
캐시는 작고 소중해.
캐시는 메모리보다 용량이 작다. 메인메모리에서 필요한 데이터를 가져와서 어떻게 캐시에 올려놓냐에 따라서 속도와 효율이 크게 바뀔것이다. 오늘은 주 메모리의 데이터를 캐시로 올리는 방법중 하나인 Direct Mapping을 배워보겠다.
빠르게, 더 빠르게
데이터를 가져오는 속도를 빠르게 하려면 어떻게 해야할까? 프로세서가 필요한 데이터를 메모리까지 내려가서 찾지 않고 캐시에서 찾아오면 빨라질 것이다. 캐시에 필요한 데이터가 있을 확률을 높이기 위해서는 두가지 방법을 생각해 볼 수 있다. 바로 캐시의 용량을 키우는 것, 그리고 예측을 잘 하는것 이다.
돈이 많으면??
지난번에 캐시 포스팅에서 저장장치 딜레마 이야기를 다루었다. 속도가 빠르면 용량이 작아지고 비싸진다. 그러나 돈만 많이 쓴다면 크고 빠르고 큰 저장장치를 얻을 수 있지 않을까? 대답은 "굳이?" 이다.
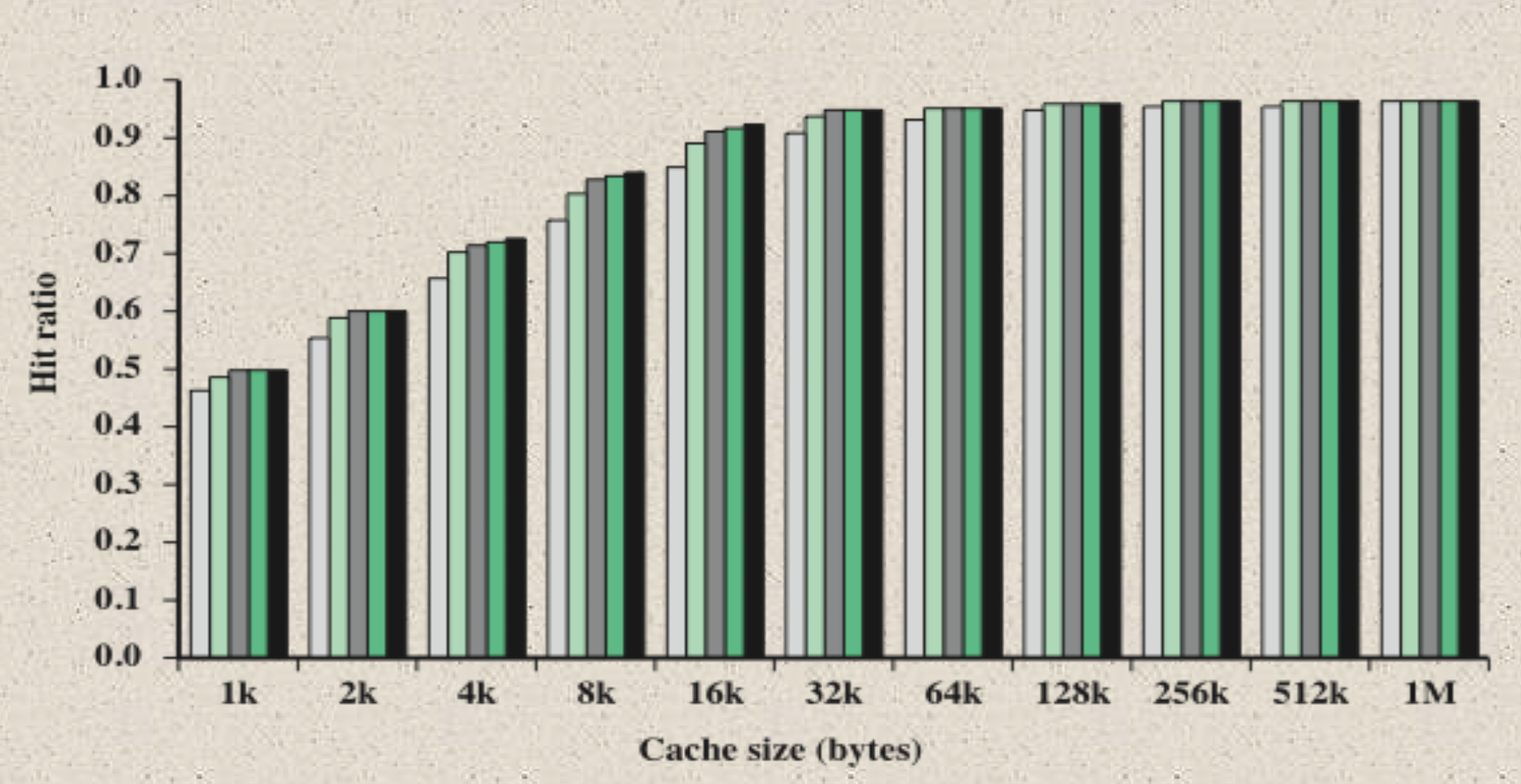
x축은 캐시의 크기이고 y축은 메모리까지 가지 않고 캐시에서 필요한 데이터를 얻을 확률이다. 캐시 용량이 16k까지는 확률이 증가하지만 32k를 넘어가면 거의 증가하지 않는다. 따라서 캐시의 용량을 키우는 것은 근본적인 해결책이 되지 못한다.
