Hadoop Ecosystem
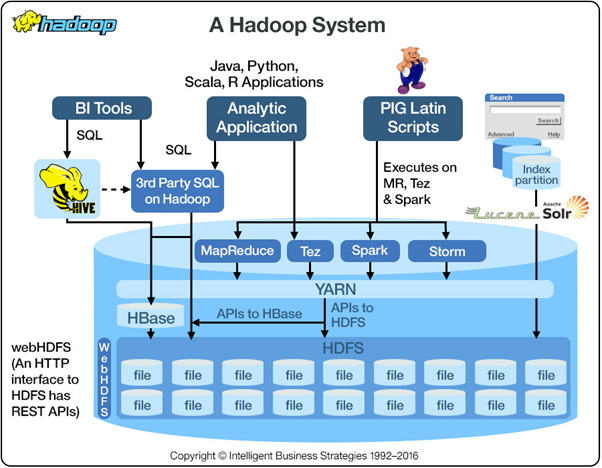
공부를 해보면서 Hadoop이라는 단어를 쓸 때 어떤 것을 지칭하는 지 확실히 해야 한다는 것을 느꼈음. 여러 문서를 읽어본 결과, 각각 문서에서 Hadoop이란 단어의 정확한 의미가 각자 다름.
예를들면..
Hadoop이란 단어를
- Hadoop Ecosystem 전체를 지칭하는 경우
- HDFS만을 지칭하는 경우
- HDFS와 MapReduce 같은 분산처리 Framework만 포함하는 경우
- 그 외
아무튼 Hadoop이란 용어를 쓸 때 헷갈리지 않게 하는 것이 좋을 것으로 보임. 아직 정리가 많이 되지 않아 많은 현재는 많은 내용을 올리지 않았지만 앞으로 Hadoop과 관련된 내용을 올릴 때는 헷갈리지 않게 Hadoop이라고 하면 1번의 의미로 사용하고 Hadoop Component를 지칭할 땐 그냥 그 Component의 이름을 사용할 것임. 예를 들면 HDFS을 지칭할 땐 그냥 HDFS라고 할 예정임.
Map/Reduce
위의 그림에서도 확인했겠지만 Map/Reduce는 Hadoop Ecosystem의 하나의 요소일 뿐 HDFS에 적용되어 있는 기술이 아님.
HDFS에 데이터가 어떻게 저장되는지 정확히 밝혀내지 못해 Map/Reduce가 어디서 사용되는지 헷갈렸는데, 지금까지 여러 문서를 본 결과를 적어보자면
HDFS은 말 그대로 Data를 저장하는 Distributed File System이며, Map/Reduce는 이러한 분산 환경에서의 처리를 수행하는 Framework 혹은 Programming Paradigm라고 할 수 있음.
그래서 잘보니까 ElasticSearch와 Hadoop의 연동을 돕는 ES-for-Hadoop이라는 Library도 ElasticSearch와 HDFS을 직접 연결하는 것이 아니라 HDFS 위에 있는 분산처리 Framework와 연동을 하는 것이었음.
ES-for-Hadoop Library는 Map/Reduce, Apache Spark, Pig, Hive, Storm과 같은 분산처리 Framework와의 연동을 지원함.
사실 이중에서 Map/Reduce는 실시간 데이터 분석 플랫폼을 만드는데는 적합하지 않다고 하는데, 이유는 일단 Map/Reduce를 코드로 구현하여 사용하는 것이 까다롭다고 함. 게다가 Map/Reduce는 Disk I/O 기반이라 느릴 수 밖에 없음.
그리고 ES-For-Hadoop의 사용사례를 검색해봐도 Map/Reduce를 사용한 사례는 거의 보지 못했고 Apache Spark가 가장 많이 보였음.
