1. 결측값 처리하기
(1) is.na(): NA 값을 조사해 논리값으로 반환 (NA=TRUE)
(2) complete.cases(): NA 값을 조사해 논리값으로 반환 (NA=FALSE)📌!is.na()
(3) 특정값을 결측 처리
iris[iris$sepal.length == 4.0] <- NA # 특정값 4.0을 NA 처리 (4) 데이터 프레임에서 결측값만 선택 또는 삭제하기
iris_na <- iris
iris_na[c(10, 20, 30), 3] <- NA # iris 3번째 변수 Petal.Lenght의 10, 20, 30번째 행을 NA(결측처리)iris_na[!complete.cases(iris_na),] # NA(결측) 행만 추출
iris_na[complete.cases(iris_na),] # NA(결측) 제외한 행 추출(5) na.omit(): NA가 있는 행 전체 삭제
(6) na.rm=TRUE: na.rm은 NA 값이 있을 때 해당 값을 연산에서 제외할 것인지를 지정하는 데 사용 (remote)
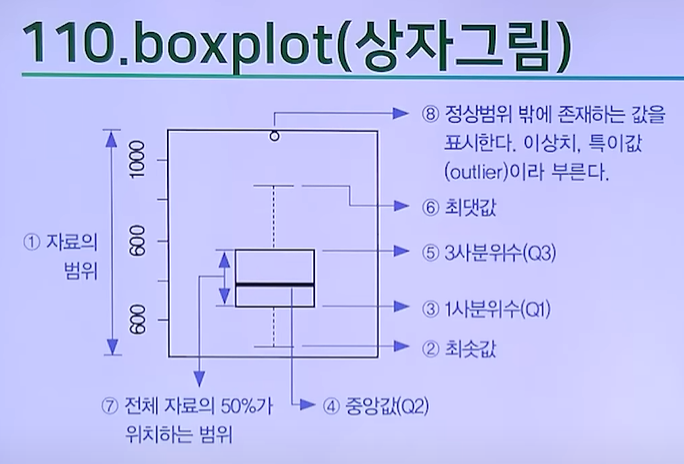
(7) boxplot(): 시각화하기
boxplot(수치형자료 ~ 범주형자료, 데이터명)(8) 0/0의 R 출력값은?
: NaN(Not a Number)으로 정의되지 않거나 할 수 없는 결과를 수학 연산으로 나타내는 데 사용
(9) 다음 R의 출력 결과는?
m <- matrix(1:6, nrow=3)
m
m[m[,1]>1 & m[,2]>5,] 
(10) 데이터 프레임 VS 벡터
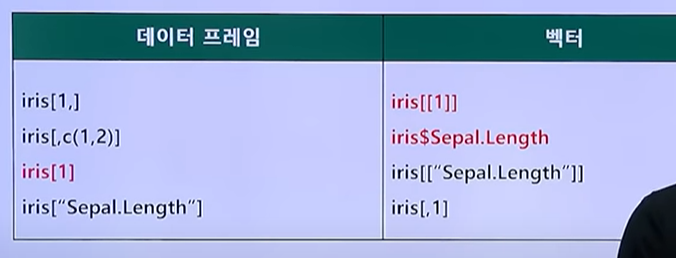
(10-1) 벡터의 연산 (벡터들 길이가 동일하지 않은 경우)
두 벡터의 원소 개수가 다르더라도 연산과정에서 원소의 개수가 적은 쪽의 벡터는 원소 개수가 많은 쪽의 벡터와 동일하게 원소의 개수가 맞춘다.
x <- c(1, 2, 3) y <- c(1, 2, 3, 4, 5, 6)📌 What is the value of x+y?
2 4 6 5 7 9
(11) 데이터의 종류
- 한가지 유형 데이터 타입만 가능한 것은? 벡터, 행렬, 배열
- 리스트, 데이터프레임, 데이터 테이블은 복수의 데이터 타입이 가능하기 때문에 복합형이라고 한다.
- R에서 결측값은 NA, NaN은 수학적으로 불가한 수를 표시할 때 NULL은 데이터 유형과 자료의 길이도 0인 비어 있는 값을 의미한다.
