
통계의 두 가지 종류: 기술 통계와 추론 통계 (Types of Statistics)
(1) 기술 통계 (Descriptive Statistics)
정의: 측정이나 실험에서 수집한 자료를 정리, 요약, 해석하여 자료의 특성을 파악하는 학문
가장 중요한 목적은 데이터를 요약하는 것
목적: 방대한 로우 데이터(원시 데이터)를 의미 있는 형태로 정리하고, 보기 좋게 요약하여 빠르게 이해하고 의사결정하며 인사이트를 얻는 데 있음
how(어떻게???) 요약의 방법: 숫자로 요약(평균, 중앙값, 최빈값 등)하거나, 차트나 그래프로 시각화하여 요약할 수 있음
'내 영화 TMI' 적용: 내 영화의 평점, 상영시간 같은 수치 데이터나 장르별 영화 수 등을 차트나 시각화를 통해 요약하면, 단순히 숫자로만 보이지 않던 특성, 패턴, 정보를 한눈에 파악할 수 있습니다.
(2) 추론 통계 (Inferential Statistics)
정의: 표본에서 얻은 데이터를 이용하여 전체 모집단의 미지의 양상을 추정(추측, 예측, 예상)하는 과정입니다. 100%의 확신이 아닌, 확률적으로 높은 가능성을 파악하는 학문.
• 필요성: 전수 조사(모든 대상을 조사)는 시간, 비용, 실시간 반영의 어려움 등으로 사실상 불가능하기 때문에, 일부(표본)를 통해 전체를 추정하는 방식이 필요
'내 영화 TMI' 적용 및 핵심 개념:
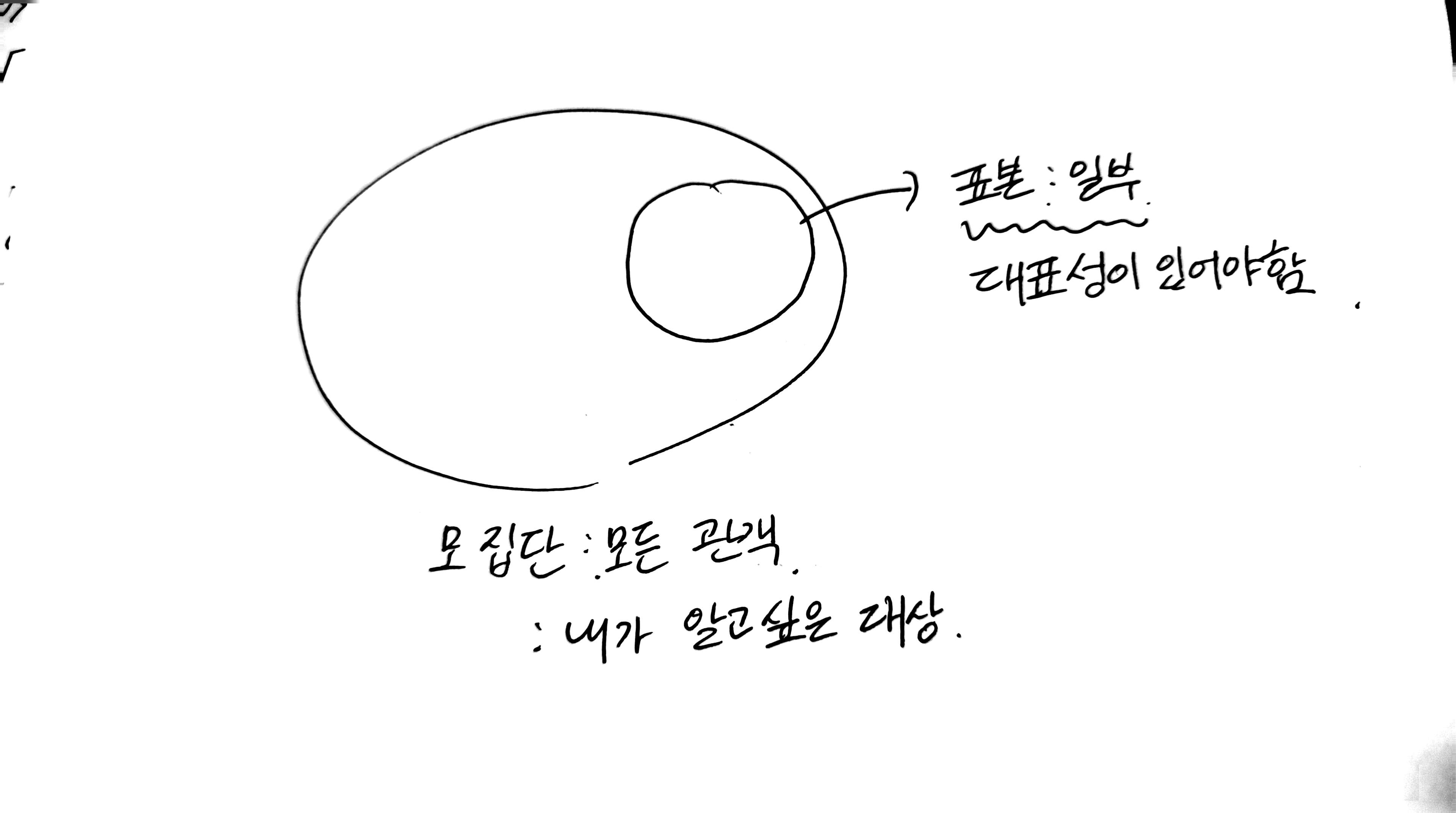
◦ 모집단: 내가 알고 싶은 전체 대상 (예: "모든 관객")
◦ 표본: 모집단 중에서 일부를 추출한 것으로, "일부" 또는 "샘플"과 같은 의미로 사용될 수 있음.
◦ 표본추출의 편향 (Sampling Bias): 특정 장르를 좋아하는 사람들만 표본으로 뽑는 것처럼, 편향된 표본을 사용하면 "모든 관객"이라는 모집단의 대표성을 잃게 되어 결과를 전체에 일반화할 수 없음.
<그림>
표본 오류의 가능성