Mapping Function
다시 말하지만 캐시는 메모리보다 용량이 작다. 메모리가 j개의 블럭(Block)으로 캐시가 m개의 라인(Line)으로 되어있다고 하면 m <<<< j 이다. 따라서 m개의 라인에 j개의 블럭을 적절히 넣어가면서 사용할 필요가 있다. 우리는 기준을 정해야 한다. 오늘 주제인 Direct Mapping은 그 기준을 모듈로(%) 연산자로 사용한다.
Block과 Line 그리고 word
블럭(Block)과 라인(Line), 워드(word)라는 단위가 있다. 이 단위를 잘 알고 있어야 뒤의 설명을 따라갈 수 있다.
워드(word)는 하나의 기계어 명령어나 연산을 통해 저장된 장치로부터 레지스터에 옮겨 놓을 수 있는 데이터 단위이다.
블럭(block)은 하나의 단위로서 다룰 수 있는 문자, 워드, 레코드의 집합이다.
라인(Line)은 주 메모리의 데이터를 읽어들이는 최소 단위이다.
출처 : 위키백과
워드는 레지스터에 실행될 연산자나 데이터가 담긴 데이터의 단위이다. 라인은 캐시가 메모리를 읽어올때 가져오는 최소단위이고 이 단위는 블럭과 같다. 라인과 블럭은 여러개의 워드로 구성되어져 있다.
정해진 자리
