[정적 크롤링] 파이썬으로 나라장터 입찰정보 데이터 수집하기
다음 url에서 공고일은 1월 1일, 공고 마감일은 1월 15일로 설정한 후 우측 하단의 검색건수 표시에 체크를 한 후 데이터를 수집하였습니다.
수집할 데이터 목록은 다음과 같고, 각 목록의 상세 페이지에 들어가 재입찰 여부와 추정가격도 수집해 보았습니다.
1. 라이브러리 로드
앞으로 사용할 라이브러리를 로드해줍니다.
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup2. 한 페이지의 테이블 및 내용 링크를 가져오는 함수 만들기
하나의 페이지의 테이블 및 내용링크를 가져오는 page_scrapping 함수를 작성하였습니다.
이후 반복문을 사용하여 전체 페이지에 적용할 것입니다.
def page_scrapping(page_no):
url = f'https://www.g2b.go.kr:8101/ep/tbid/tbidList.do?area=&areaNm=&bidNm=&bidSearchType=1&budgetCompare=&detailPrdnm=&detailPrdnmNo=&downBudget=&fromBidDt=2023%2F01%2F01&fromOpenBidDt=&industry=&industryCd=&instNm=&instSearchRangeType=&intbidYn=&orgArea=&procmntReqNo=&radOrgan=1&recordCountPerPage=30&refNo=®Yn=Y&searchDtType=1&searchType=1&strArea=&taskClCds=&toBidDt=2023%2F01%2F15&toOpenBidDt=&upBudget=&useTotalCount=Y¤tPageNo={page_no}'
response = requests.get(url)
html = BeautifulSoup(response.text, 'html.parser')
content_link = []
for i in html.select('td.tl > div > a'):
content_link.append(i['href'])
df = pd.read_html(url)[0]
df = df[df['업무'].notnull()]
df["내용링크"] = content_link
return df3. 마지막 페이지 번호 찾기
마지막 페이지를 나타내는 html 태그를 찾아 마지막 페이지 번호를 찾습니다.
url = f'https://www.g2b.go.kr:8101/ep/tbid/tbidList.do?area=&areaNm=&bidNm=&bidSearchType=1&budgetCompare=&detailPrdnm=&detailPrdnmNo=&downBudget=&fromBidDt=2023%2F01%2F01&fromOpenBidDt=&industry=&industryCd=&instNm=&instSearchRangeType=&intbidYn=&orgArea=&procmntReqNo=&radOrgan=1&recordCountPerPage=30&refNo=®Yn=Y&searchDtType=1&searchType=1&strArea=&taskClCds=&toBidDt=2023%2F01%2F15&toOpenBidDt=&upBudget=&useTotalCount=Y¤tPageNo=1'
response = requests.get(url)
html = BeautifulSoup(response.text, 'html.parser')
last_page = html.select('#pagination > a.next_end')[0]['href'].split('=')[-1]
last_page제가 코드를 실행했을 당시 마지막 페이지 번호는 488번이었습니다.
4. 전체 페이지 내용링크 찾기
2번의 함수와 3번의 last_page 변수를 활용하여 전체 페이지의 내용링크를 찾습니다.
from tqdm import trange
import time
page_list = []
for i in trange(1, int(last_page)+1):
result = page_scrapping(page_no=i)
page_list.append(result)
time.sleep(0.01)5. 수집한 내용링크 하나로 붙이기
concat을 사용하여 page_list의 모든 내용을 하나로 이어 붙입니다.