- 난수 발생시 동일한 난수가 발생되도록 초기화하는 R 함수: set.seed()
(12) 데이터 분포의 흩어짐 (산포)
- 변동계수: 표준편차/평균, 측정단위가 서로 다른 데이터를 비교할 때 사용
- IQR(사분위수범위): Q3-Q1
- 범위: 최대값 - 최소값
- 왜도: 정규분포이면 왜도는 '0','0'보다 크면 왼쪽으로 치우친 분포
- 첨도: 첨도가 3보다 크면 정규분포보다 뾰족한 모양
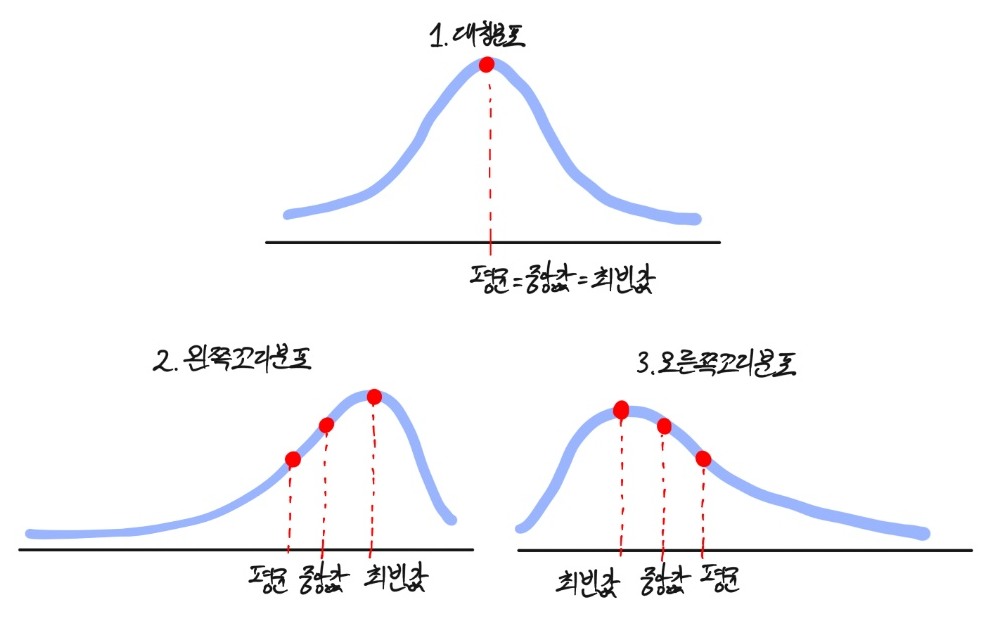
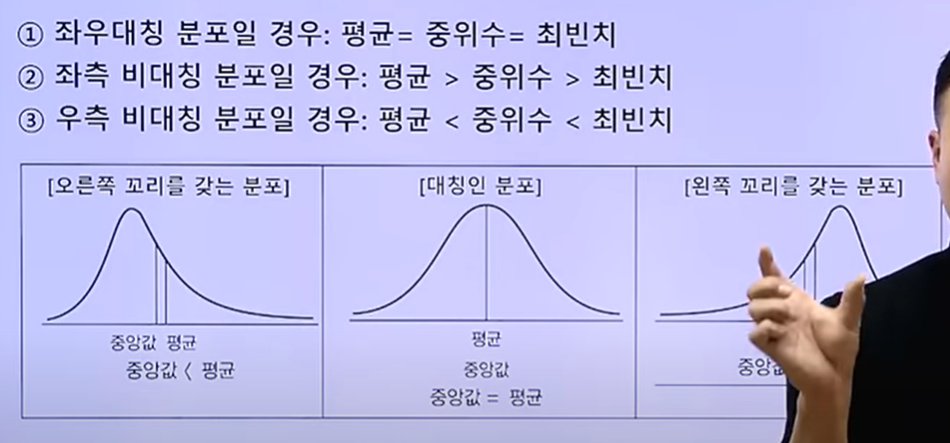
(13) boxplot(상자그림)
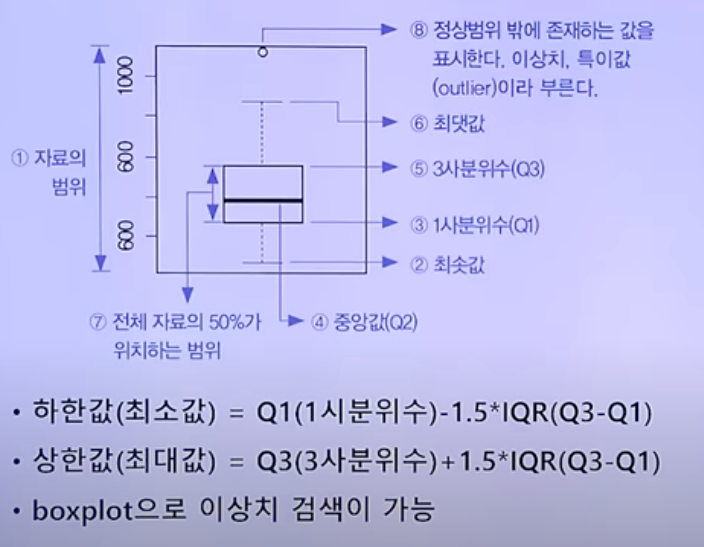
(14) Plyr 패키지
-
apply 함수에 기반해 데이터와 변수를 동시에 배열로 치환 split -> apply -> combine 기능 제공, 즉 데이터 분할 -> 함수를 적용 -> 재결합
-
ddply (d(데이터프레임) 입력 받아서 d(데이터프레임 출력))
-
apply(x, margin, fun): margin 1이면 = '행', margin 2이면 = '열'
Chapter 2. R의 특수한 기능
1) paste() 함수
우리가 정의한 벡터의 원소에 무언가를 붙이거나 벡터의 원소를 하나로 합쳐주는 기능
number <- 1:5
alphabet <- c("a", "b", "c")
paste(number, alphabet)
> "1 a" "2 b" "3 c" "4 a" "5 b"
paste(number, alphabet, sep = "to the") # 'sep =' 옵션을 통해 붙이고자 하는 문자열들 사이에 구분자 역할
> "1 to the a" "2 to the b" "3 to the c" "4 to the a" "5 to the b"2) substr(x, start, stop)