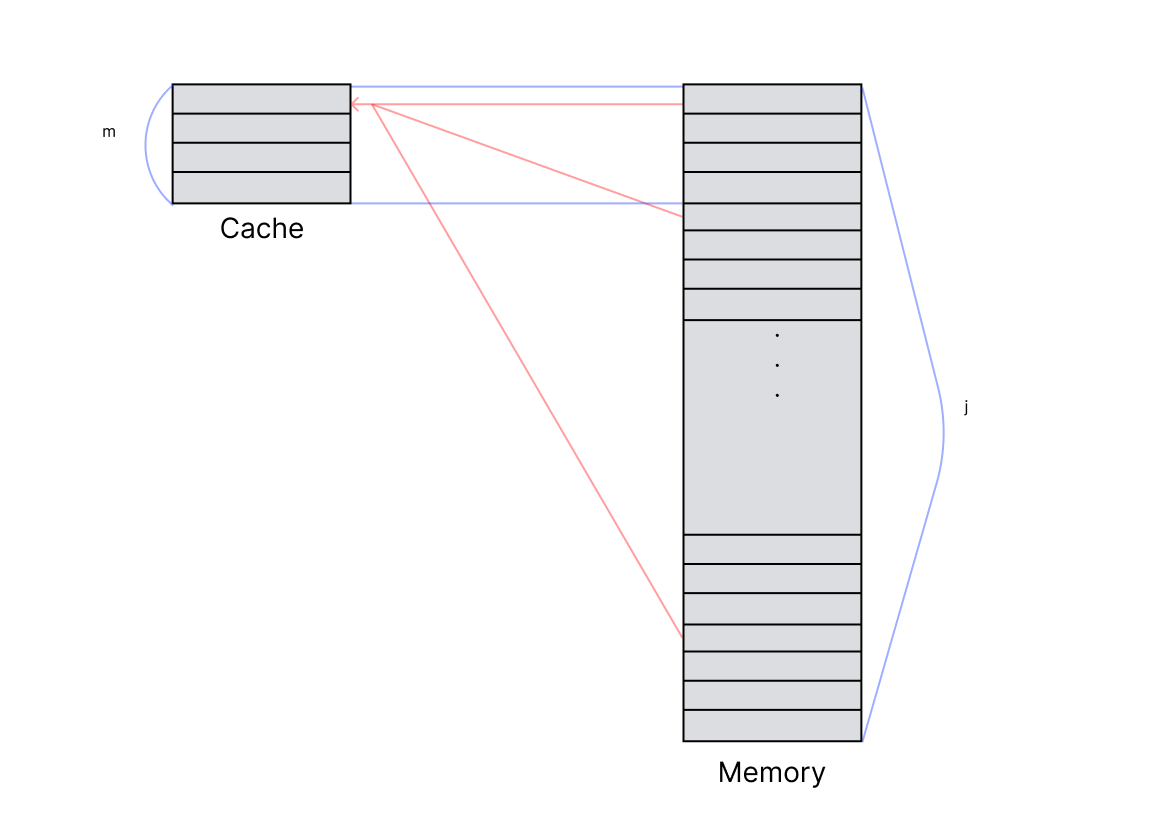
위의 그림이 Direct Mapping을 설명해준다. 우선 왼쪽 캐시에서 한칸이 Line, 오른쪽 메모리의 한칸이 Block이다. 라인과 블럭의 단위는 같다. 따라서 라인에 하나의 블럭을 적으면 메모리의 블럭의 갯수 j가 캐시의 라인수 m보다 훨신 많기때문에 모듈로 연산자를 이용해 블럭이 라인에 들어갈 자리를 정한다. m = 4고 j = 1024면 1번 블록은 1번 라인으로, 2번블록은 2번라인으로 3번블록은 3번라인으로, 4번블록은 4번라인으로 5번블록은 1번라인으로, 6번블록은 2번라인으로... 이런식으로 들어갈 자리가 정해진다. 여기서 1번 라인에 1번 블록이 저장되어있었는데 지금 필요한 데이터가 5번 블록에 있다고 하면 캐시에 있던 1번 라인은 1번 블록의 내용을 지워버리고 5번 블록의 내용을 적는다.
Line Number
캐시에 m = 4 개의 라인이 있다 하면 이 라인을 구분하기 위해 2개의 비트가 필요할 것이다. (00, 01, 10, 11 로 구분) 이 2비트를 Line Number라고 한다. Line Number는 결국 위의 모듈로 연산의 결과와 같다. 즉 n번째 블럭이 캐시에 들어갈 Line Number는 n % m이다.
