간단한 커뮤니티 서비스를 구현하기 위해 필요한 ERD 설계 중 고민이 몇가지 생겼다.
먼저 내가 짠 ERD는 아래와 같다.
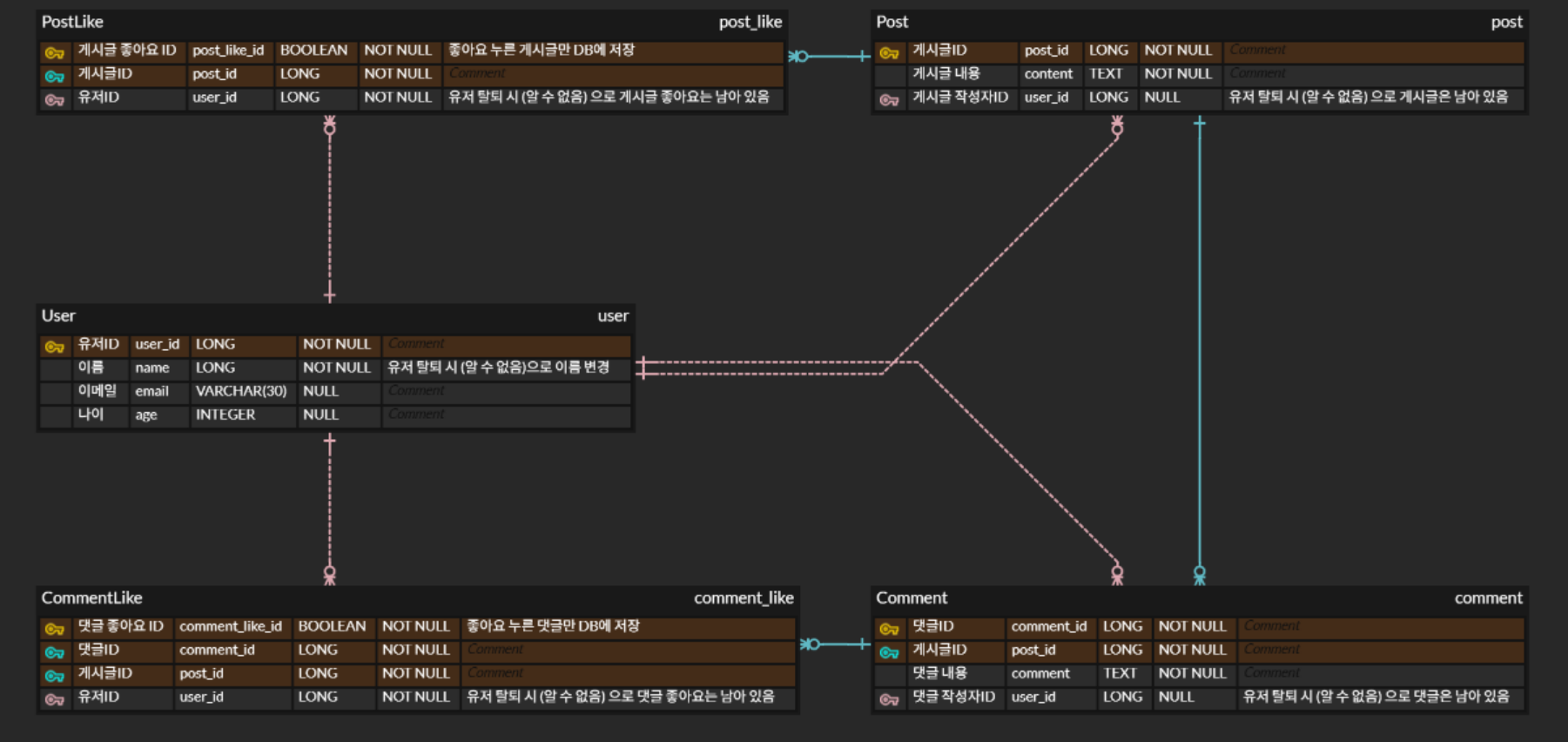
유저ID를 PostLike랑 CommentLike에 바로 외래키로 연결하는게 일반적인가?
ex. PostLike는 Post랑만, CommentLike는 Comment랑만 연결한 다음에 유저 정보 찾고 싶으면 PostLike랑 연결된 Post랑 연결된 User 테이블 이런 식으로 타고타고 조회하는 건지 아니면 지금 내가 짠 ERD처럼 PostLike, CommentLike 테이블에 UserID도 저장해두는게 맞는지
관계가 서로서로 다 연결이 되어있다.
이런 모양의 ERD를 보면서 무슨 생각을 했냐면
- 하나의 테이블 정보를 삭제했을 때 자식 테이블의 삭제도 하나하나 Cascade 옵션으로 설정해 줘야 할텐데 이게 과연 효율적일까?
- User 테이블에 너무 많은 관계가 부여되어 있는 것이 아닐까?
그래서 주변 서버 개발자들과도 대화해보고, 구글링해보고, 지피티한테 물어가며 내린 결론들을 적어보고자 한다.
✅ 관계의 관점에서 생각해봤을 때,
→ 어떤 게시글에 대한 '좋아요'나 '스크랩'은 게시글만이 가지고 있는 관계나 속성이 아닌 유저와 게시글간의 관계이기 때문에 현실을 그대로 반영한다는 관점에서 보면 User 테이블과 직접 연결하는 것이 맞다.