문자형 벡터 x의 start 에서부터 stop 까지만 잘라오기 (부분 선택)
country <- c("korea", "Japan")
substr(country, 1, 2)
> "ko" "Ja" # country 국가명에 1번 글자부터 2개의 글자만을 추출한 결과 3) strsplit(x, split = ",")
문자형 벡터 x를 split 기준으로 해서 나누기
nation <- c("korea,seoul", "japan,tokyo")
nation_split <- strsplit(nation, split=",")
nation_split
> [[1]] [1] "korea" "seoul"
[[2]] [1] "japan" "tokyo"4) R에는 4가지 정규분포 관련된 함수가 있다.
-
rnorm(난수함수): 난수함수는 정규분포함수의 변수에 해당하는 값을 임의로 생성해주는 함수, default 값은 '표준정규분포'로, 평균과 표준편차를 설정해줄 수 있다.
-
dnorm(확률밀도함수): 확률밀도함수의 함수값을 구해준다. 확률밀도함수이기 때문에 값 자체가 확률을 의미하지는 않는다. 디폴트 평균이 0이니까. 최댓값은 0에서 발생한다.
-
pnorm(누적분포함수)
-
qnorm(분위수함수): 확률이 입력변수이다. 어떤 확률을 입력하면 그에 해당하는 변수값을 찾아준다.
4가지 함수 모두 정규분포에 해당한다.
5) 척도 4가지 (명목척도 & 구간척도)
(1) 명목척도란?
'이름'만 나타내는 척도를 말한다. 숫자로 표현할 수도 있지만 숫자는 분류의 기능만 할 뿐 양적인 의미는 없고 특정 카테고리만 표현한다.
예) 성별 (남 0, 여 1), 취미 (운동 0, 독서 1, 미술 2)
(2) 구간척도란?
연속적인 수로 수량화할 수 있으며 절대적인 원점이 존재하지 않는다. 어느 정도 크고 작다를 표현할 수 있다. 숫자 간의 간격이 동일하다.
