multi columns
#multi 열
air_info.columns
MultiIndex([('CANCELLED', 'size'),
('CANCELLED', 'sum'),
('CANCELLED', 'mean'),
( 'AIR_TIME', 'mean'),
( 'AIR_TIME', 'var')],
)
level0=air_info.columns.get_level_values(0)
level1=air_info.columns.get_level_values(1)
air_info.columns=level0+'_'+level1groupby, 사용자정의 함수
flights.ARR_DELAY.between(-100,60).mean()
def pct_between(s): #입력은 시리즈
return s.between(-100,60).mean()
flights.groupby('AIRLINE')[['DEP_DELAY', 'ARR_DELAY']].agg(pct_between)
flights.groupby('AIRLINE')[['DEP_DELAY','ARR_DELAY']].agg(['mean', pct_between])
pct_between.__name__='Non_delay_Ratio'
# 다양한 종류의 agg
agg_format = {'Age':'max', 'SibSp':'sum', 'Fare':'mean']
titanic_df.groupby('Pclass').agg(agg_format)
f = tr.groupby('cust_id')['amount'].agg([
('총구매액',np.sum),
('구매건수', np.size),
('평균구매액', lambda x: np.round(np.mean(x))),
('최대구매액', np.max),
]).reset_index()
f = tr.groupby('cust_id').agg({
'goods_id': [('구매상품종류1', lambda x: x.nunique())],
'gds_grp_nm': [('구매상품종류2', lambda x: x.nunique())],
'gds_grp_mclas_nm': [('구매상품종류3', lambda x: x.nunique())]
})
f.columns = f.columns.droplevel()
# groupy 상위n개만 추출
eda_sort_top2 =(
eda3.
sort_values(by="joined_date",ascending=False)
.groupby("op_id")
.head(2)
)stack
- 모든 열의 이름을 받아 수직으로 재구성
- stack하려면 set_index를 먼저 해줘야한다. 번호 인덱스이면 안됨
fruit=fruit.set_index('State')
fruit.stack()
fruit.stack().reset_index() #stack 후 리셋인덱스를 통해 멀티 인덱스를 풀어줌
fruit_tidy.columns=['state','fruit','weights'] #열이름 설정 
melt
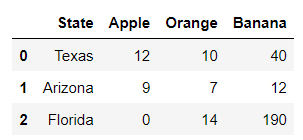
- id_vars: 수직으로 재구성 안하고 유지할 열 이름
- value_vars: 값으로 재구성할 열 이름
fruit.melt(id_vars=['State'], value_vars=['Apple','Orange','Banana'])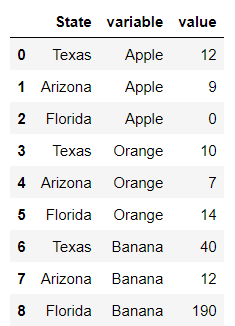
fruit.melt(id_vars=['State'], value_vars=['Apple','Orange','Banana'],
var_name='fruit', value_name='weight')unstack
fruit.stack().unstack()
#언스택하면 자동으로 멀티인덱스의 마지막 레벨의 값을 열로 가져옴
fruit.stack().unstack(0) #열이름으로 쓰고싶은걸 선택
f.columns = f.columns.droplevel()pivot
#tidy data에서
fruit_tidy2.pivot(index='State', column='fruit', value='weight')
#groupby와 유사
pd.pivot_table(flights, index='AIRLINE', columns='WEEKDAY', values='CANCELLED', aggfunc='mean', fill_value=0) concat
pd.concat([s2016,s2017])
pd.concat([s2016,s2017], keys=[2016,2017])join, merge
#join 결합기준: INDEX
s2016=s2016.set_index('Symbol')
s2017=s2017.set_index('Symbol')
s2016.join(s2017, lsuffix='_2016') #join은 열이름이 같으면 안됨
s2016.join(s2017, lsuffix='_2016', rsuffix='_2017', how='inner')
#merge 결합기준: 특정열, 기본: inner
s2016=s2016.reset_index()
s2017=s2017.reset_index()
s2016.merge(s2017, on='Symbol', how='right') #열이름이 같아도 자동구분
#merge 결합기준: 특정열
food_pr.query('Date==2017')
#or
cr=food_pr['Date']==2017
food_pr[cr]
food_tr.merge(food_pr, on=['item','store'], how='left')
기타 구조 정렬
- json
data = {'data': [{'id': 101,
'category': {'level_1': 'code design', 'level_2': 'method design'},
'priority': 9},
{'id': 102,
'category': {'level_1': 'error handling', 'level_2': 'exception logging'},
'priority': 8}]}
pd.DataFrame(data)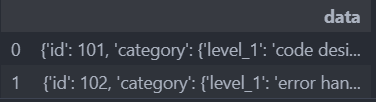
pd.json_normalize(data, "data")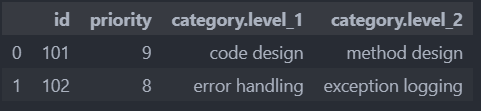
- explode function
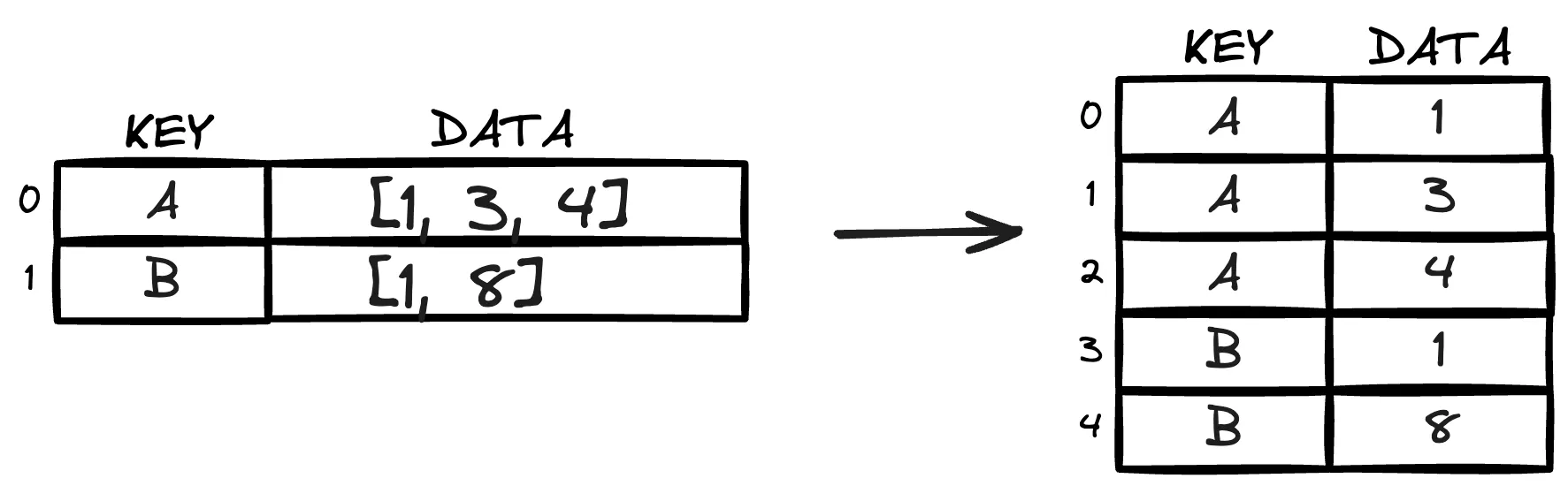
df_new = df.explode(column="data").reset_index(drop=True).jpg)
ML/DL swimmer