df = pd.concat(page_list, ignore_index=True)
df.shape6. 재입찰 데이터 가져오기
def get_desc(df_link):
try:
y = x = 0
response = requests.get(df_link)
content_html = BeautifulSoup(response.text)
content = pd.read_html(response.text)
content_list = []
[content_list.append(i) for i in content]
total = pd.concat(content_list, axis = 1, ignore_index = True)
# 재입찰
for i in total.columns:
if total[i].isin(['재입찰']).any():
y = i
break
elif total[i].isin(['재입찰여부']).any():
y = i
break
else:
y = None
if y == None:
rebid = '재입찰 관련 내용이 없습니다.' # 테이블에 재입찰 탭이 아예 존재하지 않음
else:
x = 0
for j in total.iloc[:,y]:
if j == '재입찰':
break
elif j == '재입찰여부':
break
elif j == '재입찰허용여부':
break
x += 1
rebid = total.iloc[x, y+1]
time.sleep(0.01)
except:
rebid = '내용없음'
return rebid함수 실행
from tqdm.notebook import tqdm
tqdm.pandas()
df['재입찰'] = df['내용링크'].progress_map(get_desc)- 재입찰 컬럼의 내용 확인
df['재입찰'].unique()7. 추정가격 데이터 가져오기
def get_price(df_link):
try:
response = requests.get(df_link)
content_html = BeautifulSoup(response.text)
content = pd.read_html(response.text)
content_list = []
[content_list.append(i) for i in content]
total = pd.concat(content_list, axis = 1, ignore_index = True)
# 추정가격
y1 = 0
for i in total.columns:
if total[i].isin(['추정가격']).any():
y1 = i
break
elif total[i].isin(['추정가격(부가가치세 불포함)']).any():
y1 = i
break
elif total[i].isin(['추정금액']).any(): # 추정가격 혹은 추정가격(부가가치세 불포함) 혹은 추정금액이라고 되어있는 탭이 있기 때문에
y1 = i
break
else:
y1 = None
if y1 == None:
price = '추정가격 관련 내용이 없습니다.' # 테이블에 추정가격 탭이 아예 존재하지 않음
else:
x1 = 0
for j in total.iloc[:,y1]:
if j == '추정가격':
break
elif j == '추정가격(부가가치세 불포함)':
break
elif j == '추정금액': # 추정가격 혹은 추정가격(부가가치세 불포함) 혹은 추정금액이라고 되어있는 탭이 있기 때문에
break
x1 += 1
price = total.iloc[x1, y1+1]
except:
price = '내용없음'
return price함수 실행
from tqdm.notebook import tqdm
tqdm.pandas()
df['추정가격'] = df['내용링크'].progress_map(get_price)- 추정가격 탭이 존재하지 않는 개수 확인
df['추정가격'].tolist().count('추정가격 관련 내용이 없습니다.')- null값인 데이터 확인 후 '추정가격이 공란입니다.' 입력
df.isnull().sum()
df['추정가격'] = df['추정가격'].replace({None : '추정가격이 공란입니다.'}) # 테이블에 추정가격 탭은 있으나 가격이 적혀있지 않음
df8. 컬럼 삭제 및 순서 변경
필요없는 컬럼을 삭제한 후 정해놓은 순서에 맞게 컬럼 순서를 변경해줍니다.
df = df.drop(['공동 수급', '투찰', '내용링크'], axis=1)
cols = ['분류', '업무', '공고번호-차수', '공고명', '공고기관', '수요기관',
'계약방법', '추정가격', '입력일시 (입찰마감일시)', '재입찰']
df_total = df[cols]
df_total9. 데이터 저장
df_total.to_csv('../data/나라장터 크롤링.csv', index=False)10. 데이터 불러오기
데이터가 잘 저장되었는지 확인하기 위해 다시 데이터를 불러옵니다.