에) 절대적인 원점이 없기 때문에 온도 0도는 온도가 없다고 할 수 없다.
https://benn.tistory.com/14 (척도 4가지)
6) 이상값(outlier)
-
이상점은 다른 자료와는 극단적으로 다른 값, 상자그림에서 상(하)사분위수로부터 1.5xIQR[2] 만큼 떨어진 거리보다 더 먼 곳에서 발견되는 관측값으로 정의된다.
-
이상값 탐색 관련 알고리즘 중 ESD의 경우 평균으로부터 3개 표준편차만큼 떨어져 있는 값들을 이상값으로 판단한다.
-
부정사용방지 시스템이나 부도예측시스템에서는 이상값은 의미가 있으므로 무조건 제거하지 않는다.
R Keyword
1) na.rm (remote)
https://m.blog.naver.com/definitice/221110638186
1) 사분위수(IQR)란?

변동계수 : https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sgy614&logNo=220793894083
2) 왜도란?
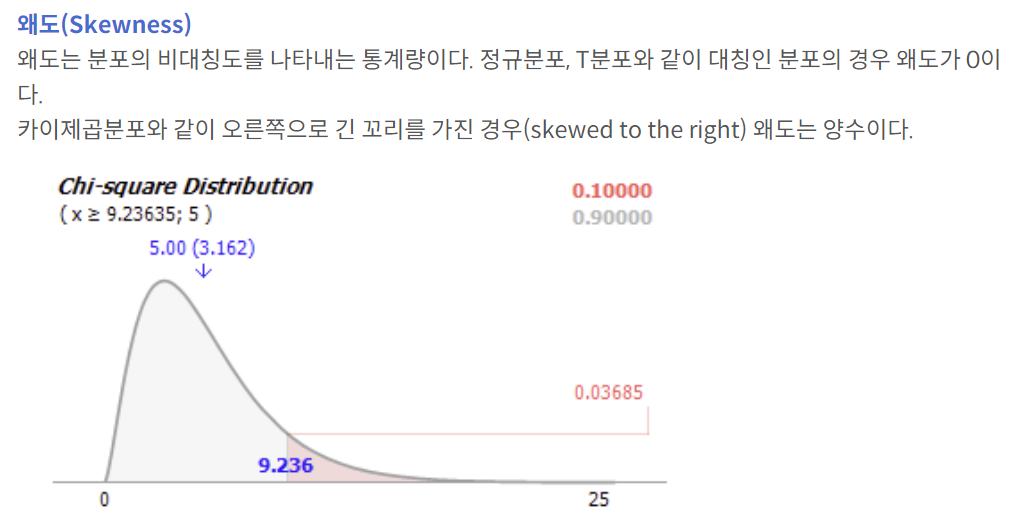
분포의 비대칭도를 나타내는 통계량이다. 정규분포, T분포와 같이 대칭인 분포의 경우 왜도가 0이다. 카이제곱분포와 같이 오른쪽으로 긴 꼬리를 가진 경우 왜도는 양수이다.
3) 첨도란?
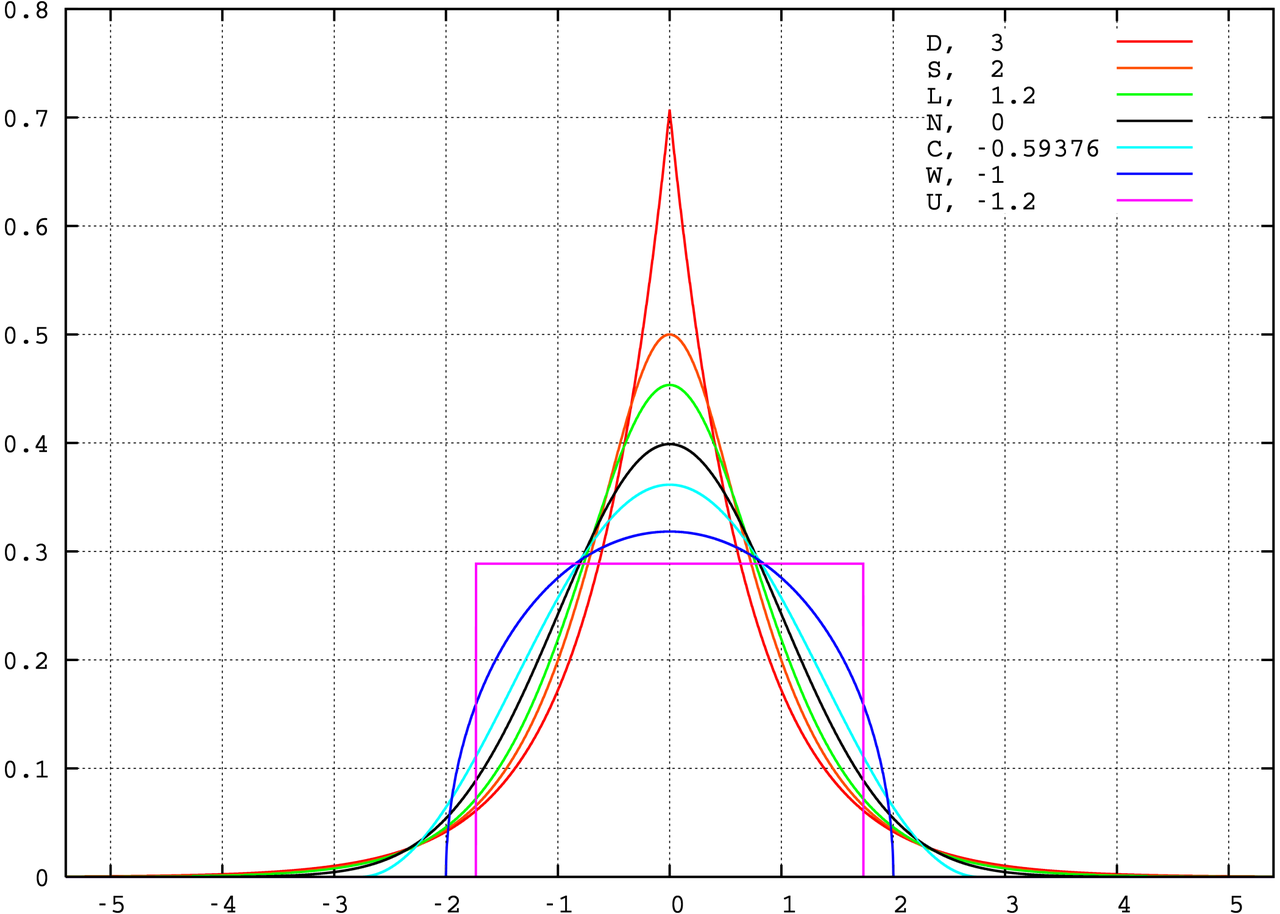
분포의 꼬리부분의 길이와 중앙부분의 뾰족함에 대한 정보를 제공하는 통계량이다. 아주 well-defined된 통계량이 아니기 때문에 여전히 해석에 논란의 여지가 있다.
