아파치 스파크Apache Spark는 빅데이터와 오픈소스 소프트웨어의 중요한 요소입니다. 빅데이터 분석 분야에서 많이 사용되고 있으며, 관심과 사용도는 빠르게 증가하고 있습니다. On-Premise에 구성하여 사용하기도 하고 클라우드 서비스 프로바이더CSP, Cloud Service Provider에서 제공하는 PaaS 서비스로 이용 가능합니다. AWS EMR, Azure HDInsight, Google Cloud Dataproc, Oracle Cloud Dataflow가 있습니다. 요즘 시대에 사는 개발자/엔지니어라면 아는 척을 할 수 있어야 하겠지요.
분산 처리의 시작
개척 시대에는 무거운 짐을 싣기 위해서 소를 이용했는데, 한 마리의 소를 이용해서 짐을 실을 수 없을 경우에는 더 힘이 센 소를 찾는 대신 여러 마리의 소를 이용해 짐을 옮기는 방법을 택했다. 마찬가지로 많은 양의 데이터를 처리하기 위해 더 큰 컴퓨터를 찾는 대신 더 많은 컴퓨터 시스템을 구축하기 위해 노력해야 한다.
그레이스 호퍼 제독 (Rear Admiral Grace Murray Hopper), 미국 컴퓨터 과학자
스파크는 빅데이터의 발전과 밀접한 관계가 있습니다. 스파크의 맵리듀스MapReduce 근간이 되는 하둡Hadoop은 구글Google과 야후Yahoo에 의해서 대중화가 되었습니다. 2003년에 구글이 발표한 논문 'The Google File System'과 이듬해에 발표한 논문 'MapReduce: Simplified Data Processing on Large Clusters'으로 시작이 되었습니다. 하둡 초기 개발자 더그 커팅Dough Cutting과 마이크 카파렐라Mike Cafarella는 아파치 루씬Apache Lucene을 기반으로 웹 크롤러 프로젝트 너치Nutch를 진행하였습니다. 그러는 와중에 구글의 논문에 감명(?)을 받아 야후에서 하둡을 출시하게 되었습니다.
아파치 하둡
하둡의 큰 특징 두 가지가 있습니다. 바로 데이터 지역성(Locality)과 비공유(Shared Nothing)입니다. 데이터 지역성을 지닌 데이터 저장/처리 플랫폼입니다. 데이터 원격 처리 시스템 또는 호스트로 이동하여 처리하는 기존 방식과 다르게, 데이터가 있는 곳으로 이동해서 계산하는 데이터 처리 방식입니다.
비공유는 클러스터에 각 노드가 독립적이며 CPU, 메모리와 같은 리소스를 노드 간에 공유하지 않고 처리할 수 있는 분산 파일 시스템입니다. 이러한 시스템 아키텍처로 데이터를 저장하고 처리하는데 불필요한 네트워크를 사용하지 않아 대역폭을 보존하며 데이터 접근성을 높였습니다.
하둡은 기록 연산 처리 관련 스키마가 없는 스키마-온-리드Schema-on-Read 시스템입니다. 비정형, 반정형 데이터부터 정형 데이터까지 광범위한 데이터를 저장하고 처리할 수 있습니다. 인덱스, 통계 구조를 가질 수 없습니다. HBase, Casandra 외에 NoSQL이 포함됩니다
이에 반대되는 스키마-온-라이트Schema-on-Write 시스템이 있습니다. Oracle Database, MySQL, MS-SQL 같은 관계형 데이터베이스를 생각하면 됩니다. 스키마는 작업 시 미리 정리가 되어 적용되는 형태입니다.
하둡은 큰 문제를 작은 문제의 집합으로 나누고 정리하며, 데이터 지역성과 비공유 개념을 적용합니다.
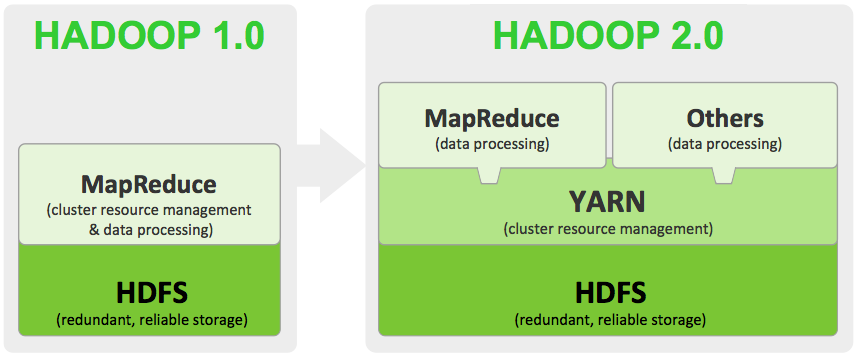
하둡의 핵심 구성요소가 있습니다. 하둡 분산 파일 시스템HDFS, Hadoop Distributed File System과 YARN, Yet Another Resource Negotiator입니다. HDFS는 하둡의 스토리지 서브시스템이며 YARN은 하둡의 프로세싱 또는 리소스 스케줄링 서브시스템입니다.