전체를 모두 조사하지 않고 일부만 조사해도 전체를 어느 정도 추정할 수 있지만, 그 결과에는 항상 불확실성이 따른다.
대표성(Representativeness) vs. 타겟팅(Targeting):
▪ 대표성이 필요한 경우: "모든 관객"이 영화를 어떻게 평가할지 알고 싶을 때, 모집단 전체를 반영하는 표본이 필요
▪ 타겟팅이 가능한 경우:
애초에 특정 집단을 모집단으로 정의한다면 오히려 유용한 분석이 될 수 있다??
->"액션 영화 팬들이 이 영화를 어떻게 느낄까?"와 같이 특정 집단의 반응을 알고 싶을 때는 그 집단만 표본으로 뽑아도 문제가 없음.
이 경우 모집단이 "모든 관객"이 아니라 "액션 팬 집단"으로 재정의된 것으로 볼 수 있다.
이러한 접근 방식은 영화관 마케팅이나 OTT 서비스의 세분화 마케팅(추천 알고리즘)에서 유용하게 활용됨.
◦ 좋은 표본 추출의 중요성:
표본이 모집단을 대표성 있게 뽑혀야 오류를 줄일 수 있습니다. 예를 들어, 강남구 거주자만 표본으로 뽑아 대한민국 20대 남성의 평균 수익을 조사하면 실제보다 높은 수익으로 편향될 수 있음.
영화 집단의 평점을 매기기전에 특정 장르를 좋아하는 사람들을 표본으로 뽑으면 모집단의 대표성을 잃게 된다.
“특정 장르를 좋아하는 사람들만 표본으로 뽑는 것 = 표본추출의 편향(sampling bias)”
→ 그래서 모집단의 특성을 제대로 반영하지 못하고, 결과를 일반화할 수 없음.
데이터 분석의 세 가지 목적 (Three Purposes of Data Analysis)
요약 (Summary):
데이터를 보기 좋게 정리하고, 특성과 패턴을 파악하는 것
(사람의 뇌가 한 번에 많은 데이터를 파악하기 어렵기 때문에 필수적)
▶️ 🎬(예시)'내가 본 영화들에서 평점, 장르별 영화 수 등을 그래프로 요약하여 사용자의 취향 패턴 등을 파악하는 것이 이에 해당
설명 (Explanation):
데이터에서 어떤 현상이 나타났을 때, "왜" 그런 일이 일어났는지 그 원인을 찾는 과정
내부 요인과 외부 요인을 함께 분석합니다.