정규분포의 첨도는 0이다. (기본적인 정의에 의하면 3이지만, 일반적으로 정규분포의 첨도를 0으로 만들기 위해 3을빼서 정의하는 경우가 많다) 첨도가 0보다 크면 정규분포보다 긴 꼬리를 갖고, 분포가 보다 중앙부분에 덜 집중되게 되므로 중앙부분이 뾰족한 모양을 가지게 된다. 반대로 첨도가 0보다 작으면, 정규분포보다 짧은 꼬리를 갖고 분포가 중앙부분에 더 집중되어 중앙부분이 보다 완만한 모양을 가지게 된다.
4) 결측값
우리가 구하는 데이터셋에서는 비어있는 데이터가 있을 수도 있고 이상한 값이 들어있는 데이터도 있을 것이다. 이런 부분들은 계산을 못하게 하거나 분석결과가 엉뚱하게 나오는 결과를 초래한다. 이런 잘못되어 있는 값을 '결측값(missing data)'라고 한다.
5) x <- matrix(c(1:12), 3, 4)

min(apply(x, 1, mean)) + max(apply(x, 2, mean)) https://acdongpgm.tistory.com/82
5-1) apply(X, MARGIN, FUN)
- X: matrix, array 형태의 데이터
- MARGIN: 1은 행, 2는 열을 의미하며 이 둘 중 하나를 입력하면 행 또는 열 기준으로 FUN에 주어진 함수 실행
- FUN: 적용할 함수
5-2)
- mean() :평균
- median(x) : 중앙값
6) 데이터프레임과 벡터
7) 중앙값 또는 중위수
: 어떤 주어진 값들을 크기의 순서대로 정렬했을 때 가장 중앙에 위치하는 값을 의미한다.
