인턴
1.Log, Metrics and Tracing
시스템 프로세스의 개별 이벤트를 기록하는 것예를 들어 애플리케이션이 충돌하면 로그 메시지가 생성되고 수집되어 향후 처리이 메시지의 내용은 충돌이 발생한 시간과 응용 프로그램이 충돌한 페이지/파일일 수 있음. 나중에 해당 로그를 분석하고 이들 사이에 상관 관계가 있는지
2.Observability

오직 시스템의 외부 출력만을 이용해서 시스템의 현재 상태를 이해할 수 있는 능력애플리케이션의 내부 동작을 이해함Understand the inner workings of your application애플리케이션이 처할 수 있는 모든 시스템 상태를 이해함Understan
3.중앙집중식 로깅
시스템이 쪼개지고 다루기 쉬워졌지만 그만큼 복잡해졌고 이러한 특징 때문에 MSA에 대한 로깅과 모니터링은 큰 고민거리라고 한다.Because:서로 다른 개별 마이크로서비스에서 발생하는 로그를 연결지어 트랜잭션의 처음부터 끝까지 순서대로 추적해내는 것은 어렵기 때문The
4.Anomaly Detector 대안 (Metric)
https://blog.naver.com/alice_k106/221910045964https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/https://github.
5.Prometheus Alerting with AlertManager
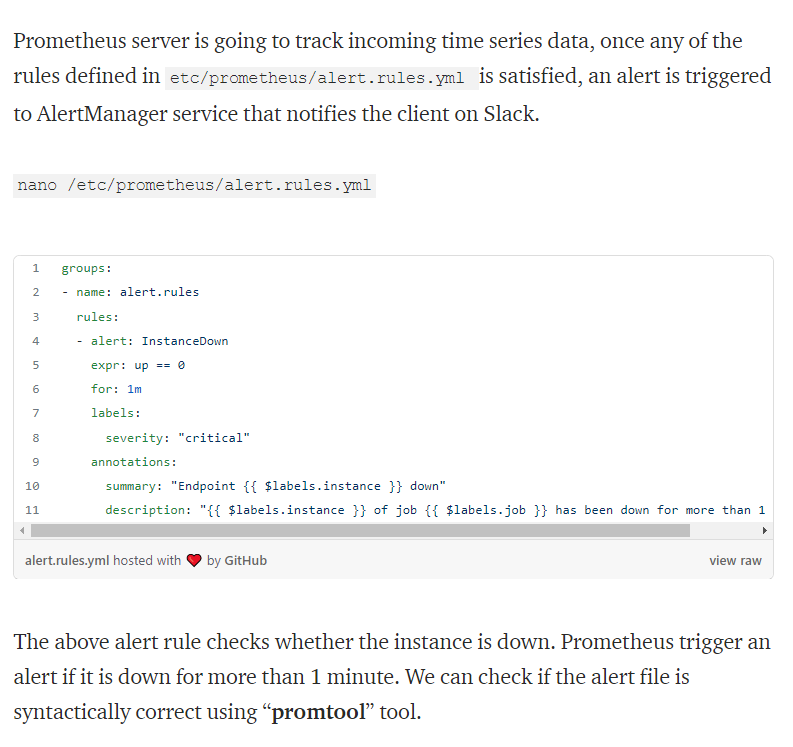
Alert manager 자체는 알림을 전달하는 역할이다. prometheus 서버에 config를 해주어야하는데 그게 바로 alert rule 파일, 즉 manager와는 별개로 manager과 서버를 연결 시켜주는것이당https://medium.com/de