▶️ 🎬 (예시)'내가 본 영화들'에서 "사용자가 드라마 선호도가 압도적으로 높다"는 사실에서 나아가, "사용자가 이야기/감정 서사 중심 영화를 선호하는 성향"이라는 인사이트를 도출하는 것은 이러한 현상에 대한 설명의 과정으로 볼 수 있음
예측 (Prediction):
기존 데이터를 학습하고 패턴을 분석하여 앞으로 일어날 일을 추정하는 것입니다. 추론 통계의 영역에 해당하며, 확률적 지식이 중요합니다.
▶️ 🎬 (예시) '내가 본 영화들'에 직접적인 예측 사례는 없지만, 넷플릭스, 왓챠 같은 OTT 서비스의 추천 알고리즘이 과거 시청 데이터를 기반으로 사용자가 좋아할 만한 영화를 예측하여 추천하는 것이 대표적인 예시
📌 변수(Variable)와 속성(Attribute) 정리
변수란?
알고 싶은 대상의 특징을 나타내는 값
데이터프레임에서는 보통 컬럼(column) 으로 표현됨
(=컬럼보고 설정,feature(변수):머신러닝에서 많이쓰임)
예시:
키, 몸무게, 시험 점수
_속성이란?__
변수에 담겨 있는 정보의 구체적인 값(특징)
즉, 변수의 속성(attribute)은 변수에 따라 여러 가지가 될 수 있음
변수의 종류와 예시
_범주형 변수 _(Categorical Variable)
성별 → 속성: 남, 여
장르 → 속성: 드라마, 액션, 코미디, …
