
🌝 스트림(Stream)
- 다양한 데이터 소스를 표준화된 방법으로 다루기 위한 것
- 스트림으로 변환(생성)
- 스트림이 제공하는 기능 - 중간 연산과 최종 연산
1 스트림 만들기
2 중간 연산 - 연산결과가 스트림인 연산. 반복적으로 적용가능(0~n번)
3 최종 연산 - 연산결과가 스트림X인 연산. 단 한번만 적용가능(스트림의 요소를 소모) (0~1번)

🌜 스트림(Stream)의 특징
- 스트림은 데이터 소스로부터 데이터를 읽기만할 뿐 변경하지 않음!
.
- 스트림은 Iterator처럼 일회용이다.(필요하면 다시 스트림을 생성해야함)
.
- 최종 연산 전까지 중간연산이 수행되지 않는다. - 지연된 연산
.
- 스트림은 작업을 내부 반복으로 처리한다.
.
- 스트림의 작업을 병렬로 처리 - 병렬스트림
- 기본형 스트림 - IntStream, LongStream, DoubleStream
-> 오토박싱&언박싱의 비효율이 제거됨(Stream<Integer>대신 IntStream사용)
-> 숫자와 관련된 유용한 메서드를Stream<T>보다 더 많이 제공
🌜 1. 스트림 만들기
🌚 컬렉션으로부터 스트림 생성하기
-> Collection인터페이스의 stream()으로 컬렉션을 스트림으로 변환
Stream<E> stream() // Collection인터페이스의 메서드
🌚 객체 배열로부터 스트림 생성하기
Stream<T> STream.of(T...values) // 가변 인자 Stream<T> STream.of(T[]) Stream<T> Arrays.stream(T[]) Stream<T> Arrays.stream(T[] array, int startInclusive, int endExclusive)ex>

🌚 기본형 배열로부터 스트림 생성하기
IntStream intStream.of(int...values) // Stream이 아니라 IntStream IntStream intStream.of(int[]) IntStream Arrays.stream(int[]) IntStream Arrays.stream(int[] array, int startInclusive, int endExclusive)
🌚 난수를 요소로 갖는 스트림 생성하기 - 임의의 수
- 지정된 범위의 난수를 요소로 갖는 스트림을 생성하는 메서드(Random클래스)



🌚 특정 범위의 정수를 요소로 갖는 스트림 생성하기(intStream, LongStream)
IntStream IntStream.range(int begin, int end) IntStream IntStream.rangeClosed(int begin, int end) // 끝이 포함
🌚 람다식을 소스로 하는 스트림 생성하기
- iterate()는 이전 요소를 seed(초기값)로 해서 다음 요소를 계산한다.
Stream<Integer> evenStream = Stream.iterate(0, n->n+2); // 0, 2, 4, 6, ...- generate()는 seed를 사용안함
Stream<Double> randomStream = Stream.generate(Math::ramdom); Stream<Integer> oneStream = Stream.generate(()->1);

🌚 파일과 빈 스트림
- 파일을 소스로 하는 스트림 생성하기
Stream<Path> Files.list(Path dir) // Path는 파일 또는 디렉토리Stream<String> Files.lines(Path path) Stream<String> Files.lines(Path path, Charset cs) Stream<String> lines() // BufferedReader클래스의 메서드
- 비어있는 스트림 생성하기
Stream emptyStream = Stream.empty(); // empty()는 빈 스트림을 생성해서 반환 long count = emptyStream.count(); // count의 값은 0
🌜 2. 중간연산
🌚 스트림 자르기 - skip(), limit()
Stream<T> skip(long n) // 앞에서부터 n개 건너뛰기 Stream<T> limit(long maxSize) // maxSize 이후의 요소는 잘라냄 ex> IntStream intStream = IntStream.rangeClosed(1,10); // 12345678910. rangeClosed -> 마지막숫자 포함 intStream.skip(3).limit(5).forEach(System.out::print); // 45678🌚 스트림의 요소 걸러내기 - filter(), distinct()
Stream<T> filter(Predicate<? super T> predicate) // 조건에 맞지 않는 요소 제거 Stream<T> distinct() // 중복제거 ex> distinct() IntStream intStream = IntStream.of(1,2,2,3,3,3,4,5,5,6); IntStream.distinct().forEach(System.out::print); // 123456 ex1> filter() IntStream intStream = IntStream.rangeClosed(1,10); // 12345678910 intStream.filter(i-> i%2==0).forEach(System.out::print); // 246810 ex2> filter() intStream.filter(i-> i%2!=0 && i%3!=0).forEach(System.out::print); intStream.filter(i-> i%2!=0).filter(i-> i%3!=0).forEach(System.out::print);🌚 스트림 정렬하기 - sorted()