6.Prometheus alert state
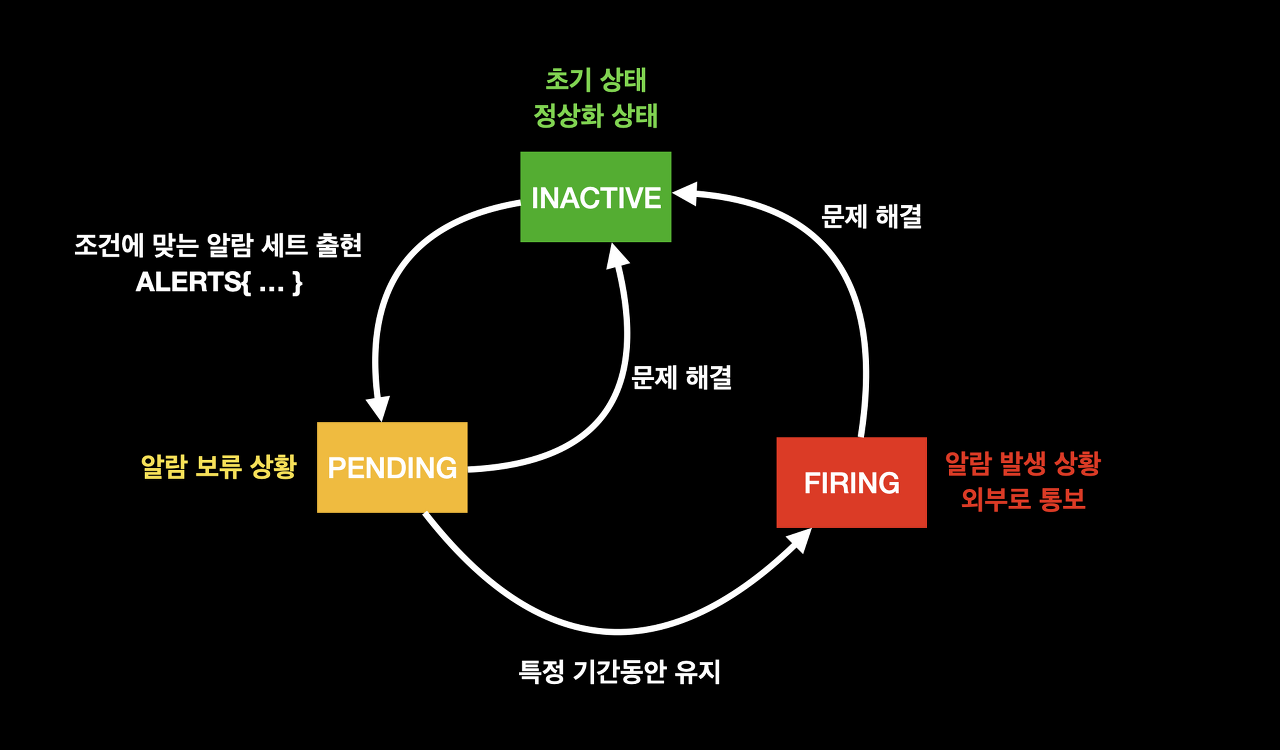
알람 조건에 맞는 알람 세트가 없음. 정상 상태.알람 조건에 충족하여 알람 세트가 생성된 상태이다. Alert Rule에 정의된 "for" 기간 동안 이 상태를 유지하게 되면 "FIRING" 상태가 된다."PENDING" 상태가 주어진 기간동안 유지될 경우, 이 상태로
7.[SSH] 서버 콘솔에 원격으로 접속하기
웹 콘솔 있는데 굳이 왜why? 터미널 복붙 기능 사용하는게 훨씬 편리하니까.ssh_exchange_identification: read: Connection timed out 오류! 내 ip랑 sqiproject 서버에 접속하는 네트워크 방화벽이 막혀있었던 것! 어떻
8.Prometheus expressions
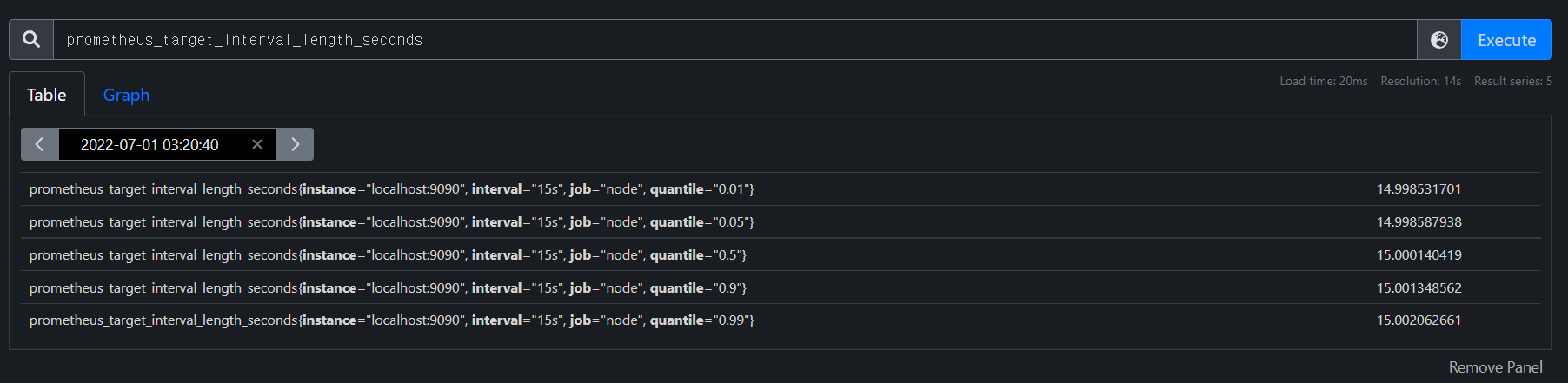
actual amount of time between target scrapes보면 labels가 다 다른데, 각각 latency percentiles와 target group intervals에 맞게 뜬다.If we are interested only in 99th
9.리눅스 백그라운드 실행
뭐가?조금 민망하지만 이게 prometheus를 실행했을때도 그렇고, graphana를 실행했을 때도 그렇고,이렇게 터미널에서 해당 서비스들의 실행 명령어가 다 뜬 상태같은데,엔터를 치거나 다른 명령어를 쳐도 안먹힘. 왜?이게 지금 서비스가 실행되는 상태라 stdout