Tag
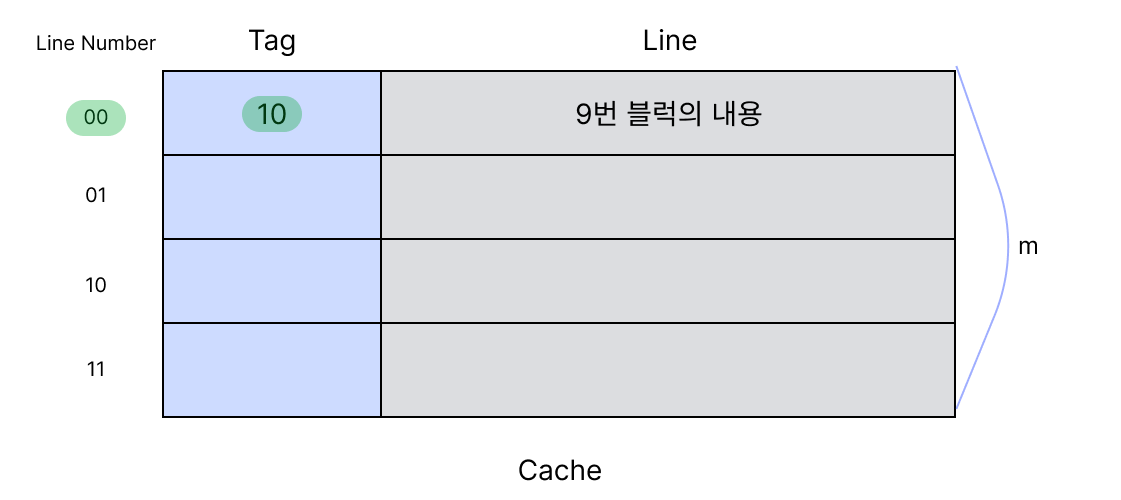
n번째 블럭이 n % m인 Line Number에 저장된다는 것을 알았다. 그런데 프로세서가 캐시 메모리를 참조했을때 이게 자신이 필요한 데이터인지를 확인하기 위한 정보가 아직 부족하다. 예를 들어보자. 9번 블럭의 정보를 프로세서가 원하고 있다. 프로세서는 메모리를 참조하기전에 캐시를 먼저 확인한다. 9번 블럭의 정보는 1번 라인에 저장되있을 것이다. (9 % 4 = 1) 그런데 프로세서 입장에서는 1번 라인에 있는 값이 9번 블럭의 내용인지, 5번블럭의 내용인지, 1번 블럭인지, 41번인지 확인할 방법이 없다. 그래서 캐시에는 Tag라는 항목이 필요하다. Tag에 9 / 4의 결과인 2를 적어준다. (이진법으로 10) Tag를 보고 프로세서는 이것이 9번 라인에 적혀있는 내용인지 아닌지 확인 할 수 있다.
Block offset
컴퓨터 과학에서 배열이나 자료 구조 오브젝트 내의 오프셋(offset)은 일반적으로 동일 오브젝트 안에서 오브젝트 처음부터 주어진 요소나 지점까지의 변위차를 나타내는 정수형이다.
Block offset은 프로세서가 필요로 하는 변수가 블럭안에서 몇번째 바이트에 있는지 알려준다. 이건 배열의 인덱스 같은 개념이라고 생각하면 편할것 같다.
프로세서가 되어서 01100000 주소 가져와 보기 (Hit)
프로세서 마다 주소의 길이는 다르다. 우리의 시스템의 주소는 다음 형식이다.
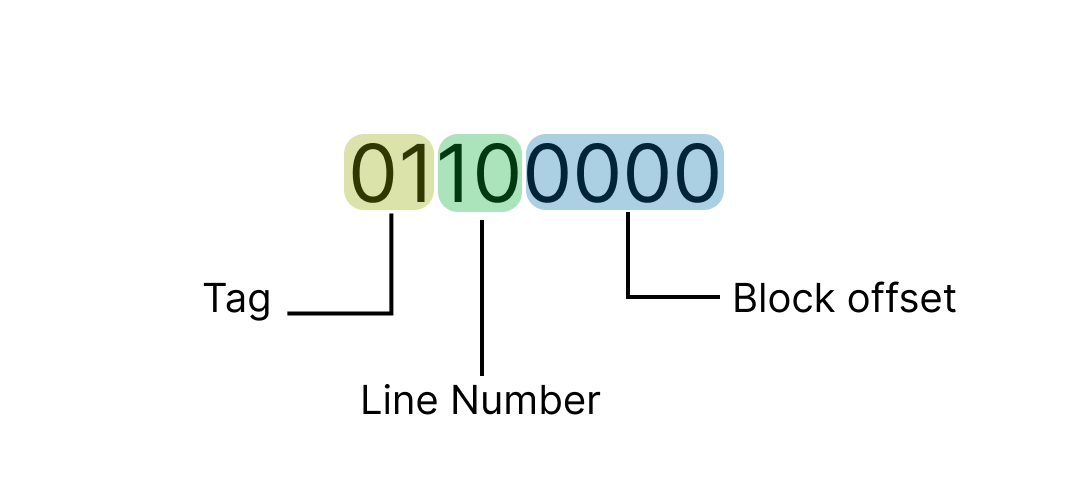
우선 프로세서는 가운데 있는 Line Number를 읽는다. Line Number에 해당하는 라인의 Tag 값을 확인한다.