Stream<T> sorted() // 스트림 요소의 기본 정렬(Comparable)로 정렬 Stream<T> sorter(Comparator<? super T> comparator) // 지정된 Comparator로 정렬
🌚 스트림의 요소 변환하기 - map()
Stream<R> map(Function<? super T, ? extends R> mapper) // Stream<T> -> Stream<R>
🌚 스트림의 요소를 소비하지 않고 엿보기 - peek()
중간 작업 결과 확인할 때
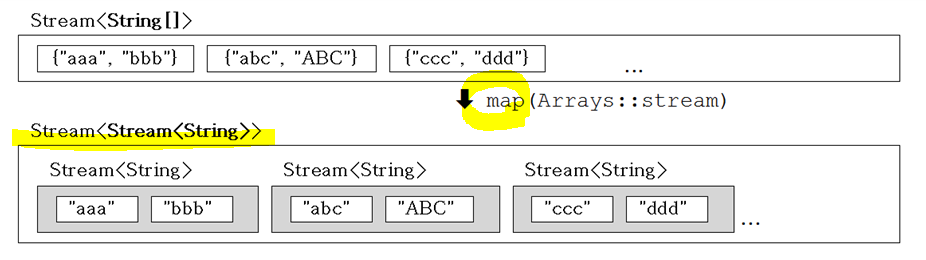
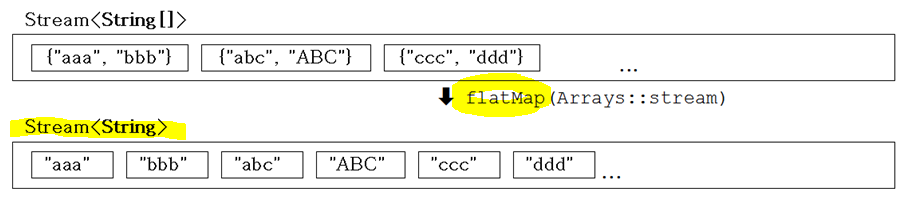
Stream<T> peek(Consumer<? super T> action) // 중간 연산(스트림을 소비X) void forEach(Consumer<? super T> action) // 최종 연산(스트림 소비O)🌚 스트림의 스트림을 스트림으로 변환 - flatMap()
ex> Stream<String[]> strArrStrm = Stream.of(new String[] {"abc", "def", "ghi"}, new String[] {"ABC", "GHI", "JKLMN"});// map()으로 변환했을때, 스트림의 스트림이 됨 Stream<Stream<String>> strStrStrm = strArrStrm.map(Arrays::stream);
// flatMap() Stream<String> strStrStrm = strArrStrm.flatMap(Arrays::stream); // Arrays.stream(T[])



🌜 Optional< T >
- T 타입 객체의 래퍼클래스 - Optional< T >
public final class Optional<T>{ private final T value; // T타입의 참조변수 // T value에 모든 타입 객체 저장 가능 ... }
🌚 Optional< T > 객체 생성하기
- Optional< T >객체를 생성하는 다양한 방법
String str = "abc"; Optional<String> optVal = Optional.of(str); Optional<String> optVal = Optional.of("abc"); Optional<String> optVal = Optional.of(null); // NullPointerExceptoin발생 Optional<String> optVal = Optional.ofNullable(null); // Ok
- null대신 빈 Optional< T >객체를 사용하자
Optional<String> optVal = null; // 널로 초기화. 바람직X Optional<String> optVal = Optional.<String>empty(); // 빈 객체로 초기화 // <String> 생략가능
🌚 Optional< T > 객체의 값 가져오기
- Optional객체의 값 가져오기 - get(), orElse(), orElseGet(), orElseThrow()
Optional<String> optVal = Optional.of("abc"); String str1 = optVal.get(); // optVal에 저장된 값을 반환. null이면 예외발생 String str2 = optVal.orElse(""); // optVal에 저장된 값이 null일 때는, ""를 반환 String str3 = optVal.orElseGet(String::new); // 람다식 사용가능 () -> new String() String str4 = optVal.orElseThrow(NullPointerException::new); // 널이면 예외발생
- isPresent() - Optional객체의 값이 null이면 false, 아니면 true를 반환
if(Optional.ofNullable(str).isPresent()) { // if(str!=null) { System.out.println(str); --> // ifPresent(Consumer) - 널이 아닐때만 작업 수행, 널이면 아무일 안함 Optional.ofNullable(str).ifPresent(System.out::println); }
🌜 OptionalInt, OptionalLong, OptionalDouble
- 기본형 값을 감싸는 래퍼클래스
- 성능 높일때
public final class OptionalInt{ ... private final boolean isPresent; // 값이 저징되어 있으면 true private final int value; // int타입의 변수 }
- OptionalInt의 값 가져오기 - int getAsInt()
- 빈 Optional객체와의 비교
OptionalInt opt = OptionalInt.of(0); // OptionalInt에 0을 저장 OptionalInt opt2 = OptionalInt.empty(); // OptionalInt에 0을 저장 . System.out.println(opt.isPresent()); // true System.out.println(opt2.isPresent()); // false System.out.println(opt.equals(opt2)); // false

