01. 프로젝트 개요
1) 주제 선정 배경
최근 몇 년 동안 특히 코로나이후 온라인 쇼핑은 더 빠르게 성장하며 많은 소비자들이 패션 상품을 인터넷을 통해 구매하고 있다. 이에 따라 온라인 패션 쇼핑 플랫폼인 무신사 또한 많은 사용자들의 관심과 수요를 받고 있다. 그러나 다양한 스타일, 트렌드, 가격대 등으로 구성된 무수한 제품들 중 사용자 자신에게 적합하고 만족할만한 상품을 선택하는 것은 어렵다. 이런 경험을 해보았기에, 관심있는 제품을 하나 선택하면 그와 비슷한 제품을 추천해주는 시스템을 만들어보고자 했다. 특히 우리는 인기상품에 있는 ‘상의’ 제품 1000개를 이용하여 구현해보았다.
2) 추천시스템 과정
[데이터]
: 상품명/카테고리/브랜드/성별/가격/태그/조회수/리뷰수/평점/구매수/리뷰/인기나이/인기성별
[유사도 계산 및 데이터 활용]
- 텍스트 데이터로 유사도 측정
:태그, 카테고리,리뷰10개 텍스트를 합친 후 TF-IDF로 임베딩 후 코사인 유사도를 이용해 유사도 구한다
- 평점이나 조회수 등을 활용
: 평점, 좋아요 수, 조회수가 높으면 인기있는 제품이므로 점수를 높인다
- 이미지 데이터로 유사도 측정
: 상품 대표 이미지를 resnet50로 임베딩 후 코사인 유사도를 이용해 유사도를 구한다
- 브랜드,인기 나이 및 성별, 가격 데이터 활용
: 브랜드가 같으면 점수를 높이는 식으로 데이터를 활용한다.
[계산식 구성 최종 추천 함수]
1-4를 종합해 적절한 비율로 가중치를 부여해서 체감상 추천 더 잘 되는 공식 짜기
(무신사 자체 추천시스템과 비교 가능)
02. 프로젝트 과정
1) 데이터 수집
데이터는 무신사 홈페이지에서 직접 크롤링 하였다.
카테고리 ‘상의’에서 1000개의 데이터를 수집하였다.
크롤링 순서
- 상품 링크 수집
- 상품명, 카테고리, 브랜드명, 대표 이미지 등 정적 크롤링
- 정적 크롤링이 불가한 항목들 동적 크롤링
상품명, 카테고리, 브랜드와 같은 정보는 정적 데이터로 정적 크롤링이 가능하였으나 좋아요 수, 조회수, 구매수, 인기 나이 및 성별과 같은 데이터는 정적 크롤링으로 수집이 불가능하여 동적 크롤링으로 수집해주었다.
내용 링크 수집
# HTTP 요청
url = 'https://search.musinsa.com/ranking/best?period=week&age=ALL&mainCategory=001&subCategory=&leafCategory=&price=&golf=false&kids=false&newProduct=false&exclusive=false&discount=false&soldOut=false&page=1&viewType=small&priceMin=&priceMax='
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
html = BeautifulSoup(response.text, 'html.parser')# 한 페이지의 링크를 수집하는 함수
def page_scrapping(page_no):
df = pd.DataFrame()
content_link = []
url = f'https://search.musinsa.com/ranking/best?period=week&age=ALL&mainCategory=001&subCategory=&leafCategory=&price=&golf=false&kids=false&newProduct=false&exclusive=false&discount=false&soldOut=false&page={page_no}&viewType=small&priceMin=&priceMax='
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
html = BeautifulSoup(response.text)
for i in html.select('p.list_info > a'):
content_link.append(i['href'])
df["내용링크"] = content_link
return df
# 반복문을 사용하여 전체 페이지 링크 수집
from tqdm import trange
import time
requests.packages.urllib3.disable_warnings(requests.packages.urllib3.exceptions.InsecureRequestWarning)
page_list = []
for i in trange(1,101):
result = page_scrapping(page_no=i)
page_list.append(result)
time.sleep(0.01)# 수집한 데이터 이어붙이기
df = pd.concat(page_list)
df.to_csv('content_link.csv', index=False)
정적 크롤링
import time
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
from tqdm import trange
import requests
import os
requests.packages.urllib3.disable_warnings(requests.packages.urllib3.exceptions.InsecureRequestWarning)
df = pd.read_csv('content_link.csv')# HTTP 요청
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(df['내용링크'].iloc[0], headers=headers)
html = bs(response.text)# 이미지 수집
def download_image(image_url, save_path):
response = requests.get(image_url)
if response.status_code == 200:
with open(save_path, 'wb') as f:
f.write(response.content)
print("이미지 다운로드 성공!")