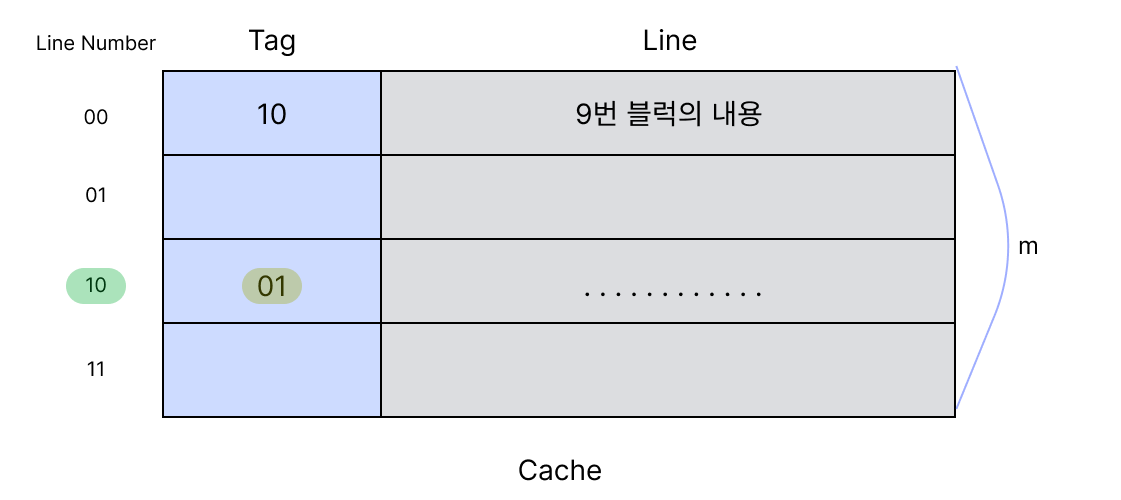
Tag값을 확인하니 01이다. 이제 프로세서가 가지고 있는 Tag값과 비교한다. 일치한다! 이런경우를 Hit이라고 한다. Hit일 경우에는 캐시에 필요한 데이터가 있었기때문에 메모리까지 갈 필요없이 캐시에서 정보를 가져온다. 이제 Block off에 해당하는 byte를 읽어오면 끝난다.
01000100 주소 가져와 보기 (Miss)
위와 같이 우선 Line Number를 읽는다. 00번의 라인으로가서 Tag 10을 읽는다. 이제 프로세서가 가지고 있는 Tag값 01과 비교한다. 다르다.