연속형/수치형 변수 (Continuous / Numerical Variable)
키, 몸무게, 시험 점수 등 → 속성: 숫자 값 (예: 170cm, 65kg, 90점)
👉 정리하면,
변수(컬럼) = "무엇을 알고 싶은가?"
속성(값) = "그 변수에 담긴 구체적 정보"
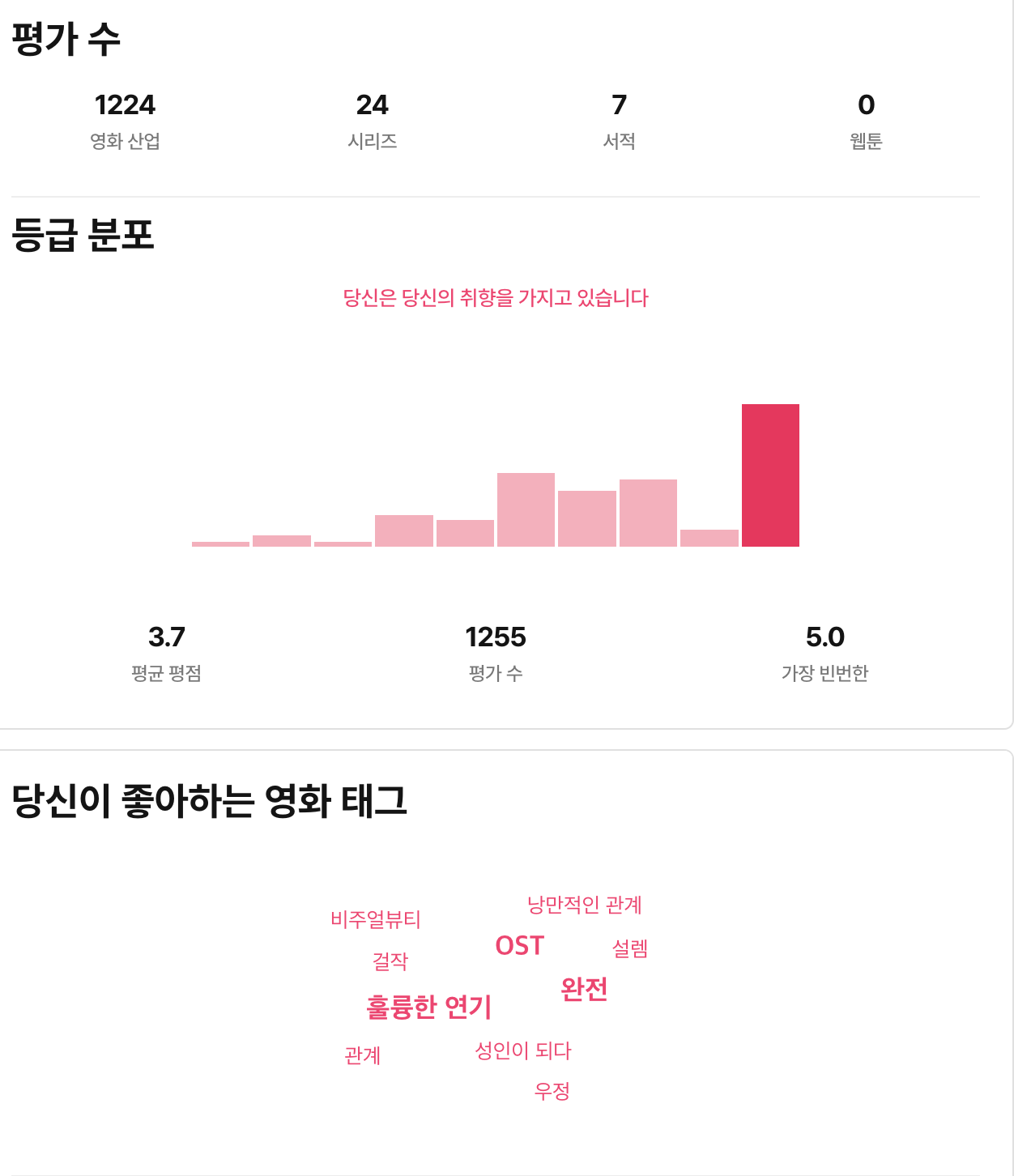
👉 차트나 시각화를 통해 수치를 요약하면, 단순히 숫자로는 잘 보이지 않던 특성·패턴·정보를 한눈에 파악할 수 있다.
데이터 유형(Data Type) 을 아는 게 곧 그래프 선택의 기준
1. 데이터 유형별 분포
(1) 범주형 분포 (Categorical):문자로 쓰여진 거라 생각해도 됨
예: 장르별 영화 수, 국가별 영화 수, 좋아하는 배우/감독 목록
→ 막대그래프(bar chart) 를 쓰는 이유: 범주끼리 비교(많고 적음)
여기서 보이는 수치: “Drama 713편, Action 301편, Comedy 359편 …”
숨겨진 특징: 사용자가 드라마 선호도가 압도적으로 높다는 걸 알 수 있음 → 장르별 취향 패턴

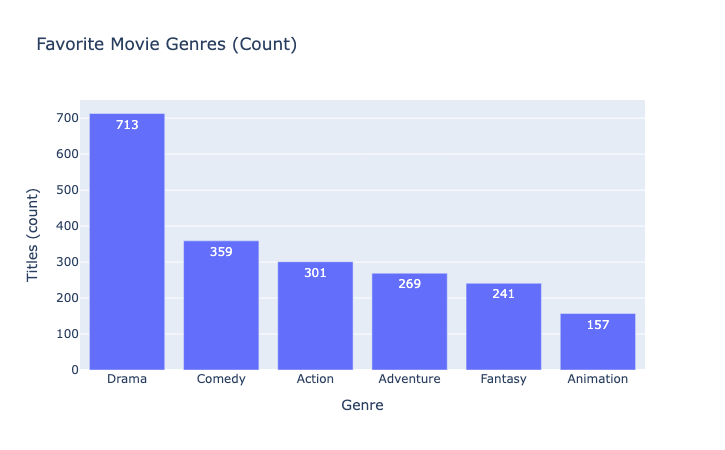
- 범주형(=글자) 그래프 카테고리 별 차이를 한 눈에 확인 가능 막대와 막대 끼리는 공백이 있어야한다.