result = pd.read_csv('../data/나라장터 크롤링.csv')
result11. 결측값 및 기술통계 확인
- 결측값 확인
result.isnull().sum()- 기술통계 확인
result.describe()12. 시각화
work = result['업무'].value_counts()
work_normalize = result['업무'].value_counts(normalize=True)- 한글 폰트 설정
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'Malgun Gothic'- 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(action='ignore')
work_normalize.plot.pie(figsize=(7,7))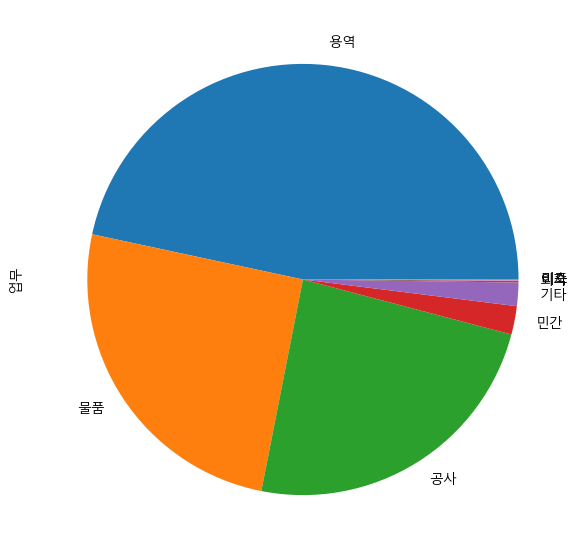
import warnings
warnings.filterwarnings(action='ignore')
a = sns.countplot(data=result, y='업무')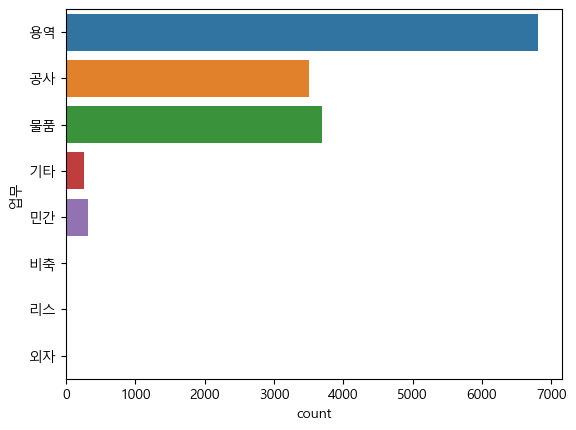
result.loc[result['재입찰'].str.contains('허용'), '재입찰'] = '재입찰 허용'
result.loc[result['재입찰'].str.contains('재입찰 없음|불가'), '재입찰'] = '재입찰 불가'
result['재입찰'].value_counts().plot.bar()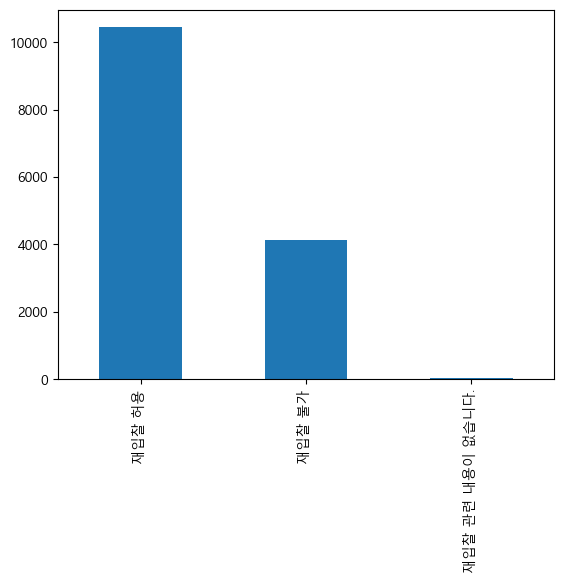

안녕하세요 저도 나라장터 크롤링이 필요해서 적어주신 내용으로 시도해봤는데 엑셀 파일로 다운이 실제 컴퓨터에서는 안되네요 ㅠ 코랩에서 시행중인데 코딩 작동은 문제 없었거든요...
아래 내용 중 뭔가 잘못된게 있는걸까요?
!pip install xlsxwriter
import pandas as pd
import numpy as np
import requests
import os
from bs4 import BeautifulSoup
엑셀 파일 저장 경로
download_path = 'C:\Users\Gram\Downloads\나라장터 웹크롤링.xlsx'
엑셀 파일 저장 옵션
writer = pd.ExcelWriter(download_path, engine='xlsxwriter')
추출한 데이터 프레임
df_total.columns = ['분류', '업무', '공고번호-차수', '공고명', '공고기관', '계약방법', '추정가격', '입력일시 (입찰마감일시)']
데이터 프레임 저장
df_total.to_excel(writer, sheet_name='나라장터 웹크롤링')
엑셀 파일 저장
writer.close()