🌜 3. 최종연산
🌚 스트림의 모든 요소에 지정된 작업을 수행 - forEach(), forEachOrdered()
void forEach(Consumer<? super T> action) // 병렬스트림인 경우 순서가 보장되지 않음
void forEachOrdered(Consumer<? super T> action) // 병렬스트림인 경우에도 순서가 보장됨>>>> ex <<<<< // sequential() - 직렬스트림 IntStream.range(1,10).sequential().forEach(System.out::print); // 123456789 IntStream.range(1,10).sequential().forEachOrdered(System.out::print); // 123456789 // parallel() - 병렬스트림: 여러 쓰레드 나눠서 작업 IntStream.range(1,10).parallel().forEach(System.out::print); // 683295717 IntStream.range(1,10).parallel().forEachOrdered(System.out::print); // 123456789🌚 조건 검사 - allMatch(), anyMatch(), noneMatch()
boolean allMatch(Predicate<? super T> predicate) // 모든 요소가 조건을 만족시키면 true
boolean anyMatch(Predicate<? super T> predicate) // 한 요소라도 조건을 만족시키면 true
boolean noneMatch(Predicate<? super T> predicate) // 모든 요소가 조건을 만족시키지않으면 true🌚 조건에 일치하는 요소 찾기 - findFirst(), findAny()
Optional< T > findFirst() // 첫 번째 요소를 반환. 순차 스트림에 사용
Optional< T > findAny() // 아무거나 하나를 반환. 병렬 스트림에 사용>>>> ex <<<<< Optional<Student> result = stuStream.filter(s -> s.getTotalScore() <= 100).findFirst(); Optional<Student> result = paralleStream.filter(s -> s.getTotalScore() <= 100).findAny();⭐🌚 스트림의 요소를 하나씩 줄여가며 누적연산 수행 - reduce()
Optional<T> reduce(BinaryOperator<T> accumulator) T reduce(T identity, BinaryOperator<T> accumulator) // 위와 같음 // identity - 초기값 // accumulator - 병렬처리된 결과를 합치는데 사용할 연산(병렬 스트림)// int reduce(int identity, IntBinaryOperator op) int count = intStream.reduce(0, (a,b) -> a + 1); // count() int sum = intStream.reduce(0, (a,b) -> a + b); // sum() int max = intStream.reduce(Integer.MIN_VALUE, (a,b)-> a > b ? a : b); // max() int min = intStream.reduce(Integer.MAX_VALUE, (a,b)-> a < b ? a : b); // min() /* int a = identity; for(int b : stream) a = a + b; // sum() */
🌜 collect()와 Collectors
collect() - 최종연산, collector - 인터페이스, Collectors - 클래스(collector를 구현)
🌚 collect()는 Collectors를 매개변수로 하는 스트림의 최종연산
Object collect(Collector collector) // Collector를 구현한 클래스의 객체를 매개변수로. Object collect(Supplier supplier, BiConsumer accumulator, BiConsumer combiner) // 잘 안쓰임🌚 Collector는 수집(collect)에 필요한 메서드를 정의해 놓은 인터페이스
public interface Collector<T, A, R> { // T(요소)를 A에 누적한 다음, 결과를 R로 변환해서 반환 Supplier<A> supplier(); // StringBuilder::new 누적할 곳 BiConsumer<A, T> accumulator(); // (sb, s) -> sb.append(s) 누적방법 BinaryOperaor<A> combiner(); // 결합방법(병렬) Function<A, R> finisher(); // 최종변환 Set<Characteristics> characteristics(); // 컬렉터의 특성이 담긴 Set을 반환 ... }🌚 Collectors클래스는 다양한 기능의 컬렉터(Collector를 구현한 클래스)를 제공
- 변환 - mapping(), toList(), toSet(), toMap(), toCollection(), ...
- 통계 - counting(), summingInt(), averagingInt(), maxBy(), summarizingInt(), ...
