1.Introduce
Alexnet은 2012년에 출시된 딥러닝 프레임워크이다. 당시의 기술적 한계때문에 dataset이 큰 경우 효율적인 학습을 기대하기 어려웠다.
논문에서는 GTX580 로 수일을 학습시간이 소요됐지만 현재는 GPU의 발달로 몇 시간 이내에 alexnet을 학습할 수 있다고한다
2.Dataset
데이테셋으로는 Imagenet을 사용하였다
ILSVRC에서 제공된 데이터를 활용하였다.
*ILSVRC = Imagenet Large Scale Visual Recognition Challenge3.The Architecture
- 3-1)ReLu Non-linearity
비포화비선형성(ReLu)를 활용하면 포화비선형성(tanh / sigmoid)함수의 saturating 문제를 해결할수있음
*saturationg 이란?
⇒활성화 함수로 특정비선형 함수를 적용한 신경망에서 반복해 학습시키다보면 가중치 업데이트가 안되는 지점
ReLU 의 함수식은 f(x) = max(0,x)이고, 학습속도 측면에서 ReLu가 Tanh보다 효율적인것을 확인할수 있었다.(비포화_비선형성>>포화_비선형성)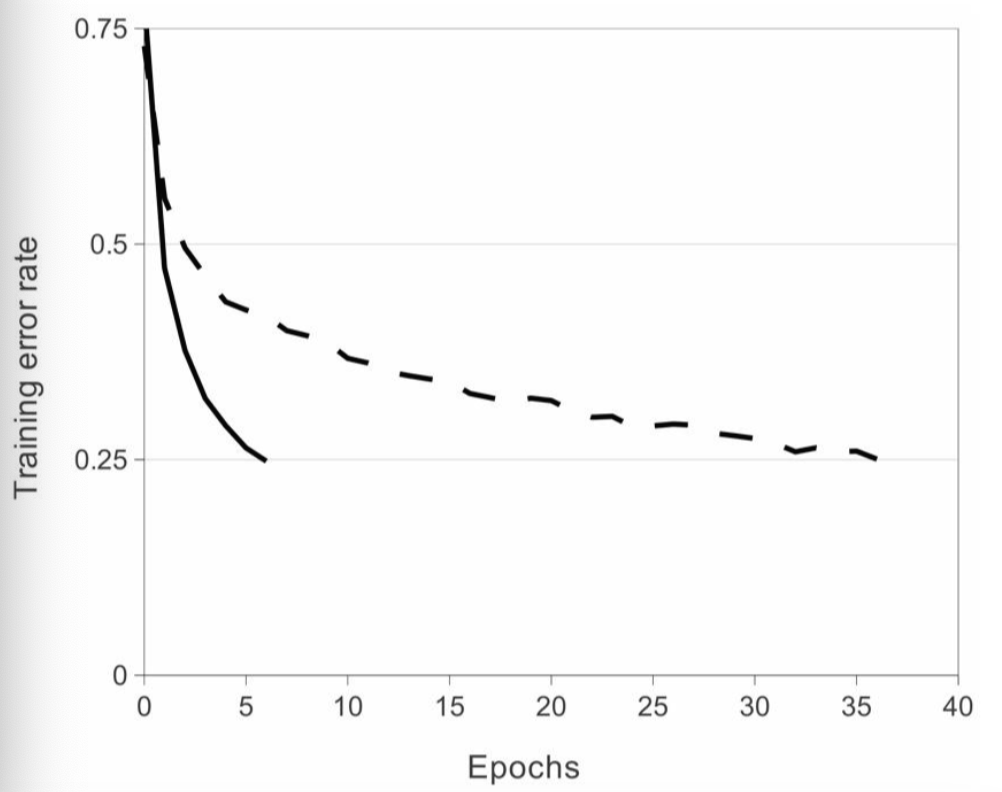
- 3-2)Training on Multiple GPUs
논문에서는 두개의 GPU를 사용하였는데 각 GPU가 하는 일이 달랐다
끝에 있는 두개의 FC층에서만 소통을 하고, 그 외의 층에서는 각자의 연산을 진행했다.
