distinct는 집합에서 값을 UNIQUE하게 만들어서 값을 조회한다.
group by는 count max min 등의 집계함수를 사용할 수 있게 집합에서 값을 UNIQUE하게 만들어서 값을 조회한다.
distinct

위와 같이 컬럼 앞에 distinct를 써서 쓸수 있다.
distinct는 정렬된 결과 값을 배출하지 않기 때문에 정렬된 결과를 원한다면 order by를 써야된다.
.jpg)
위와 같이 HASH UNIQUE 실행계획이 나온다.
10G이상에서는 sort unique보다는 hash unique가 선호돼서 위와 같은 실행계획이 나온다.
group by
.jpg)
from 아래 줄에 group by 를 써서 사용할 수 있다.
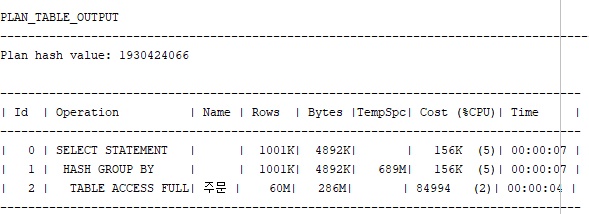
group by 를 쓰면 HASH GROUP BY 라는 실행계획이 나오고
10G이상에서 HASH GROUP BY 가 선호되는 이유와 비슷하다고 생각한다.
GROUP BY 는 정렬된 결과를 보장해 주지 않는다.
그렇기에 항상 정렬된 집합을 원한다면 order by절을 통하여 정렬된 결과를 얻어야한다.
order by, group by WITH order by
distinct

.jpg)
order by 와 함께 작성한다면 SORT UNIQUE 실행계획이 나온다는 점을 알 수 있다. COST는 342K가 나왔다는 점을 기억하자.
group by
.jpg)
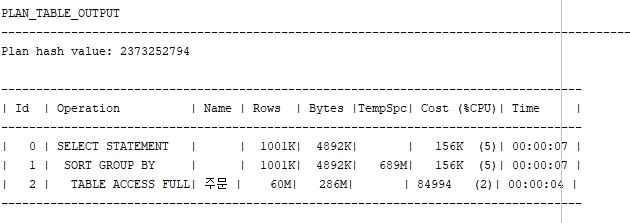
ORDER BY 와 함께 작성한다면 SORT GROUP BY 실행계획이 나온다는 점을 알 수 있다. COST는 156K가 나왔다.
위의 두 SQL을 같은 결과가 반환되지만 COST면에서는
DISTINCT 342K
GROUP BY 156K
두 배보다 더 차이난다.
그렇기에 UNIQUE한 집합을 반환할때는 DISTINCT보다 GROUP BY를 쓰는 것을 권장한다.
요약
공통점
- 유니크하게 집합을 반환한다.
- 정렬된 결과를 보장하지 않는다.
차이점
- 실행계획이 UNIQUE, GROUP BY 로 다르게 나온다.
- ORDER BY가 들어갈 경우 COST가 현저하게 차이난다.
- GROUP BY는 집계 함수를 사용할 수 있다.