- 문자열 결합 - joining()
- 리듀싱 - reducing()
- 그룹화와 분할 - groupingBy(), partitioningBy(), collectingAndThen()
🌝 Collectors
🌛 스트림을 컬렉션, 배열로 변환
🌚 스트림을 컬렉션으로 변환 - toList(), toSet(), toMap(), toCollection()
// 학생 이름이 담긴 List가 됨. List<String> names = stuStream.map(Student::getName) // Stream<Student> -> Stream<String> .collect(Collectors.toList()); // Stream<String> -> List<String> ArrayList<String> list = names.stream() .collecet(Collectors.toCollection(ArrayList::new)); // Stream<String> -> ArrayList<String> // map(key, value) Map<String, Person> map = personStream .collect(Collectors.toMap(p -> p.getRegId(), p -> p)); // Stream<Person> -> Map<String, Person>🌚 스트림을 배열로 변환 - toArray()
Student[] stuNames = studentStream.toArray(Student[]::new); // Ok Student[] stuNames = studentStream.toArray(); // 에러!! Object[] stuNames = studentStream.toArray(); // Ok
🌛 스트림의 통계 - counting(), summingInt()
🌚 스트림의 통계정보 제공 - counting(), summingInt(), maxBy(), minBy(), ..
long count = stuStream.count(); // 스트림의 모든 요소를 카운트 long count = stuStream.collect(counting()); // 나눠서 카운트 가능long totalScore = stuStream.mapToInt(Student::getTotalScore).sum(); // IntStream의 sum() long totalScore = stuStream.collect(summingInt(Student::getTotalScore));OptionalInt topScore = studentStram.mapToInt(Student::getTotalScore).max(); // 전체 요소중 최댓값 Optional<Student> topStudent = stuStream .max(Comparator.comparingInt(Student::getTotalScore)); Optional<Student> topStudent = stuStream .collect(maxBy(Comparator.comparingInt(Student::getTotalScore));
🌛 스트림을 리듀싱 - reducing()
🌚 스트림을 리듀싱 - reducing()
Collector reducing(BinaryOperator<T> op) Collector reducing(T identity, BinaryOperator<T> op) Collector reducing(U identity, Function<T,U> mapper, BinaryOperator<U> op) // map+reduce // 변환 작업시IntStream intStream = new Random().ints(1, 46).distinct().limit(6); . OptionalInt max = intStream.reduce(Integer::max); // 전체 리듀싱 OptionalInt<Integer> max = intStream.boxed().collect(reducing(Integer::max)); // 그룹별 리듀싱 가능long sum = intStream.reduce(0, (a,b) -> a + b); long sum = intStream.boxed().collect(reducing(0, (a,b) -> a +b));
🌛 문자열 스트림의 요소를 모두 연결 - joining()
String studentNames = stuStream.map(Student::getName).collect(joining());
String studentNames = stuStream.map(Student::getName).collect(joining(",")); // 구분자
String studentNames = stuStream.map(Student::getName).collect(joining(",", "[", "]"));🌜 스트림의 그룹화와 분할
- (Collectors.)partitioningBy()는 스트림을 2분할한다.
Collector partitioningBy(Predicate predicate) Collector partitioningBy(Predicate predicate, Collector downstream)Map<Boolean, List<Student>> stuBySex = stuStream .collect(patitioningBy(Student::isMale); // 학생들을 성별로 분할 List<Student> maleStudent = stuBySex.get(true); // Map에서 남학생목록을 얻음 List<Student> femaleStudent = stuBySex.get(false); // Map에서 여학생목록을 얻음Map<Boolean, List<Student>> stuNumBySex = stuStream .collect(patitioningBy(Student::isMale, counting()); // 분할 + 통계 System.out.println("남학생 수 :" + stuNumBySex.get(true)); // 남학생 수: 8 System.out.println("여학생 수 :" + stuNumBySex.get(false)); // 여학생 수: 10
- (Collectors.)groupingBy()는 스트림을 n분할한다.
Collector groupingBy(Function classifier) Collector groupingBy(Function classifier, Collector downstream) Collector groupingBy(Function classifier, Supplier mapFactory, Collector downstream)Map<Integer, List<Student>> stuByBan = stuStream // 학생을 반별로 그룹화 .collect(groupingBy(Student::getBan, toList())); // toList() 생략가능Map<Integer, Map<Integer, List<Student>>> stuByHakAndBan = stuStream // 다중 그룹화 .collect(groupingBy(Student::getHak, // 1. 학년별 그룹화 groupingBy(Student::getBan) // 2. 반별 그룹화 ));
🌝 출처
자바의 정석 책 & 유튜브https://www.youtube.com/user/MasterNKS