그 결과 각 컨볼루션 계층의 커널이 더 많은 Multi GPU상황에서 오차율을 1.7%~1.2%까지 줄어드는걸 확인할수있었다.- 3-3)Local Response Normalization
ReLu의 값이 양수일때에는 그 값이 그대로 출력되었다. 하지만 양수값이 너무 클 때에는 주변값에 영향을 미쳐서
그 값들 또한 커질수있기때문에 LRN(Local Response Normalization)을 적용하였다. 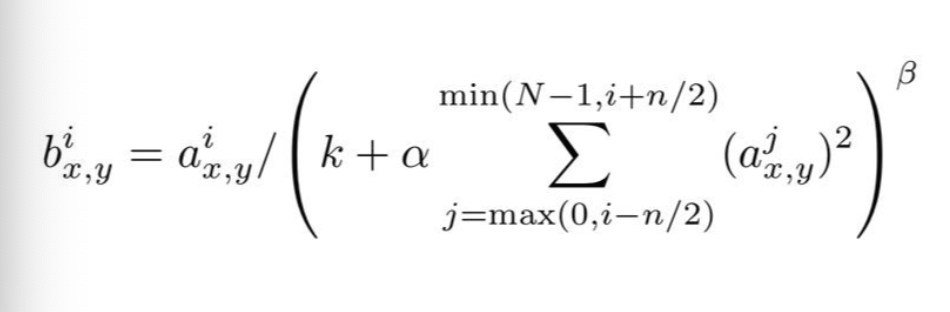
LRN의 식이며 k, n α, β는 hyperparameter이다.
Alexnet 이후 현대의 CNN에는 batch normalization을 사용함- 3-4)Overlapping pooling
과적합을 방지하기 위해 Overlapping pooling을 적용하였다.
쉽게 말해 pooling에 중복을 허용하여 0.3~0.4%의 오차율을 감소시킬수있었다고 한다- 3-5)Overall Architecture
.jpg)
모델의 전반적인 구조는 [Input layer - Conv1 - Maxpooling1 - Normalization - Conv2 - Maxpool2 - Normalization2 - Conv3 - Conv4 - Conv5 - Maxpool 3 - FC1 - FC2 - Output layer]
pooling이 일어나는 곳에서 LRN도 진행되고 2개의 GPU로 작동하면서 두 번쨰 층에서 depth가 48, 48로 나누어진다4.Reducing Overfitting
- 4-1)Data Argumentation image translation & horizontal reflection을 적용하여 데이터를 증강시켜 줌. 학습데이터의 RGB에 PCA를 진행시켜 이미지의 밝기나 특정 색의 강도의 영향을 제거함
- 4-2)Drop out 특정 뉴런을 비활성화시켜 다른 뉴런에 의존하여 결과값을 출력하는 것을 방지하는 방버을 사용하였고 FC layer 중 처음 두개의 layer에서만 사용되었다
5.Details of learning
- Details
- Stochastic Gradient Descent 활용
- Batch Size - 128
- Momentum - 0.9
- Weight Decay - 0.005
- Weight Initialization - zero mean Gaussian distribution 활용, 표준편차 0.01
- Bias Initialization - Layer에 따라 1 또는 0으로 설정, 1로 설정한 이유는 ReLU값에 양수를 부여하면서 학습을 촉진시키는 역할을 하기 때문이다.
- Learning Rate - 0.01로 진행하면서 training시 조정. 조정 방법은 0.01을 10씩 나누면서 진행되었음.
6.Results(개인의견 포함)
- Alexnet은 거리가 짧을 수록 유사한 사물로 인지하였다는 점을 앞세워 2012년 ILSVRC에서 우승하는 성과를 이루었다.당시 기술적인 한계때문에 긴 학습시간이라는 비용이 든건 사실이지만 2개의 GPU가 다른방식으로 학습을 진행하여 당시 효율적으로 학습을 진행했다는 점이 흥미로웠다
