File Format 요약 다이어그램
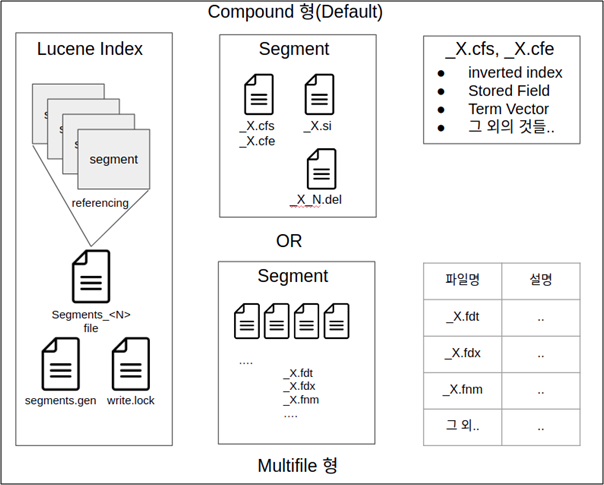
Lucene index는 여러개의 Segment로 이루어져있다고 하는데 실제로 File을 들여다보면 위와 같이 정리할 수 있음. (_X.에서 X는 Segment의 이름이다.)
왼쪽부터 시작하면 Lucene index는 실제로 여러 개의 Segment를 가질 수 있음. 그리고 Segment 외에도 존재하는 Segment들을 Referencing하기 위한 Segments_ file, Segments.gen file 그리고 여러개의 IndexWriter(Lucene 내에서 Index를 생성해주는 Class)가 Segment를 쓰는 것을 방지하기 위한 write.lock file이 있음.
Segment로 넘어가면, Segment는 실제로 하나의 file이 아니고 여러 개의 file로 이루어져있음. 그런데 Lucene에서는 Segment를 이루는 file들을 저장할 때 2가지 옵션을 제공하는데 하나는 Multifile 방식, 다른 하나는 Compound 방식임.
참고로 두가지 방식 모두가 갖는 File들도 존재함
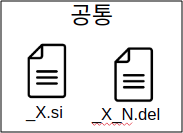
_X.si file의 확장자 si는 Segment information을 나타내며, Segment의 Metadata()를 저장하고 있음. _X_D.del file은 Segment에서 삭제된 Document들에 대한 정보를 저장함.
Multifile 방식
다시 넘어가면, Multifile 방식은 이름 그대로 Segment를 저장할 때 여러개의 file을 쓰는 방식임. Index에는 Term vector, inverted index, stored field 등에 대한 정보가 들어가야 하는데, 이를 각 항목별로 file을 만들어 Segment를 저장하는 것임.
아래는 Multifile 방식을 사용할 때, 생성되는 File들의 목록임. 원리를 참고한 책은 Lucene 3.x 버전인데 2021년 최신 버전은 8.x 버전이라서 기본적인 원리는 책을 참고했고 Release note를 확인해서 바뀐 것이나 추가된 것도 명시하였음.
| 파일명 | 설명 | 관련항목 |
|---|---|---|
| _X.fdt | Stored Field 의 값들을 저장 | Stored Fields |
| _X.fdx | fdt에 있는 Stored Field를 가리키는 Pointer를 저장(Document Number를 통해 fdt 내의 정확한 위치를 알아낼 수 있음) | Stored Fields |
| _X.fnm | Segment 내의 모든 Document에서 사용되는 모든 Field에 대한 정보를 가짐. Field Name뿐 아니라 Field Option(ex. term vector 사용여부)에 대한 정보도 포함. | inverted index |
| _X.frq -> _X.doc | Segment의 각 Term과 그것의 Frequency를 포함하고 있는 Document의 List 정보를 저장 | inverted index |
| _X.nrm -> _X.nvd, _X.nvm | Normalization factor 정보 저장 | Norms |
| _X.prx -> _X.pos | Term의 Index 내에서의 위치정보를 저장 | inverted index |
| _X.tii -> _X.tip | Term Dictionary의 Index, 메모리(heap)에 저장되기 때문에 Segment가 File 형태로 Disk에 저장되어도 Memory 소비가 있는 이유 중 하나임 → 최신 버전은 Memory에 저장하는 대신 Disk와 File System Cache를 사용하여 Memory 사용량을 줄였음. | Term Dictionary |
| _X.tis -> _X.tim | Segment 내의 모든 Term(field name과 그 값 형을 포함한 하나의 행 형태로 나타냄)이 저장됨. 게다가 각 Term 마다 그 Term이 등장하는 Document의 개수도 저장함. | Term Dictionary |
| _X.tvd | Term Vector Data 저장 | Term Vector |
참고
Stored field는 Document를 indexing할 때 segment내에 저장된 field와 그에 따른 value. ES나 Solr 모두 Lucene을 사용하기 때문에 ES나 Solr을 이용해서 Indexing하고 Indexing된 Document를 다시 받아올 때 원본 Document를 받아오는 것이 아니라 Segment 내의 Stored field를 받아오는 것임. 물론 url 정보를 stored field로 하여 url을 받아온 뒤에 원본에 접근할 수도 있음.
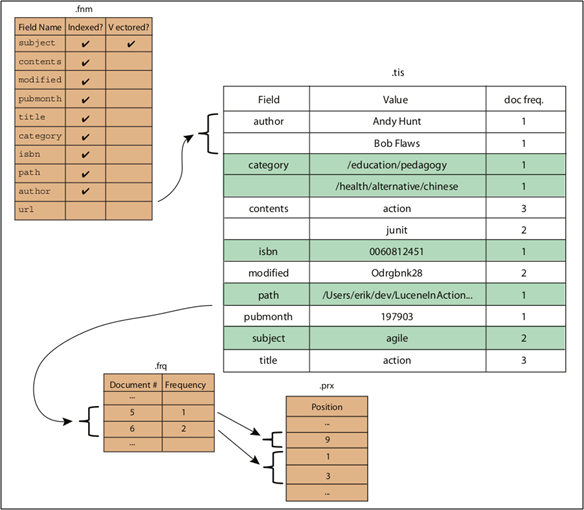
위의 그림은 Lucene in action이라는 책에서 가져온 이미지, .frq, .prx file은 현재 버전에서는 각각 .doc, .pos file로 변경되었음.
Compound 방식
Multifile 방식은 Segment를 생성할 때, File을 너무 많이 생성한다는 단점이 있음. File의 수가 많아지면 그만큼 더 많은 Open File을 관리해야하는데 현대 OS에서는 Open File의 개수가 제한되어 있음. 그렇기 때문에 Multifile 방식을 계속 사용하다보면 갑자기 “Too many open files” IOException이 뜰 수가 있음. (특히 Segment Merging시에 하나의 Segment만 쓰는 것이 아니라 여러 개의 Segment를 사용하여 File Descriptor를 더 많이 소비함)
그래서 Multifile 방식은 잘쓰지 않고 Default로 설정된 방식 역시 Compound 방식임. Compound 방식은 위의 표에서 나타나 있는 _X.fnm, _X.fdx.. 등등의 파일을 모두 _X.cfs, _X.cfe 파일에 저장함.


공부하면서 메모한 것인데 잘못 알고 있는게 보이시면 지적부탁드립니다.