테고리에 해당하는 음료를 가져와야 하므로, 카테고리 & 음료를 가져올 방법을 찾아야한다
내가 항상 하는 생각, 구구단 돌리듯이!
nested for loops를 사용해야 하는데 구조는 다음과 같은 형식일것이다
for i in 카테고리 개수: -> for loop (1)
for j in 음료 개수: -> for loop (2)전체 카테고리 개수를 먼저 파악한 뒤, for loop (1)을 돌고
해당 카테고리 내 음료의 개수만큼 for loop (2)를 도는 구조!
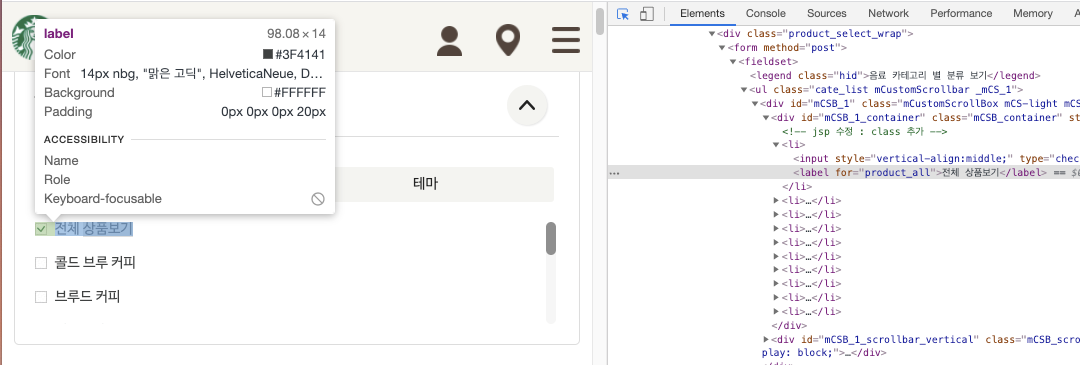
개발자도구를 통해 카테고리 요소의 선택자를 파악해보쟈
나는 li 요소로 반복문을 돌렸지만, 정확히 하고싶다면 li의 자식 요소인 label까지 하는것이 맞다.
(뭐 코딩에 정답이 어디있겠나 싶지만 그래도..!)
5. 선택자 가져오기 (2)
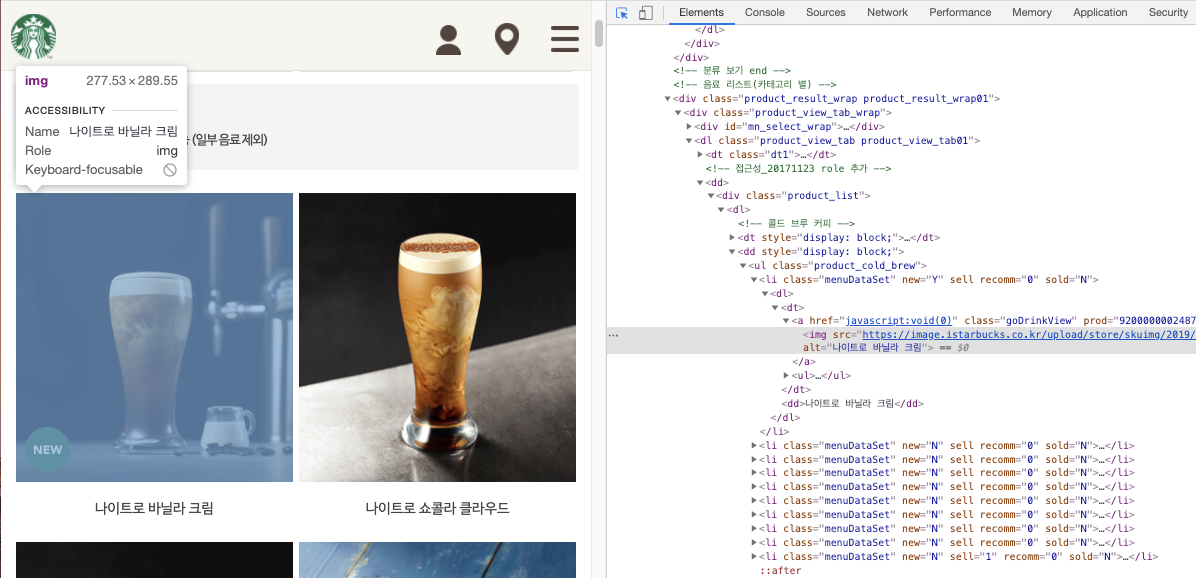
이제 각 카테고리에 속하는 음료 요소를 가져올 차례!
처음엔 이부분이 너무 헷갈려서.. 제일 많이 헤맸던 것 같다
스타벅스 홈페이지는 dt, dd 두 요소가 번갈아가면서 쓰이기 때문에 css nth-child 속성이 짝수 단위로 작성된 상황이었다.

👆🏻 요로케!
- 파이썬은 중괄호 사용시 꼭
f'....'이러한 형식으로 작성해주어야 한다!
계속 잘못된 코드를 입력했다고 에러가 떠서 멘탈이 나가있었는데
알고보니 내가 중괄호를 사용하는데f'....'로 감싸주지 않았기 때문에,
중괄호가 시작되는 부분부터 선택자로 인식되지 않았던 것!
6. CSV 파일에 데이터 출력하기
각 카테고리 내 음료 개수만큼 데이터를 가져와서
해당 내용부분을 csv 파일 내에 입력해주겠다는 뜻!
남들 다 CRUD (2) 하는데 꿋꿋이 혼자 크롤링한 나..
지금까지 한번도 해본적 없는 기능이어서 너무 신기하고 재미있게 했던 것 같다
더 열심히 연습해서 나중엔 척척 해낼 수 있도록 해야지 ㅎㅅㅎ