여기서 Genre = 변수
Drama, Action, Comedy = 변수의 속성 값(정보의 속성)(범주)
(2) 이산형 분포 (Discrete)
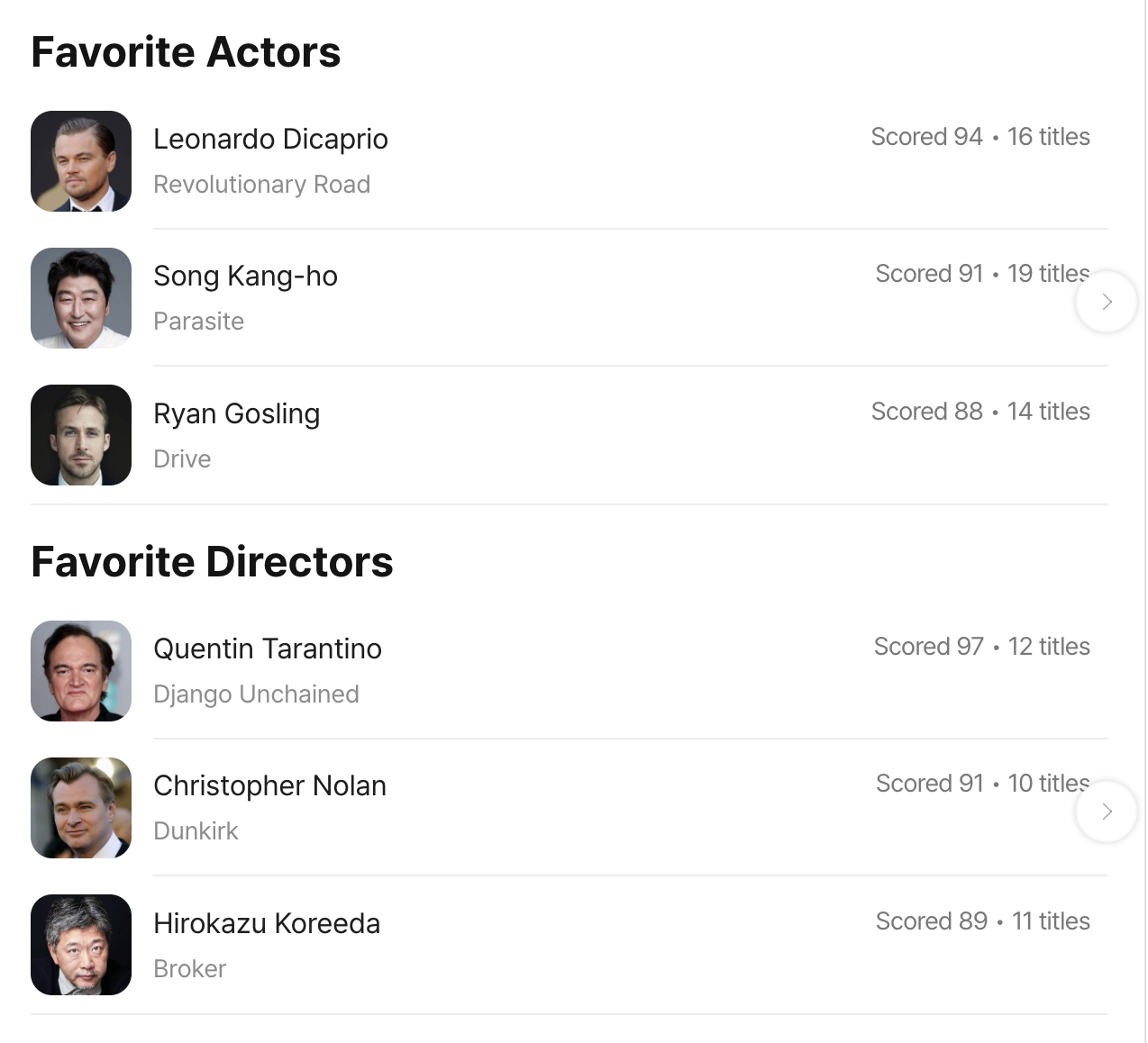
예: “본 영화 수(title count)”, “배우별 영화 출연 수(16편, 19편 …)”
→ 막대그래프 사용: 값이 정수 단위(영화 개수)라서 이산적임
숨겨진 특징: 특정 배우/감독에 대한 몰입도 파악 가능 (레오나르도 디카프리오 16편 등)
(3) 연속형 분포 (Continuous)
예: 평점(score 74, 85, 97 …), 시청 시간(2372시간)
→ 이런 값은 사실 히스토그램이나 분포곡선으로도 표현 가능
숨겨진 특징: 평점이 전반적으로 높은 편 → 평가할 때 관대한 성향 or 본 영화 선택이 취향에 맞았다는 의미
- 그래프 선택 이유
막대그래프: 범주(장르, 국가, 배우, 감독) 간 비교 → 어느 쪽을 더 선호하는지 한눈에 보기 쉬움
히스토그램(가능한 경우): 평점 분포(1~100점, 1~5점 등)를 본다면 → 관람자가 평점을 얼마나 균형있게 주는지, 혹은 편향적으로 주는지 알 수 있음
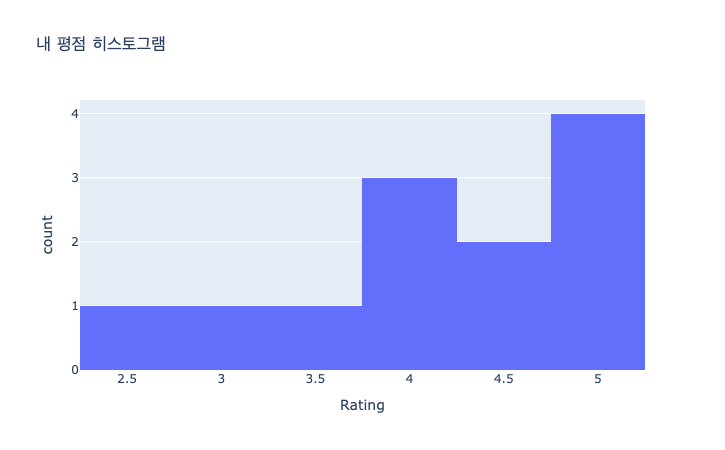
- 숨겨진 정보 & 인사이트
장르: Drama가 압도적 (713편) → 사용자가 “이야기/감정 서사” 중심 영화를 선호하는 성향
국가: 미국(751편) + 한국(213편)이 대부분 → 헐리우드+한국영화 취향 뚜렷
배우/감독: 디카프리오, 송강호, 타란티노, 놀란 등 → 주류 & 영향력 있는 배우/감독 중심으로 소비 → “시네필 성향”
평점: 85~97점대 다수 → 영화 선택 시 취향 필터가 강해서 낮은 점수 영화는 애초에 많이 보지 않았을 가능성
주요 시각화 도구: 히스토그램 (Histogram) 상세
• 도수 분포표와의 관계:
히스토그램은 도수 분포표의 시각화 버전으로, 숫자의 분포 패턴과 모양을 한눈에 보여줌. 도수 분포표는 식재료를 손질하는 과정에, 히스토그램은 그 재료로 요리를 완성하여 손님에게 제공하는 것에 비유할 수 있음.
• 히스토그램으로 알 수 있는 것:
◦ 값들이 어디에 몰려 있는지 (중심): 평균, 중앙값 등으로 파악할 수 있음.
◦ 얼마만큼 흩어져 있는지 (퍼짐): 분산, 표준편차, 사분위범위 등으로 파악할 수 있음.
◦ 분포의 모양:
▪ 대칭형/비대칭형: 데이터가 어느 쪽에 쏠려 있는지 (왜도) 파악.
▪ 봉우리의 개수: 분포에 봉우리가 두 개라면, 데이터셋 내에 여러 집단(예: 남성 키와 여성 키 분포)이 존재한다고 추측할 수 있음..
▪ 특이값/이상치 (Outliers): 평균을 왜곡할 수 있는 특이한 값들의 존재 여부를 시각적으로 확인할 수 있습니다.
'내 영화 TMI' 적용:

▪ 평점 분포:
"85~97점대 다수"는 평점이 높은 구간에 몰려있음을 보여주며, "영화 선택 시 취향 필터가 강해서 낮은 점수 영화는 애초에 많이 보지 않았을 가능성"이라는 인사이트를 얻을 수 있음
▪ 숨겨진 특징 파악:
평점의 전반적인 경향을 파악하여 관객의 성향(관대한지, 취향에 맞는 영화를 잘 고르는지) 등을 이해할 수 있음
• 히스토그램 사용 시 주의사항:
구간(계급, Bin) 크기 설정: 적절한 구간 크기를 정하는 것이 매우 중요
▪ 너무 크면 데이터의 디테일이 손실되어 분포의 특징을 파악하기 어려움.
▪ 너무 작으면 노이즈가 많아져 오히려 패턴을 파악하기 어려움.
Q. 구간의 간격을 어떻게 정하냐?
▪ (참고: 구간 개수를 대략적으로 정하는 스터지스 공식 K = 1 + 3.322 * log10(N)이 있음. 여기서 N은 데이터 개수)
데이터 유형 제한: 히스토그램은 연속형 데이터에만 사용해야 하며, 범주형 데이터에는 막대그래프를 사용해야 합니다.
• 원 그래프 (Pie Chart): 범주형 데이터의 전체 대비 비율을 시각화하는 데 사용됩니다 (예: 혈액형 비율).