else:
print("이미지 다운로드 실패.")for i in trange(len(df['내용링크'][:1000])):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(df['내용링크'].iloc[i], headers=headers)
html = bs(response.text)
# 이름
name = html.select('div.right_contents.section_product_summary > span.product_title')[0].text
df.loc[i, '이름'] = name
# 카테고리
try:
category = html.select('div.right_contents.section_product_summary > div.product_info > p > a')[1].text
df.loc[i, '카테고리'] = category
except:
df.loc[i, '카테고리'] = '없음'
# 브랜드 영어
brand = html.select('div#product_order_info > div.explan_product.product_info_section > ul.product_article > li > p.product_article_contents > strong > a')[0].text
df.loc[i, '브랜드'] = brand
# 브랜드 한글
try:
brand_kor = html.select('div.right_contents.section_product_summary > div.product_info > p > a')[2].text.strip()
df.loc[i, '브랜드_한글'] = brand_kor
except:
df.loc[i, '브랜드_한글'] = '없음'
# 성별
try:
a = html.select('div#product_order_info > div.explan_product.product_info_section > ul.product_article > li ')[1]
s = a.select('p > span')[-1].text.strip()
df.loc[i, '성별'] = s
except:
s2 = html.select('div.explan_product.product_info_section > ul.product_article > li > p.product_article_contents > span')[0].text.strip()
df.loc[i, '성별'] = s2
# 평점
try:
rating = html.select('div.explan_product.product_info_section > ul.product_article > li > p > a > span.prd-score__rating')[0].text
df.loc[i, '평점'] = rating
except:
df.loc[i, '평점'] = '없음'
# 리뷰수
try:
review_num = html.select('div.explan_product.product_info_section > ul.product_article > li > p > a > span.prd-score__review-count')[0].text
df.loc[i, '리뷰수'] = review_num
except:
df.loc[i, '리뷰수'] = '없음'
# 태그
tag_list = []
num = html.select('div#product_order_info > div.explan_product.product_info_section > ul.product_article > li.article-tag-list.list > p > a')
for j in num:
tag_list.append(j.text)
tag = ''.join(tag_list)
df.loc[i, '태그'] = tag
# 사진
a = html.select('div#detail_bigimg > div.product-img > img')[0]
image_url = 'https:' + a['src']
save_path = f'경로/{i:04d}.jpg'
download_image(image_url, save_path)
time.sleep(0.01)
df.to_csv('musinsa.csv', index=False)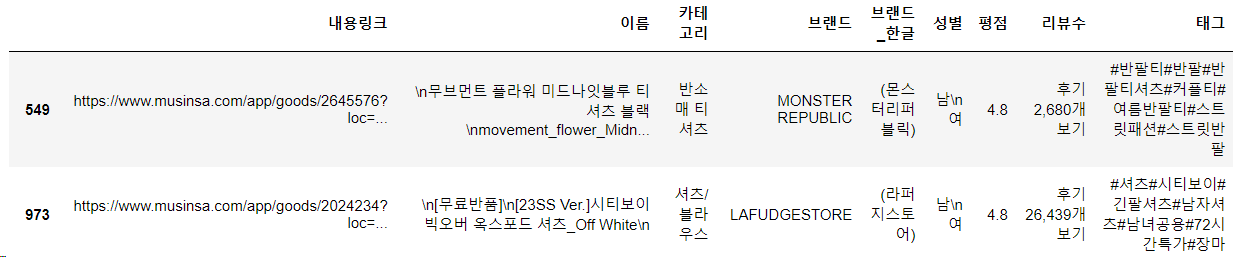
동적 크롤링
import pandas as pd
import numpy as np
from tqdm import trange
import folium
import time
from bs4 import BeautifulSoup
from tqdm import tqdm_notebook
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('./chromedriver')
df = pd.read_csv('musinsa.csv')for i in trange(1000):
URL = df['내용링크'].iloc[i]
driver.get(URL)
time.sleep(1)
# 페이지 전체 HTML 파싱
html = driver.page_source
soup = BeautifulSoup(html,"html.parser")
# 좋아요 수
a = df['내용링크'].iloc[i].split('?')[0].split('/')[-1]
try:
like = driver.find_element(By.CSS_SELECTOR, f'#product-top-like > p.product_article_contents.goods_like_{a} > span').text
df.loc[i, '좋아요 수'] = like
except:
df.loc[i, '좋아요 수'] = '없음'
# 조회수
try:
view = driver.find_element(By.CSS_SELECTOR, '#pageview_1m').text
df.loc[i, '조회수'] = view
except:
df.loc[i, '조회수'] = '없음'
# 구매수
try:
sales = driver.find_element(By.CSS_SELECTOR, '#sales_1y_qty').text
df.loc[i, '구매수'] = sales
except:
df.loc[i, '구매수'] = '없음'
# 인기있는 나이
try:
age = driver.find_element(By.CSS_SELECTOR, '#graph_summary_area > strong:nth-child(2) > em').text
df.loc[i, '인기 나이'] = age
except:
df.loc[i, '인기 나이'] = '없음'
# 인기있는 성별
try:
pop_man = driver.find_element(By.CSS_SELECTOR, '#graph_summary_area > span.man.graph_sex_text').text
df.loc[i, '인기 성별'] = pop_man
except:
try:
pop_woman = driver.find_element(By.CSS_SELECTOR, '#graph_summary_area > span.woman.graph_sex_text').text
df.loc[i, '인기 성별'] = pop_woman
except:
df.loc[i, '인기 성별'] = '없음'
# 가격
try:
price = driver.find_element(By.CSS_SELECTOR, '#list_price').text
df.loc[i, '가격'] = price
except:
df.loc[i, '가격'] = '없음'
# 리뷰 텍스트
for j in range(10):
try:
review = driver.find_element(By.CSS_SELECTOR, f'#reviewListFragment > div:nth-child({j+1}) > div.review-contents > div.review-contents__text').text
df.loc[i, f'리뷰{j+1}'] = review
except:
df.loc[i, f'리뷰{j+1}'] = '없음'최종 데이터프레임 결과는 다음과 같다.

데이터프레임이 중략되어 모든 컬럼이 보이진 않지만 다음과 같은 상품 정보들을 수집했다.



잘 읽었습니다. 좋은 정보 감사드립니다.