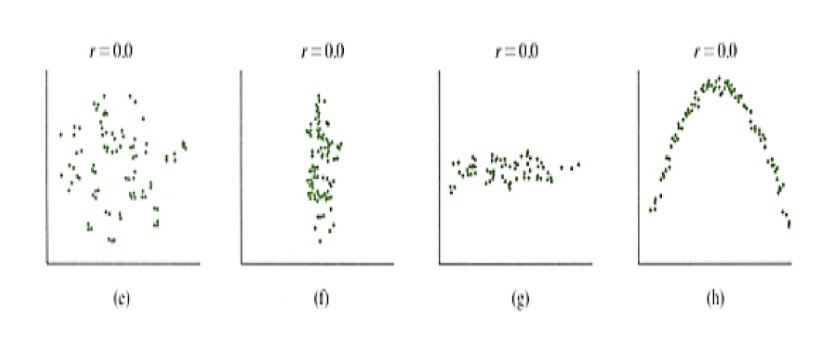
8) 산점도 (Scatter Plot)
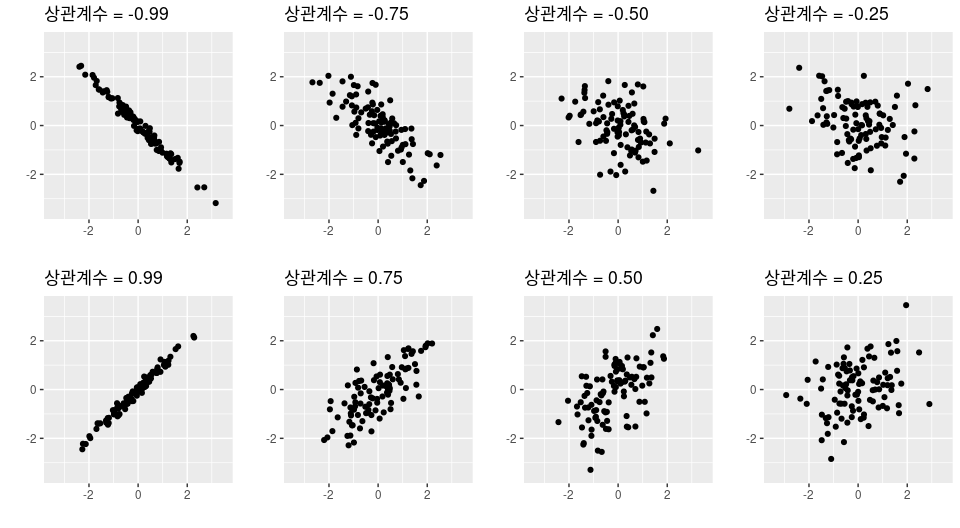
직교 좌표계(도표)를 이용해 좌표상의 점(點)들을 표시함으로써 두 개 변수 간의 관계를 나타내는 그래프 방법이다.
9) melt() & cast() 함수
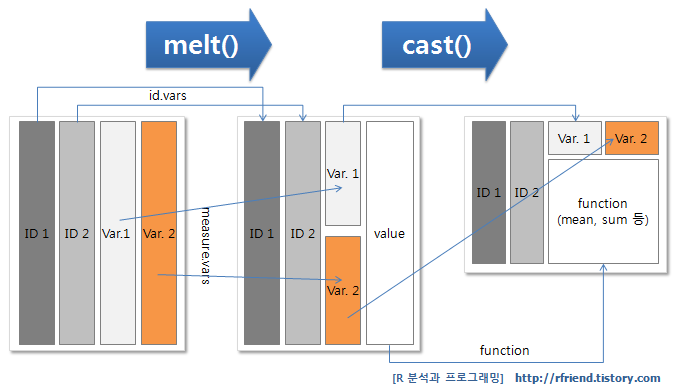
https://www.youtube.com/watch?v=p7pe6HDOnjM
10) 상자그림 (boxplot)

소중한 정보 잘 봤습니다!