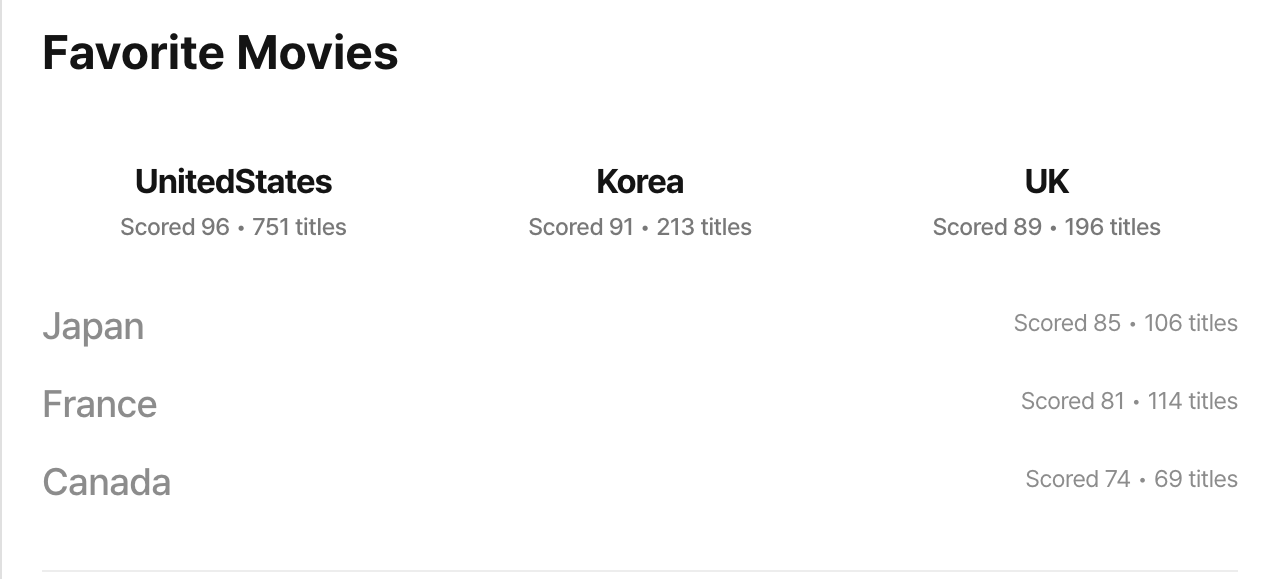
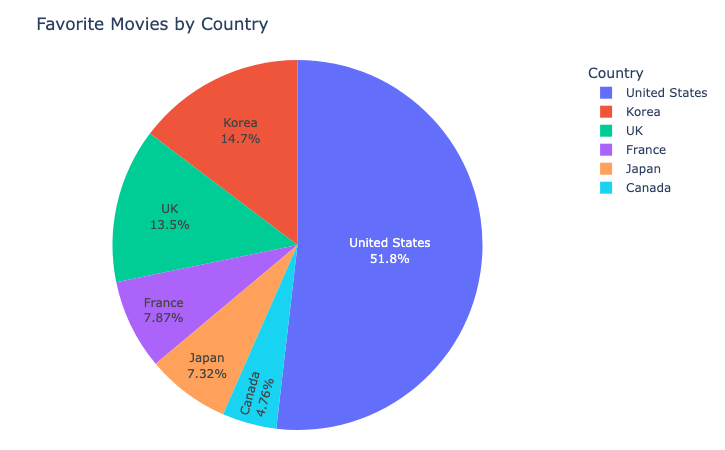
<코드>
🎯 종합 해석
헐리우드(미국 영화)가 절대적 중심 — 취향의 절반 이상을 차지.
->전 세계적으로도 콘텐츠 접근성이 가장 쉽고, 상업 영화 시장이 크기 때문에 자연스러운 결과(그런거임 ㅎㅎ)
한국과 영국 영화가 2, 3위를 차지 — “자국 콘텐츠”와 “영미권 콘텐츠”에 고른 관심.
예술/애니메이션 강국(프랑스·일본) 영화도 꾸준히 소비 — 대중영화 외에도 다양성을 추구하는 경향.
• 변수의 개수에 따른 그래프 선정
◦ 변수 1개: 데이터의 분포 및 비율 파악에 사용합니다 (예: 혈액형 - 원 그래프)
◦ 변수 2개: 변수 간의 관계 파악에 사용합니다 (예: 성별과 시험 점수 - 박스플롯, 상관관계 분석)
◦ 변수 3개 이상: 버블 차트, 히트맵 등 다양한 고급 시각화 도구를 활용할 수 있음.


좋아하는 영화 장르에 어떻게 공포가 없어.. 이런 영알못