HDFS는 클러스터 하나 이상의 노드에 파일이 분산되어 있는 블록으로 구성된 가상 파일시스템입니다. 인제션이라는 프로세스는 파일시스템에 데이터를 업로드 할 때 구성된 블록의 크기에 따라 무작위로 파일을 나눕니다. 그 후에, 클러스터 노드 간에 블록을 분산 및 복제해서 내결함성을 달성하고, 데이터에 계산을 가져오는 목적으로 설계된 로컬에서 데이터를 처리할 수 있게 합니다.
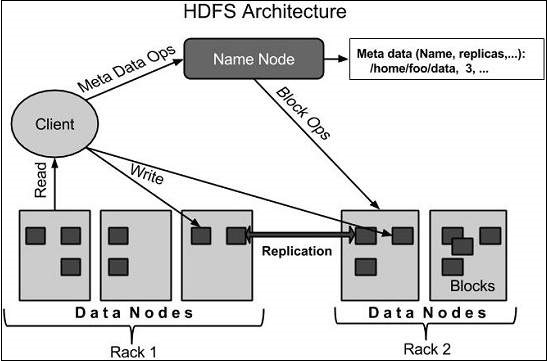
하둡에 구축된 스파크 응용 프로그램을 위해 분산 스파크 작업자Worker 프로세스에 파티션 형식의 입력 데이터 제공합니다. 물리적 블록의 정보는 메타데이터에 저장됩니다. 파일시스템에 메타데이터는 네임노드NameNode라는 HDFS 마스터 노드 프로세스의 상주 메모리에 저장됩니다. 네임노드는 관계형 데이터베이스 트랜잭션 로그와 유사한 저널링Journaling 함수를 통해 메타데이터에 대한 내구성을 제공하고, HDFS 클라이언트에 읽기 및 쓰기 작업을 위한 블록 위치를 제공합니다.
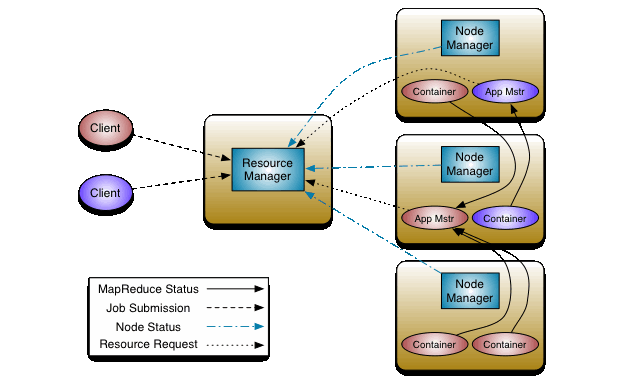
하둡은 HDFS에서 데이터를 가져오고, HDFS에 데이터를 기록합니다. YARN은 하둡의 데이터 처리를 제어하고 관리합니다. 마스터 노드 데몬인 리소스 매니저와 클러스터의 작업자, 슬레이브 노드에서 실행되는 노드 매니저라는 하나 이상의 슬레이브 노드 데몬을 포함합니다.
아파치 스파크
아파치 스파크는 하둡의 맵리듀스의 대안으로 만들어진 매우 효율적입니다. SQL 액세스, 스트리밍 데이터 프로세스, 그래프 및 NoSQL 프로세스, 머신러닝 등을 제공하여 데이터 처리에 뛰어납니다.
캘리포니아 대학교 버클리 RAD 연구소의 마테이 자하리아Matei Zaharia가 2009년에 시작한 오픈소스 분산 데이터 프로젝트로 시작하였습니다. 맵리듀스를 대체할 수 있는 리소스 스케줄링 및 오케스트레이션 시스템을 검토하도록 설계되었습니다.
하둡의 맵리듀스 구현의 주요 단점은 맵Map과 리듀스Reduce 처리 단계 사이의 중간 데이터가 디스크에 잔류하는 것입니다.
맵리듀스의 대안으로 스파크는 탄력적인 분산 데이터 집합RDD, Resilient Distributed Dataset이라고 불리는 분산형, 내결함성, 인메모리 구조를 갖습니다. 스파크는 메모리 사용을 극대화해 전반적인 성능을 크게 향상시킵니다.

하둡의 파일 I/O 중심의 맵리듀스 성능이 분산 메모리 성능으로 크게 개선 되었습니다.
스파크는 스칼라로 작성되었으며 JVM에서 실행됩니다. 그리고 다양한 프로그래밍 인터페이스를 지원합니다.
- Scala
- Python
- Java
- SQL
- R
스파크의 가장 큰 특징은 앞서 언급한 스파크RDD입니다. 스파크 응용 프로그램의 기본 데이터 추상화 구조로, 스파크와 다른 클러스터 컴퓨팅 프레임워크 사이의 주요 차별화 요소 중 하나입니다. 스파크RDD는 클러스터에 분산된 인메모리 데이터 모음으로 간주할 수 있습니다.