→ 좋아요는 "누가 무엇을 좋아했는가"라는 정보를 다루기 때문에, User와의 직접적인 관계는 본질적인 속성
✅ 성능의 관점에서 생각해봤을 때,
→ 성능 측면에서도 조인 depth를 줄이는 것이 유리하다.
PostLike → Post → User 식으로 타고 가는 것보다 PostLike → User 식으로 바로 조인하는 것이 효율적
→ 설계 상으로도 Like는 User의 행동이므로 User ID가 직접적으로 들어가 있어야 명확함.
✅ 확장성의 관점에서 생각해봤을 때,
→ 나중에 User별 좋아요 목록을 조회하는 기능이 추가되는 경우 유리함(성능 관점과 일맥상통함)
PostLike, CommentLike 테이블 같은 경우에는 각각 (게시글ID, 유저ID)와 (댓글ID, 유저ID)라는 unique한 key 쌍을 가질테니 굳이 게시글 좋아요ID와 댓글 좋아요ID 필드를 만들지 않아도 되지 않나? 보통 만드는지 아닌지?
테이블 자체 ID를 추가로 만들지 않아도, 게시글 ID와 유저 ID는 unique한 키 쌍으로 유일성과 최소성을 만족하는 키가 될 수 있다. (댓글 ID, 유저 ID)도 마찬가지.
그런데 레퍼런스를 찾아보면 주변 개발자들이 @Id @GeneratedValue를 활용해 기본적으로 Autoincremented 되는 id값을 테이블에 기본적으로 추가한다.
그게 왜일까?
그리고 복합키를 기본키로 잘 설정하지 않는다.
나는 (게시글ID, 유저ID)라는 2개의 외래키를 합쳐 기본키로 삼고자 했다.
그런데 복합키는 기본키로 잘 사용하지 않는다는 피드백을 얻었다. 관리가 복잡해진다는 이유다.
그렇다면
[복합키를 기본키로 함으로써 발생하는 관리의 불편함 <<<< 관리를 위해 (사실은 불필요한) 필드를 추가해 기본키로 관리하는 메모리 낭비] 인 것인가?
한 번 차근차근 톺아보자..
✅ 복합키를 기본키로 했을 때의 관리상 불편함
1. 복잡한 외래 키 구성
다른 테이블에서 FK로 참조할 때 두 개 이상의 컬럼을 함께 참조해야 한다.
ex. FOREIGN KEY (post_id, user_id) REFERENCES post_like(post_id, user_id)
쿼리와 JPA 등 ORM에서는 매핑이 복잡해짐.
JPA 기준으로는 복합키 매핑을 위해 @Embeddable, @EmbeddedId 또는 @IdClass를 사용해야 함
→ 관리 복잡도 증가
2. 인덱스 구성 및 유지 비용
PK는 자동으로 인덱스로 생성되므로 복합키일 경우 다중 컬럼 인덱스가 생성된다.
이 인덱스를 사용하는 쿼리는 인덱스 순서에 민감해서 쿼리 최적화에 신경 써야 한다.
특히 쿼리 조건에 일부 키만 들어가는 경우 효율이 떨어진다!
→ 이 부분에 대해서는 처음 알게 됐다. 다중 컬럼 인덱스의 경우 인덱스 성능을 비교하는 과정이 생략되고 스캔해야하는 데이터의 개수가 줄어든다고 한다. 이러한 이유 때문에 개별 인덱스보다 좀 더 나은 조회 성능을 제공할 수 있게 된다. 단, 올바른 순서대로 다중 컬럼 인덱스를 생성했을 때에만! 따라서 이 쿼리 최적화에 신경을 써야 해서 어렵다는 말이다.
3. JOIN 및 WHERE절 가독성 저하
단일 키는 post_like_id = 123처럼 간단하지만
복합키는 post_id = ? AND user_id = ? 식으로 작성해야 하고 이는 모든 쿼리에 반복
→ 쿼리문에 반복되는 부분이 많이 생김
✅ post_like_id 같은 단일 대체키 도입 시 메모리 낭비가 되는가?
- 단일 PK의 비용은 존재하지만 낭비라고 보기는 어렵다.
| 항목 | 복합키 (post_id + user_id) | 단일키 (post_like_id) |
|---|---|---|
| PK 크기 | 2개 컬럼 (8byte + 8byte) = 16byte | 1개 컬럼 (8byte) |
| 테이블 크기 | 같거나 조금 더 큼 (단일 PK + 추가 unique index 필요) | 같거나 더 작을 수 있음 |
| 인덱스 설계 | 복합 PK 인덱스만 있음 | PK 인덱스 + (post_id, user_id) unique index 필요 |
| 조인 가독성 | 불편 | 간결 |
→ 단일 PK로 할 경우에도 (post_id, user_id)에 유일 제약조건(Unique Index)을 따로 걸어야 함
→ 결국 비슷한 양의 인덱스를 가짐
따라서 "post_like_id 추가 = 메모리 낭비"라기보다는
유지보수 편의성을 위한 약간의 비용이다!
✅ 결론
post_like_id, comment_like_id를 추가해 기본키로 설정하고,
(post_id, user_id)와 (comment_id, user_id) 를 각각 unique 제약조건을 걸어준다.
현재의 ERD에 + JPA 구현 시 unique 제약 조건 거는 것 잊지 않기!