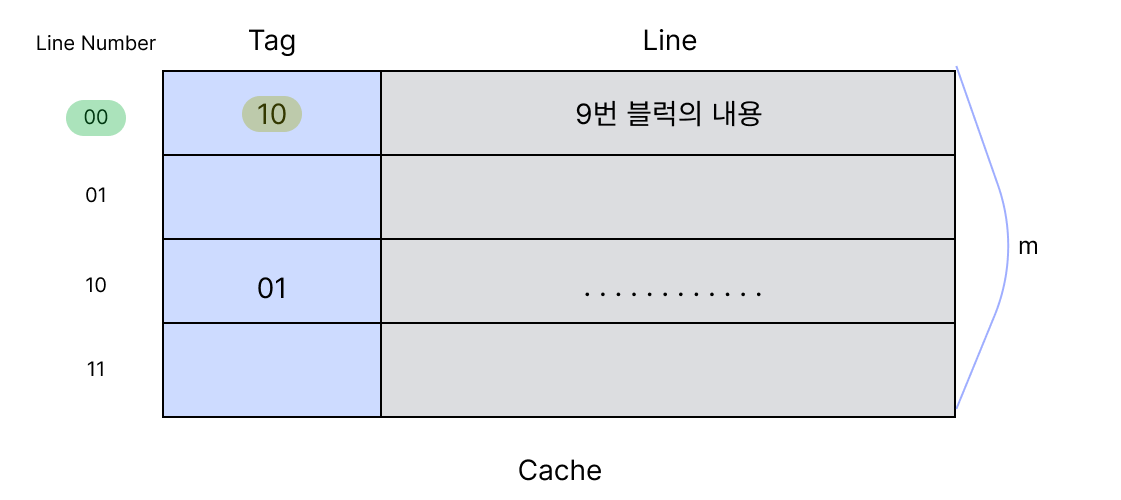
이런경우를 Miss라고 한다. Miss가 발생하면 메모리에 가서 값을 읽어야한다. 메모리의 0001번 블럭으로 가서 이 블럭의 값을 00번 라인으로 Mapping 해온다.
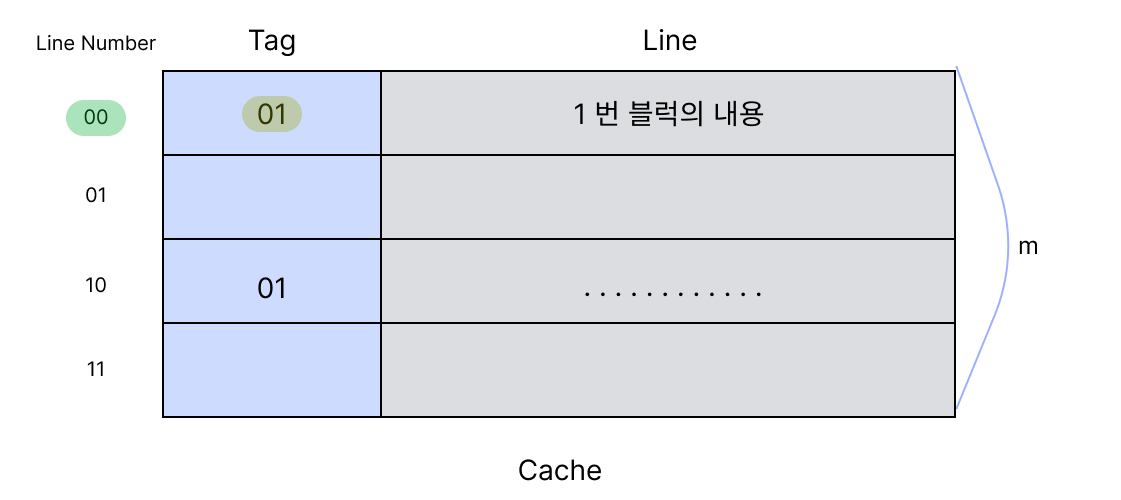
이제 캐시에 올라온 00번 라인의 0100번 offset을 읽는다.
Miss에서 조심할 점은 캐시에 없는 내용을 메모리에서 받아올때 바로 프로세서로 넘기는것이 아닌 캐시에 저장한뒤 캐시를 읽는다는 것이다.
Direct Mapping의 문제점
직접 사상 캐시에서, 만약 어느 프로그램이 같은 라인에 사상되는 두 개의 블록들로부터 단어들을 반복해서 읽어와야 한다면, 그 블록들은 캐시에서 반복적으로 교체(swap)될 것이다. 결과적으로 적중률(hit ratio)이 낮아지게 되는 스레싱(thrashing) 현상 발생한다. 이를 해결하는 방법으로 Victim Cache를 이용하는 방법이 있다. Victim Cache는 직접 설명하지 않고 정리되어 있는 블로그를 남기겠다.
